
资料下载


Arduino上的英特尔数学内核库
郭中
分享资料个
描述
在本教程中,我们将学习如何将您的草图与超级优化的英特尔库集成以进行大量数学计算(朋友的 MKL)。
首先,您需要一个合适的物联网网关,有几个可用的 GB 硬盘空间(库有时可能很重)。按照 Create 的 Getting Started 部分启动并运行您的 Gateway(例如,选择 Ubuntu 发行版)。
为什么我需要这么大的空间
(又名:我如何学会爱上共享库)
在 Arduino 世界中,库是帮助您与特定硬件交互或执行特定操作的代码集合。
在 Linux 上,一个库具有相同的属性,但可以在多个程序之间共享。这可以节省大量空间,因为它们包含的功能可以被不同的进程免费使用。
设置董事会
库通常通过包管理器或使用安装程序提供(我们将在本例中使用后一种)。首先,使用您在安装过程中提供的 IP 地址和用户名/密码,通过 ssh 访问您的开发板。为此,您可以使用 Putty(如果您在 Windows 上)或串行终端。端口必须设置为 22 才能使 SSH 登录正常工作。
现在我们需要下载 MKL 包。打开浏览器并访问https://software.intel.com/en-us/mkl ,点击“免费下载”并完成注册过程。选择“Intel Performance Libraries for Linux”并右键单击“Intel Math Kernel Library”,选择“Copy link address”(或类似的,取决于您的浏览器)。
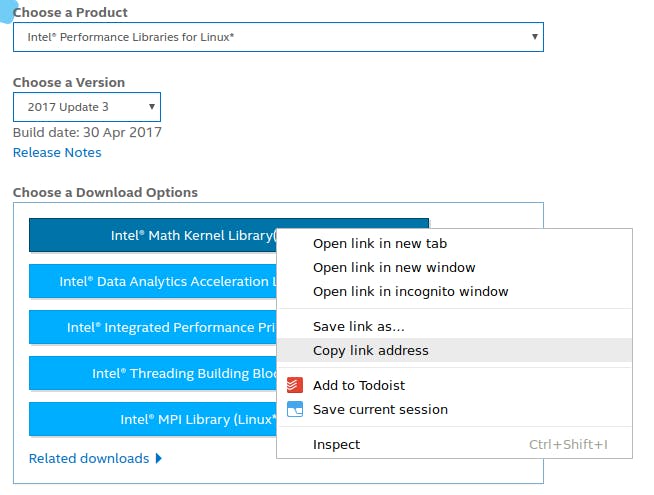
现在重新打开 SSH shell,输入:
wget
并粘贴您刚刚复制的链接。按 [Enter] 并开始下载。下载后,通过键入以下内容提取包:
tar xvf l_mkl_2017*
让我们cd 进入解压文件夹(通常与下载的包同名,不带扩展名)并输入:
./install.sh
按照屏幕上的说明进行操作,几分钟后您的系统将准备就绪。
是时候编码了!
