
资料下载


硬件即代码第五部分:FPGA内部
陈键
分享资料个
描述
我对本教程采用了快速入门的方法,即尽早开始编写代码。编写代码不需要对 FPGA 了解太多,就像你为 CPU 编写软件而没有真正了解 CPU 的细节一样。但是,FPGA 是一种资源受限的设备,在某些时候您会想了解这些资源是什么以及如何测量它们。今天,我们将仔细研究 FPGA 的组成部分,以便您可以做到这一点。
如果您是本系列的新手,您可能想回到硬件即代码第 I 部分。
FPGA 元素
让我们首先介绍 FPGA 内部的主要元素。
可编程逻辑- 这是 FPGA 中可用的主要和最丰富的资源。正如我在第一部分中所描述的,数字逻辑由逻辑门(与、或、非等)组成,该逻辑可用于实现算术运算,以及计算机所做的一切。可编程逻辑元件通常称为 LE(逻辑元件)或 LUT。在最大的 FPGA 中,LE 容量可以从数百到超过一百万不等。
寄存器- (非数组)变量的值存储在由称为触发器的硬件元素组成的寄存器中。每个触发器(或只是 FF)存储一个位值,因此 8 位变量将在硬件中使用 8 个 FF。每个 LE 通常有一个或两个 FF 配对,因此触发器容量通常与 LE 的顺序相同。
DSP 模块——所谓的“数字信号处理”模块主要由一个硬编码(即固定功能,不可编程)乘法器和一个加法器组成。有几种变体,但乘法器 + 加法器是所有变体共有的关键功能。尽管这两者都可以纯粹在可编程逻辑中实现,但 DSP 模块的效率要高得多,而且它们对许多应用非常重要。DSP 块数范围从 10 以下到 1000 以上。
如果没有足够的 DSP 模块可用,综合工具将为乘法器和加法器使用可编程逻辑。这对于加法器来说很常见,虽然效率较低,但它们仍然相当有效。另一方面,乘法器作为可编程逻辑非常浪费,如果您需要许多乘法器超出可用 DSP 模块的数量,您可能会发现自己很快就会耗尽空间。
嵌入式 RAM - 我们在第四部分详细介绍了嵌入式 RAM。这些元素通常被称为 EBR(嵌入式 RAM)、块 RAM 或 BRAM。每个嵌入式 RAM 的容量通常以数千位为单位。嵌入式 RAM 的数量可能从几万到几千不等。一些 FPGA 在同一个 FPGA 中也有多种尺寸。例如,许多较小的 RAM 和一些大型 RAM。
I/O - 这些重要的元件使用芯片的外部引脚提供输入和输出。在本系列中,我们不会过多担心这些,因为我们将始终使用 HLS 工具中内置的预先设计的块,将我们的设计与外部世界连接起来。但是,只是为了完整性... I/O 元素包括通用 I/O(或 GPIO),可以驱动具有高/低输出值的引脚或读取高/低输入值。除了 GPIO,FPGA 通常还提供其他固定功能 I/O 元件,这些元件可以使用 DDR、SPI、I2C、PCIe 等特定协议与外部设备进行通信。
FPGA 规格
几乎所有 FPGA 供应商都提供不同系列的 FPGA,它们针对不同类别的应用,称为器件系列。每个系列将包括几个不同尺寸的部件(无论是在物理上还是在可用资源方面)、封装和特殊功能。当您访问设备系列的网站时,页面上或附件中将有一个系列表,其中总结了系列中每个设备的可用资源。
这是我们正在使用的 UPDuino 板上 FPGA 的族表:
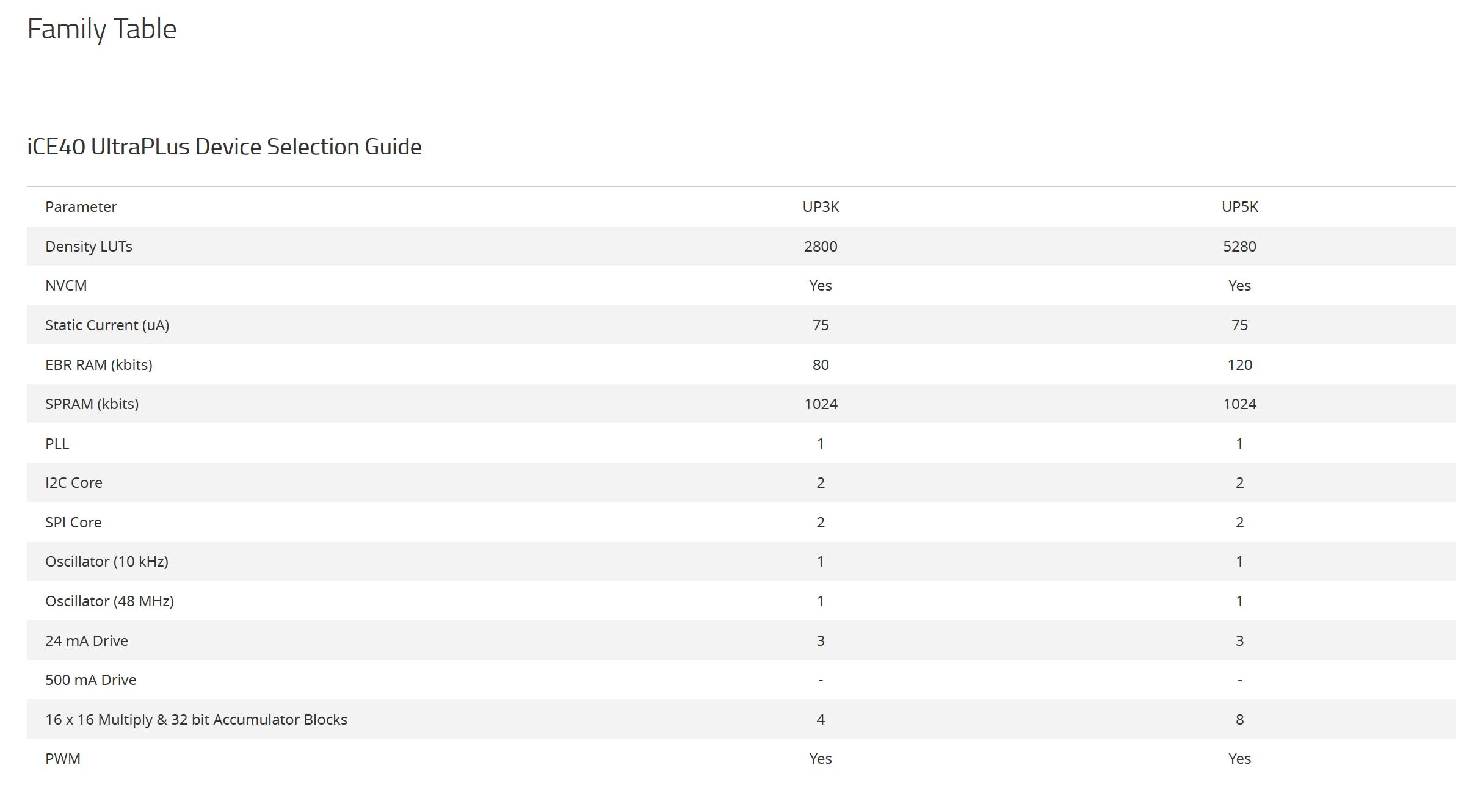
希望您现在可以确定我们感兴趣的 4 个主要资源(实际上是 3 个,因为缺少一个)。UPDuino 包含一个 UP5K 设备(第二列),因此我们的开发板有以下资源:
- 可编程逻辑:5、280个元素(表中的LUT)
- 寄存器:未明确给出,但假设类似于 LUT 计数(数据表将提供更多详细信息。)
- 嵌入式 RAM:120Kb(这是总位容量。数据表将详细说明各个块的数量和大小。)
- DSP 块:8 个(表中的乘法和累加器块)
作为奖励,这些芯片有一些更大的块 RAM(表中的 SPRAM)。
