
资料下载


描述性人工智能相机的构建
分享资料个
描述
在这个项目中,我们将构建一个自动描述它观察到的内容的相机。将部署在 Jetson Nano 等边缘设备上运行的 AI 网络,以便它持续提供所获取帧的文本描述。为了保持实现简单,虽然可以将注意力等高级功能添加到网络中,但由于主脚本是相当模块化的,所以没有实现它们。
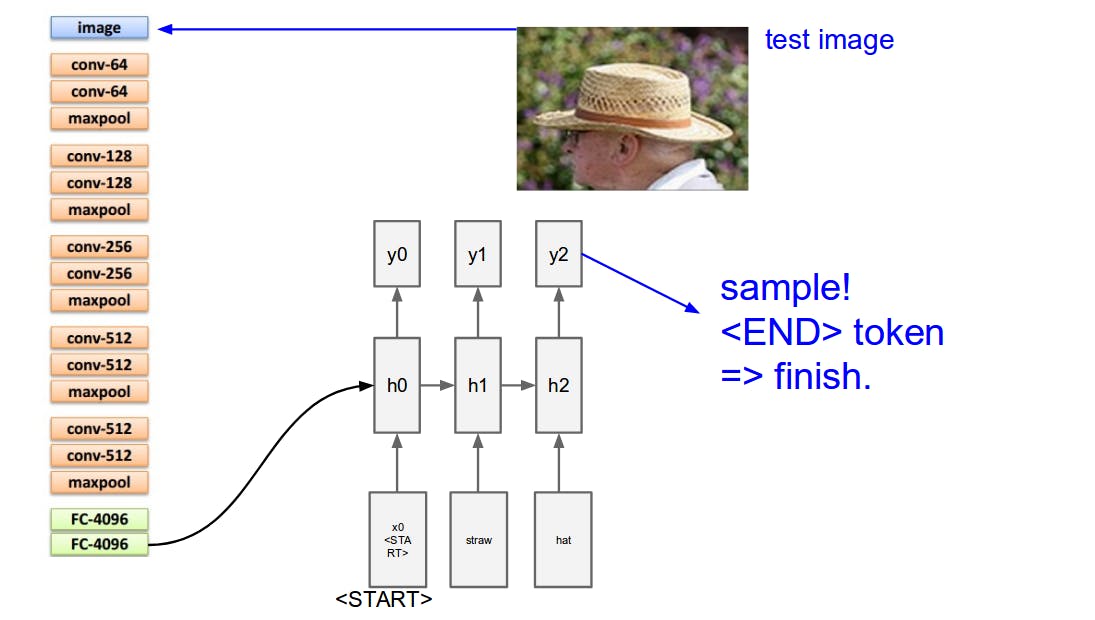
将实施混合深度神经网络,使用简单的 USB 摄像头和 Jetson Nano 实时提供每一帧的字幕。
项目设计阶段
该项目将分四期建设。在第一阶段,我们将在配备独立显卡的主机上设置和训练网络。第二阶段包括设置 Jetson Nano 和实现从相机到 HDMI 监视器的简单图像管道。第三阶段包括将图像字幕深度神经网络与第二阶段的图像流水线相结合。最后,在最后一个阶段,我们将在真实世界的设置下测试网络。

硬件需要为 Jetson Nano 提供 2A 电源,因为从 USB 为其供电不足以在高性能模式下运行神经模型。为此,请确保将跳线安装在 Jetson Nano 的右侧。然后插入 USB 摄像头、带有最新图像的 SD 卡和以太网电缆。设置好硬件后,下一步就是设置先决条件框架。
主机设置
首先,我们将在主机笔记本电脑上定义和训练网络。该项目将使用 Tensorflow 2.01、Keras 2.1 和 OpenCV 4.1。先决条件是安装 Cuda10.0 和 Visual Studio Express 17.0 以利用 GPU 速度增益,以防笔记本电脑配备支持 NVIDIA 的 GPU。
我们将用于训练的数据集是 Flickr8K 图像数据集。这是一个相对较小的数据集,允许在笔记本电脑级 GPU 上训练完整的 AI 流水线。人们还可以使用更大的数据集,这将以更高的训练时间为代价获得更好的性能。数据集可以通过申请表从伊利诺伊大学下载。
下一个数据集是 Glove 数据集,它是一组从大型文本语料库构建的词嵌入。该数据集本质上充当了 AI 从中获取词汇的字典。标题文本清理完成后,下一步是加载 Glove 嵌入。嵌入是神经网络使用的单词编码。基本上单词被投影为高维空间中的向量,然后表示为向量。从这里下载数据集:
https://nlp.stanford.edu/projects/glove/
然后创建一个名为 /Captioning 的顶级目录,并在其中提取两个压缩文件。
另外创建一个名为 /data 的文件夹,用于保存训练阶段生成的文件。接下来我们将定义网络并训练网络。
神经网络训练
从高层次的角度来看,图像字幕深度学习网络由菊花链式连接在一起的深度 CNN (InceptionV3) 和 LSTM 循环神经网络组成。CNN 的输出是一个表示图像类别的 x 维向量。输出被发送到 LSTM,后者生成图像中对象的文本描述。LSTM 基本上接收 x 维向量流。在此基础上,它实时串接了对场景的描述。
可以在 Github 上找到训练网络的 Ipython 笔记本。主网络的设计基于 Jeff Heaton 的工作。它由一个 InceptionV3 CNN 和一个 LSTM 递归神经网络组成。
下一步是从 Flickr 字幕构建数据集,并通过标记化和预处理文本来清理所有描述。然后我们将 Flickr8K 数据集拆分为测试和训练图像数据集。然后我们加载训练数据集描述并训练网络。
