
资料下载


构建一个具有人工智能的农业监测系统
周臻庸
分享资料个
描述
介绍
从经济角度来看,气候变化的影响有利于破坏性越来越强的害虫的传播,并威胁到最重要的植物和作物的生存,这种情况对粮食安全和环境构成越来越大的威胁。资料来源:联合国。
问题:
气候变化导致大气中温度、湿度和气体的变化,特别是温室气体的积累,这可能有利于真菌和昆虫的生长,改变疾病三角(宿主-病原体-环境)的相互作用,从而减少它们的产量。
各种调查表明,温带和热带地区害虫发生率的波动与干旱期事件以及干旱和高相对湿度的结合有关。
联合国粮食及农业组织 (FAO) 估计,害虫每年破坏全球作物产量的 40%,而植物病害每年使世界经济损失超过 220 亿美元,入侵昆虫至少造成 70 , 0 亿美元。资料来源:联合国。
“本次评估的主要结论应该提醒我们大家注意气候变化如何影响世界各地害虫的传染程度、传播和严重程度,”本组织总干事在研究报告中说。
解决方案
设计和构建一个具有人工智能的农业监测系统,能够识别农作物中的害虫和害虫,使系统能够选择正确的除草剂和数量,以自动和立即根除它。同样,能够记录和分析农业气候变量,以便分析和做出有关作物的决策,从而防止气候变化造成的损失。
第一步:
配置 Petalinux
1. 设置 SD 卡映像 (PetaLinux)
我们必须在 Xilinx 开发者计划中注册才能下载Petalinux 2021.1 镜像。
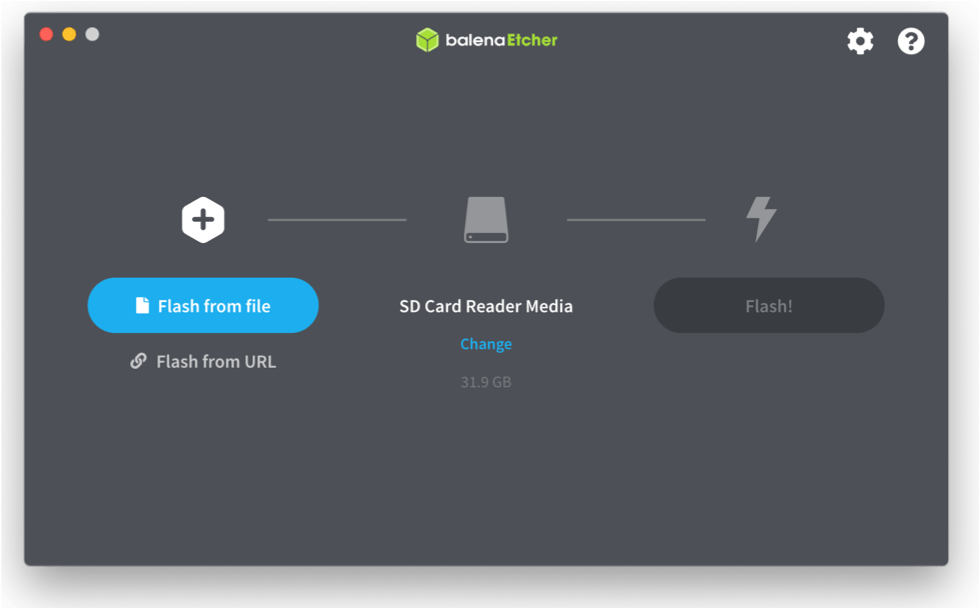
在 Balena Etcher 中加载图像后,我们继续对其进行闪存。
2.连接一切:
我们确保所有电缆都连接良好。(如图所示)
3. 开机:
我们配置通过 COM 端口与卡的连接。所以我们继续使用 PuTTy 并确保我们配置了以下参数:
- 波特率 = 115200
- 数据位 = 8
- 停止位 = 1
- 流量控制 = 无
- 奇偶校验 = 无
我们将配置我们的电路板。
我们可以使用以下命令在板上进行一些快速测试。
VITIS AI 配置
需要注意的是,如果您没有 Linux 操作系统,您可以在虚拟机中执行以下安装。
1.在机器上安装和配置Docker 。
2. 克隆 Vitis-AI 存储库以获取示例、参考代码和脚本。
git clone --recurse-submodules https://github.com/Xilinx/Vitis-AI
cd Vitis-AI
3. 使用以下命令下载最新的 Vitis AI Docker。此容器在 CPU 上运行。
docker pull xilinx/vitis-ai-cpu:latest
4. 要运行 docker,请使用命令:
./docker_run.sh xilinx/vitis-ai-cpu:latest
训练模型
为了训练模型,我们使用 TensorFlow 创建神经网络。需要澄清的是,您必须购买 Colab 的 PRO 计划才能使用 30Gb RAM GPU。
1.我们导入库并下载数据库:
import tensorflow as tf
import tensorflow_datasets as tfds
datos, metadatos = tfds.load('plant_village', as_supervised = True, with_info = True)
metadatos.features
print(metadatos.features["label"].names)
2. 调整图像大小:由于所有图像的尺寸不同并且可能与 TensorFlow 冲突,我们继续调整所有图像的大小:
import matplotlib.pyplot as plt
import cv2
plt.figure(figsize=(20,20))
tamaño = 50
for i, (imagen, etiqueta) in enumerate(datos['train'].take(25)):
imagen = cv2.resize(imagen.numpy(), (tamaño, tamaño))
plt.subplot(5, 5, i+1)
plt.imshow(imagen)

3.拆分数据库进行训练
train_data = []
for i, (imagen, etiqueta) in enumerate(datos['train']):
imagen = cv2.resize(imagen.numpy(), (tamaño, tamaño))
imagen = imagen.reshape(tamaño, tamaño, 3)
train_data.append([imagen, etiqueta])
#Prepare my variables X (inputs) and y (labels) separately
X_data = [] #imagenes de entrada (pixeles)
y_data = [] #etiquetas
for imagen, etiqueta in train_data:
X_data.append(imagen)
y_data.append(etiqueta)
4.将Xdata和Ydata转换为数组
import numpy as np
X_data = np.array(X_data).astype(float) / 255
y_data = np.array(y_data)
5. 构建神经网络:初始层、隐藏层和输出层具有各自的激活函数
modeloCNN = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(50, 50, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(100, activation='relu'),
tf.keras.layers.Dense(38, activation='softmax')
])
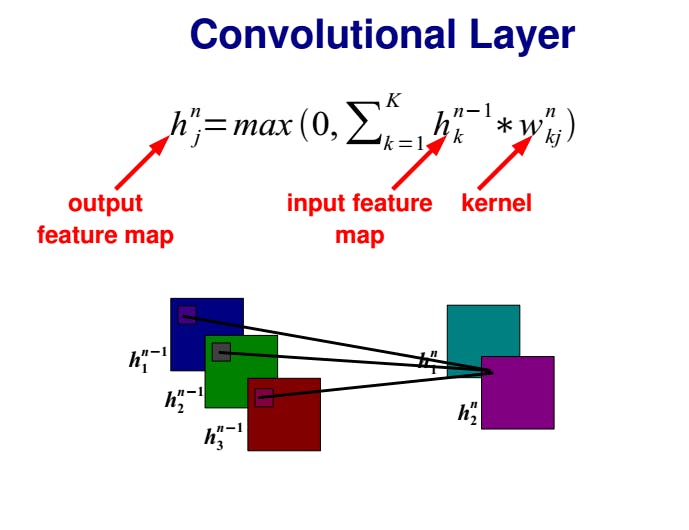
6.我们编译模型:
modeloCNN.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