即使您不了解文档其余部分的大部分内容,通常也值得查看数据表的前几页。在概述之后,通常会有一个比您在网站上找到的更详细的家庭表。
查看 UP5K 设备的数据表(下载数据表),我们发现它有 30 个嵌入式 RAM,每个 4096 位 (30 * 4Kb = 120Kb),以及 4 个 256Kb (4 * 256Kb = 1Mb) 的大 RAM 块。
路由(隐藏资源)
在将设计映射到数字逻辑(和 DSP 模块等)之后,工具必须在芯片上布局这些元素。在几何上不可能以一种一切都与它们所连接的事物直接相邻的方式来布局设计。因此,存在“路由”资源,这些资源基本上是电线和可编程开关,允许连接芯片的不同部分。
不幸的是,这是一种难以定量描述的资源。因此,您不会在 FPGA 规范中看到任何数字来描述可用的布线(不过,数据表可能会有对布线架构的描述),并且工具很少或根本没有关于设计布线多少的输出正在利用。充其量,您可能会看到这样的警告,例如这种设计具有高度拥塞。
在实践中,布线并不是您会直接担心的事情,但它会影响最大可实现的芯片容量。未使用的逻辑和其他元素越多,布局的灵活性就越大,工具就越有可能找到可行的布局。反过来说,您使用的资源百分比越高,布局的灵活性就越小,工具就越有可能无法找到可行的布局。
我发现一旦 FPGA 的利用率达到 70-75%,这些工具可能会在布局期间开始出现问题。一旦达到 80% 或更多,您可能会遇到彻底的失败。这只是我的经验,YMMV。此时,简单的解决方案是升级到更大的 FPGA。可以做一些事情来突破设备利用率的极限,但这些事情超出了本系列的水平,需要数字硬件设计师的帮助。
资源使用报告
现在您至少了解了最重要的感兴趣的资源,我们现在可以查看工具报告,告诉我们我们的设计正在使用多少资源。当您单击上传按钮构建您的设计并将其上传到 FPGA 时,您会看到大量信息飞过,包括资源使用信息。您也可以运行这些工具,而无需使用以下命令实际上传到 UPDuino 板:(pio run --target bitstream如果之前构建了比特流,您可能需要先清理项目)。
工具完成后,向后滚动几页,直到看到如下所示的表格:
Info: Device utilisation:
Info: ICESTORM_LC: 544/ 5280 10%
Info: ICESTORM_RAM: 0/ 30 0%
Info: SB_IO: 6/ 96 6%
Info: SB_GB: 4/ 8 50%
Info: ICESTORM_PLL: 0/ 1 0%
Info: SB_WARMBOOT: 0/ 1 0%
Info: ICESTORM_DSP: 1/ 8 12%
Info: ICESTORM_HFOSC: 1/ 1 100%
Info: ICESTORM_LFOSC: 0/ 1 0%
Info: SB_I2C: 0/ 2 0%
Info: SB_SPI: 0/ 2 0%
Info: IO_I3C: 0/ 2 0%
Info: SB_LEDDA_IP: 0/ 1 0%
Info: SB_RGBA_DRV: 0/ 1 0%
Info: ICESTORM_SPRAM: 0/ 4 0%
这是布局工具的输出。第一行使用另一个术语来表示逻辑元件:LC(逻辑单元),即 LUT + FF。之后是嵌入式 RAM,再往下是 DSP。
这个实际输出来自我们在第二部分的第一个示例:Hello FPGA。这种设计只使用了 10% 的 LE 资源,因此有足够的空间来做更多的事情。事实上,这 10% 的大部分实际上是由工具产生的开销,用于将你的函数连接到 USB,因此我们可以从计算机调用它。
要进行实验,请使用我们介绍过的任何示例,并尝试对代码进行各种更改,以查看此使用情况报告表如何更改。5K 并不多,但我已经使用此设备构建了许多复杂的应用程序,例如唤醒词检测和图像分类。
感知器挑战