如前所述,Inception 网络用作网络的第一阶段。最后一个全连接层被移除,因此从第一阶段 CNN 出来的数据是一个一维向量。Inception 只能接受分辨率为 299x299 像素的图像,因此必须对相机图像进行格式化。
inputs1 = Input(shape=(OUTPUT_DIM,))
fe1 = Dropout(0.5)(inputs1)
fe2 = Dense(256, activation='relu')(fe1)
inputs2 = Input(shape=(max_length,))
se1 = Embedding(vocab_size, embedding_dim, mask_zero=True)(inputs2)
se2 = Dropout(0.5)(se1)
se3 = LSTM(256)(se2)
decoder1 = add([fe2, se3])
decoder2 = Dense(256, activation='relu')(decoder1)
outputs = Dense(vocab_size, activation='softmax')(decoder2)
caption_model = Model(inputs=[inputs1, inputs2], outputs=outputs)
上面的代码片段显示了编辑后的 InceptionV3 CNN 与 LSTM 连接。这实现了编码器-解码器架构。
完成后,我们必须循环遍历训练和测试图像文件夹,并对每张图像进行预处理。
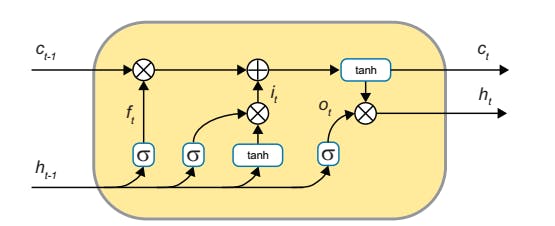
网络的最后一部分是循环长短期记忆神经网络。(LSTM) 简称。该网络获取序列并尝试预测序列中的下一个单词。这些类型的网络的工作由斯坦福大学的 A. Karpathy 完成,他指出它们对于此类任务来说是多么充分。
最后一步是训练网络。对于这个项目,最初使用了 6 个 epoch,损失最初为 2.6%。然而,为了获得可接受的结果,损失必须远小于 1,因此必须训练至少 10-15 个时期。
训练网络后,我们加载训练好的权重并在数据集的测试图像以及不属于原始数据集的图像上测试网络。
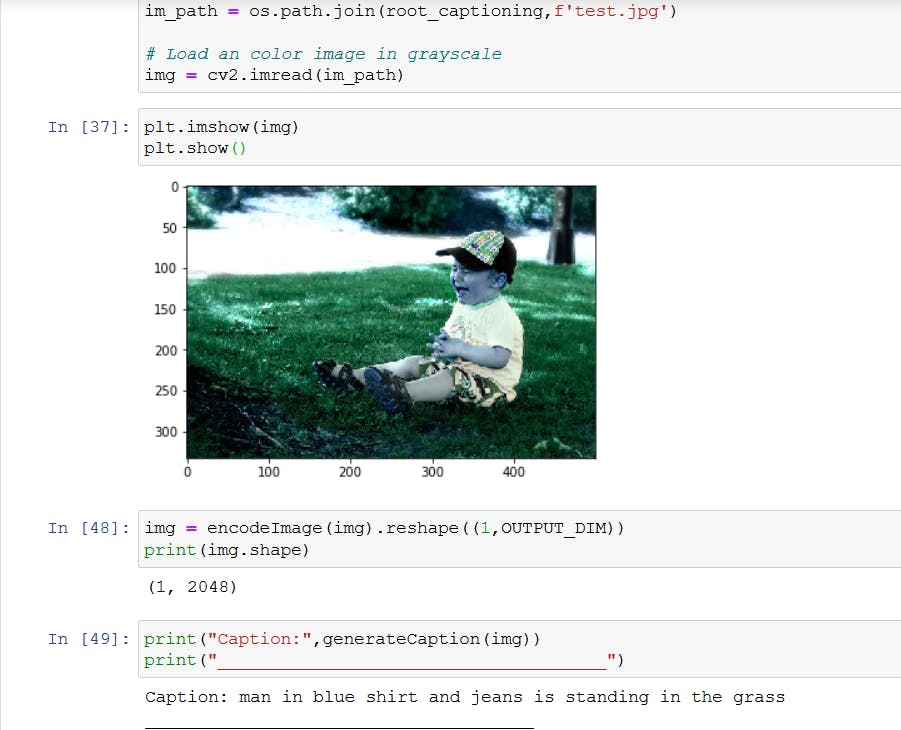
如果图像在风格和内容上与 Flickr9K 数据集中的图像非常相似,则描述相对准确。这也可以使用 OpenCV API 来完成。首先我们需要安装正确的版本。
安装OpenCV
OpenCv4.1 是从源代码编译的。这可能需要一段时间。要安装 4.1 版,我使用了以下脚本:
curl -L https://github.com/opencv/opencv/archive/4.1.1.zip -o opencv-4.1.1.zip
curl -L https://github.com/opencv/opencv_contrib/archive/4.1.1.zip -o opencv_contrib-4.1.1.zip
unzip opencv-4.1.1.zip
unzip opencv_contrib-4.1.1.zip
cd opencv-4.1.1/
echo "** Building..."