使用提供的示例打开创建。我们将演示 MKL 库的一个非常方便的功能,它有助于并行化代码执行,而无需担心线程或类似问题。
在示例中,使用MKL 中包含的优化函数执行矩阵乘法。cblas_dgemm该功能针对各种 Intel 硬件平台进行了优化,使用目标 CPU(AVX、SSE4 等)上可用的最新矢量化功能。
但是如果我们有一个多核架构会发生什么呢?我们正在失去很多功能,因为函数只在线程上运行,即使它必须解决的问题可以“拆分”成多个更小的问题,因此它是并行化的完美候选者。
使用 mkl_set_num_threads 我们可以指示库在多个线程(和内核)上运行,而无需额外的编程工作。
该示例使用多个线程数执行相同的计算,从 1 到目标 CPU 的内核数(如果 HyperThreading 处于活动状态,可能会加倍)并对各种运行进行基准测试。
让我们释放怪物
准备就绪后,打开左侧面板上的监视器,按“上传”并等待几秒钟以开始上传和草图。程序的输出将打印在监视器上。
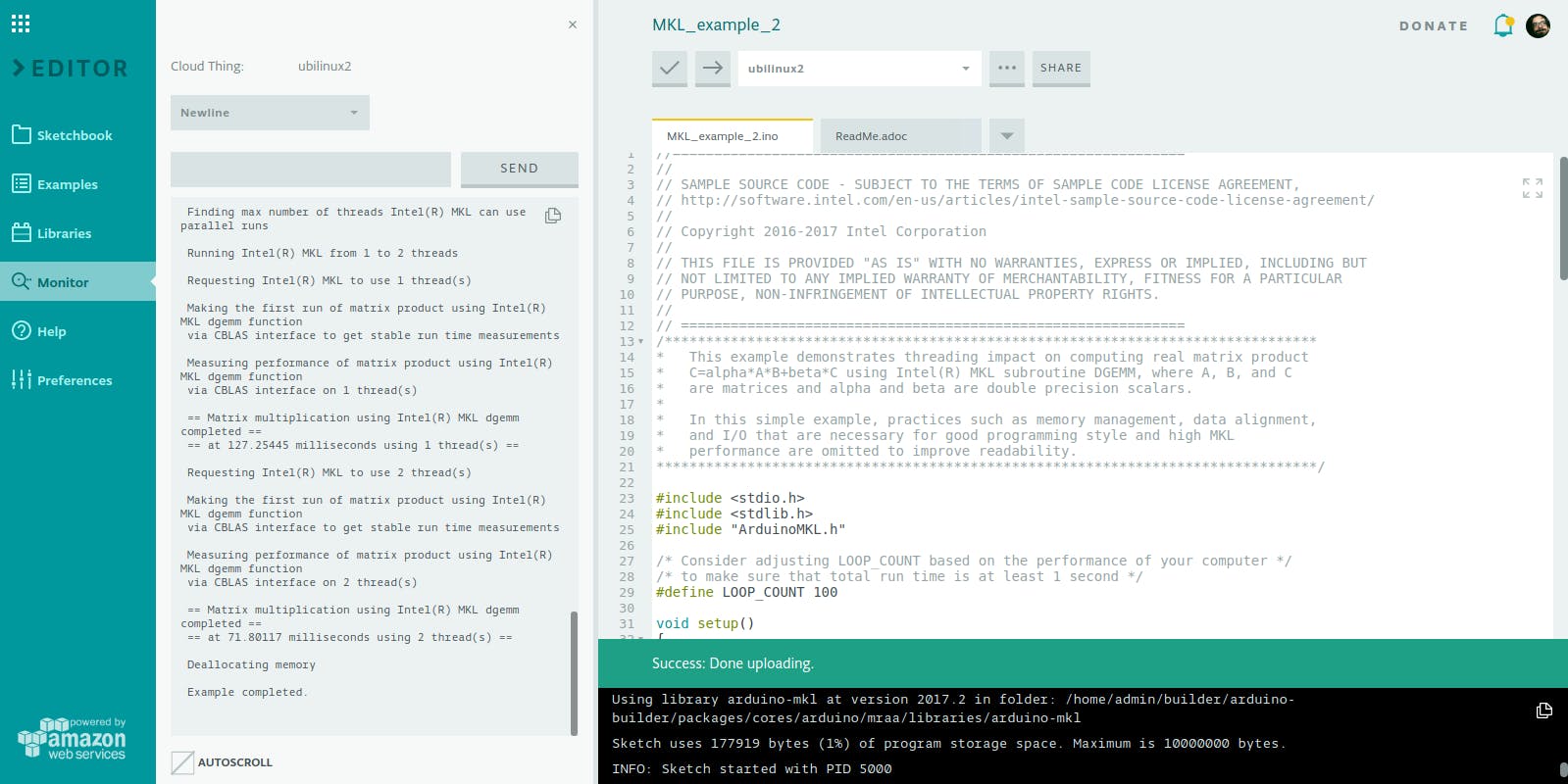
我们学到了什么?
如果我们看一下结果,与单线程相比,在两个线程上执行将带来几乎两倍的性能(当然是在双核处理器上)。性能影响并不完全是x2 因为在启动任何额外线程时会有一点开销,只要执行时间很短,这种惩罚就会变得更大。如果大部分时间都花在处理数字上,那么加速比接近理论最大值。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章