modeloCNN2.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
7.我们重新训练模型:
from tensorflow.keras.callbacks import TensorBoard
from tensorflow.keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
rotation_range=30,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=15,
zoom_range=[0.7, 1.4],
horizontal_flip=True,
vertical_flip=True
)
datagen.fit(X_data)
plt.figure(figsize=(20,8))
for imagen, etiqueta in datagen.flow(X_data, y_data, batch_size=10, shuffle=False):
for i in range(10):
plt.subplot(2, 5, i+1)
plt.xticks([])
plt.yticks([])
plt.imshow(imagen[i].reshape(50, 50, 3))
break
from keras.models import Sequential
from keras.layers import Convolution2D, MaxPooling2D, Dropout
from keras.layers import Flatten, Dense
from keras.layers import Conv2D, GlobalAveragePooling2D
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
from keras.layers import Conv2D, MaxPooling2D, GlobalAveragePooling2D
from keras.layers import Dropout, Flatten, Dense
from keras.models import Sequential
8. 我们创建初始模型:
modeloCNN_AD = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(50, 50, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(100, activation='relu'),
tf.keras.layers.Dense(38, activation='softmax')
])
X_train = X_data[:40000]
X_valid = X_data[40000:]
y_train = y_data[:40000]
y_valid = y_data[40000:]
modeloCNN_AD.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
data_gen_train = datagen.flow(X_train, y_train, batch_size=32)
tensorboardCNN_AD = TensorBoard(log_dir='logs/cnn_AD')
modeloCNN_AD.fit(
data_gen_train,
epochs=100, batch_size=32,
validation_data=(X_valid, y_valid),
steps_per_epoch=int(np.ceil(len(X_train) / float(32))),
validation_steps=int(np.ceil(len(X_valid) / float(32))),
callbacks=[tensorboardCNN_AD]
)
9、训练结果:

10.我们下载模型:
modeloCNN_AD.save('my_model-cnn-ad.h5')
模型量化
1. 将训练和数据库产生的模型导入 Vitis AI 中创建的量化代码。
2.我们定义我们的量化模型:
def quantize(train_generator, model):
# run quantization
quantizer = vitis_quantize.VitisQuantizer(model)
#quantizer = tfmot.quantization.keras.quantize_model(model)
quantized_model = quantizer.quantize_model(calib_dataset=train_generator, calib_batch_size=10)
3.我们保存量化模型:
# save quantized model
quantized_model.save('quantized_model.h5')
return (quantized_model)
汇编
1. 创建 unarchivo llamado arch.json donde asignamos la configuración de la DPU
{
"fingerprint":"0x1000020F6014406"
}
2. Aplicamos el comando source compile.sh donde aparece la ubicación del archivo arch.json。
compile() {
vai_c_tensorflow2 \
--model quantized_model.h5 \
--arch $ARCH \
--output_dir build/compiled_$TARGET \
--net_name customcnn
}
compile 2>&1 | tee build/logs/compile_$TARGET.log
3.我们的模型生成的这些.xmodel文件通过SFTP连接上传到板子。
sftp petalinux@
4.我们执行以下命令:
lcd ..