mkdir release
cd release/
cmake -D WITH_CUDA=ON -D ENABLE_PRECOMPILED_HEADERS=OFF -D CUDA_ARCH_BIN="5.3" -D CUDA_ARCH_PTX="" -D WITH_GTK=OFF -D WITH_QT=ON -D OPENCV_EXTRA_MODULES_PATH=../../opencv_contrib-4.1.1/modules -D WITH_GSTREAMER=ON -D WITH_LIBV4L=ON -D BUILD_opencv_python2=ON -D BUILD_opencv_python3=ON -D BUILD_TESTS=OFF -D BUILD_PERF_TESTS=OFF -D BUILD_EXAMPLES=OFF -D CMAKE_BUILD_TYPE=RELEASE -D CMAKE_INSTALL_PREFIX=/usr/local ..
make -j3
sudo make install
请注意,GTK 已关闭,以避免在使用默认设置编译时发现的库出现问题。
安装 OpenCV 后,使用下面附带的文件 test_openCV.py 测试程序。USB 摄像头在 /dev 下显示为 /video0。
捕获帧后,可以使用以下函数将文本覆盖在每个帧的顶部:
def __draw_label(img, text, pos, bg_color):
font_face = cv2.FONT_HERSHEY_TRIPLEX
scale = 1
color = (255, 255, 255)
thickness = cv2.FILLED
margin = 5
txt_size = cv2.getTextSize(text, font_face, scale, thickness)
end_x = pos[0] + txt_size[0][0] + margin
end_y = pos[1] - txt_size[0][1] - margin
cv2.rectangle(img, pos, (end_x, end_y), bg_color, thickness)
cv2.putText(img, text, pos, font_face, scale, color, 2, cv2.LINE_AA)
下图显示了从相机捕获的帧,日期覆盖在帧的顶部。
所有通过 OpenCv API 从相机拍摄的图像都是 numpy 数组。因此,数组必须转换为图像,调整大小以匹配 InceptionV3 CNN 要求,然后再转换回图像并进一步预处理。使用具有多个可编程分辨率的相机可以避免这种情况。
与最新的 RTX 类 GPU 相比,Jetson Nano 没有特别强大的 GPU,因此,训练网络绝对应该在主机笔记本电脑上完成。

。
。
网络需要 2-3 分钟来加载,因为它读取并解析所有编码。然后它读取图像帧并将其通过网络传递。推理发生得非常快。
网络最初会根据内存不足发出一些警告。请记住,它没有使用 TensorRT 进行优化,因此可以通过这样做并用更好的 CNN(例如 Xception)替换 InceptionV3 来进一步提高速度。
系统应用
实施此类系统的主要途径是沿海监控、公园安全监控以及任何此类场景,其中自动监控可用于对挽救生命和确保环境安全产生积极影响的应用。
进一步改进
下一步是将 Tensorflow 模式转换为 NVIDIA 的 TensorRT,以获得额外的加速。
由于这是一个模块化系统,网络的输出可以传递给通知系统,每当图像描述中出现感兴趣的词时,通知系统就会发送一封电子邮件。
进一步的发展是将其与对话式人工智能系统相结合,以构建一个“询问和描述”系统。
结论
可以看出,网络仅在图像内容与训练图像相似的情况下表现良好。
为了改进描述,需要使用更大的文本语料库以及更大的注释数据集。虽然 Flickr30K 的大小几乎是当前数据集的 4 倍,但如果使用 MSCoCO 数据集,可以获得更好的结果。问题是您需要强大的 GPU 或使用云。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章