在第四部分中,我要求您修改多类感知器示例以并行计算 3 个输出。这是该问题的解决方案:
// Multi-class perceptron is a matrix/vector multiplication
void mat_vec_mul(in_array,4> features, out_array,4> out) {
int16_t coef0[4] = { -9, 25, -28, -27 };
int16_t coef1[4] = { -3, -31, 58, -31 };
int16_t coef2[4] = { -10, 4, 80, 79 };
int16_t acc0 = 0;
int16_t acc1 = 0;
int16_t acc2 = 0;
for (uint8_t j = 0; j < 4; j++) {
int16_t x = features[j];
acc0 += coef0[j] * x;
acc1 += coef1[j] * x;
acc2 += coef2[j] * x;
}
out.resize(3); // set the actual output size
out[0] = acc0;
out[1] = acc1;
out[2] = acc2;
}
解决方案的关键是利用每个嵌入式 RAM 以及数组变量可以同时并行访问这一事实。通过将coef 变量拆分为三个单独的变量并展开外部循环,我们可以使每个输出的乘法和累加步骤并行发生。如果我们展开了循环,但没有拆分coef,那么工具链仍然会为三个乘法和加法语句生成单独的硬件,但它们需要轮流从coef 数组中获取值而不是实际执行在平行下。如所写,上述循环每次迭代将使用 2 个周期:一个用于读取数组,一个用于执行乘法和累加。几周后,我们将了解如何将其进一步改进为每次迭代 1 个周期。
这是此示例的资源使用情况:
Info: Device utilisation:
Info: ICESTORM_LC: 686/ 5280 12%
Info: ICESTORM_RAM: 2/ 30 6%
Info: SB_IO: 6/ 96 6%
Info: SB_GB: 8/ 8 100%
Info: ICESTORM_PLL: 0/ 1 0%
Info: SB_WARMBOOT: 0/ 1 0%
Info: ICESTORM_DSP: 3/ 8 37%
Info: ICESTORM_HFOSC: 1/ 1 100%
Info: ICESTORM_LFOSC: 0/ 1 0%
Info: SB_I2C: 0/ 2 0%
Info: SB_SPI: 0/ 2 0%
Info: IO_I3C: 0/ 2 0%
Info: SB_LEDDA_IP: 0/ 1 0%
Info: SB_RGBA_DRV: 0/ 1 0%
Info: ICESTORM_SPRAM: 0/ 4 0%
正如预期的那样,此设计使用 3 个 DSP 模块,每个输出一个。但是,您可能想知道为什么只使用了 2 个嵌入式 RAM 块,尽管该函数使用了 5 个数组。在某些情况下,如果数组非常小,综合工具可能会使用触发器来存储数组数据,而不是使用嵌入式 RAM。这里的系数数组总共只有 64 位,将其存储在 4096 RAM 中会有些浪费。
下一步
本教程系列的前半部分到此结束,我希望您现在对如何使用 C++ 创建自定义 FPGA 设计有一个基本概念。但是,还有很多东西要学!接下来,我们将讨论另一个性能优化主题:如何消除(或至少隐藏)I/O 开销。
连接
在我发布新的分期付款时,请关注我以保持最新状态。还有一个 Discord 服务器(公共聊天平台),用于您在https://discord.gg/3sA7FHayGH上可能有的任何评论、问题或讨论
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章