put -r compiled_$TARGET
5. 接下来,在开发板上启动 petalinux,我们继续创建以下文件:
- aiiference.json
- 绘制结果.json
- 预处理.json
6.这三个文件必须位于目录中:
sudo cp yolov2tiny/aiinference.json /opt/xilinx/share/ivas/smartcam/ssd/aiinference.json
sudo cp yolov2tiny/preprocess.json /opt/xilinx/share/ivas/smartcam/ssd/preproces.json
sudo cp yolov2tiny/drawresult.json /opt/xilinx/share/ivas/smartcam/ssd/drawresult.json
7. 我们测试我们的项目在相机上运行良好,并且我们的机器学习模型运行良好:
sudo xmutil unloadapp
sudo xmutil loadapp kv260-smartcam
sudo smartcam --usb 0 -W 1920 -H 1080 --target rtsp --aitask ssd
使用 Pynq 配置传感器
对于这个项目,我们需要启用和使用 Pmod 端口并将传感器与Pynq Grove 适配器连接。
我们将初步分析:
- 温度
- 湿度
- 水位
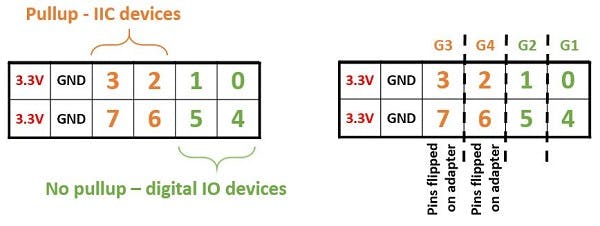
1.创建一个目录来包含我们需要的所有文件:
project-spec/meta-user/recipes-apps
2.创建一个.bb文件:
> vim python3-pynq-temp&hum.bb
3. 我们直接从根目录安装传感器的包。
SRC_URI = "https://pynq.readthedocs.io/en/v2.0/_modules/pynq/lib/pmod/pmod_tmp2.html#:~:text=lib.pmod.pmod_tmp2-,Edit%20on%20GitHub,-Note"
SRC_URI[md5sum] = "ac1bfe94a18301b26ae5110ea26ca596"
SRC_URI[sha256sum] = "f522c54c9418d1b1fdb6098cd7139439d47b041900000812c51200482d423460"
SRCREV = "0e10a7ee06c3e7d873f4468e06e523e2d58d07f8"S = "${WORKDIR}/git"
inherit xilinx-pynq setuptools3
4. Xilinx-pynqclass 将创建一个PYNQ_NOTEBOOK_DIR变量,该变量将被打包在 notebook 子包中,但我们仍然需要确保环境正确,配方才能正确运行。在这种情况下,我们需要设置PYNQ_JUPYTER_NOTEBOOK环境变量。 BOARD setup.py还期望笔记本目录存在,因此我们需要创建它。为此,我们可以在编译的不同步骤之前添加说明。
do_compile_prepend() { export BOARD=KV260 export PYNQ_JUPYTER_NOTEBOOKS=${D}${PYNQ_NOTEBOOK_DIR}}
do_install_prepend() { export BOARD=KV260 export PYNQ_JUPYTER_NOTEBOOKS=${D}${PYNQ_NOTEBOOK_DIR} install -d ${PYNQ_JUPYTER_NOTEBOOKS}}
do_configure_prepend() { export BOARD=KV260 export PYNQ_JUPYTER_NOTEBOOKS=${D}${PYNQ_NOTEBOOK_DIR} install -d ${PYNQ_JUPYTER_NOTEBOOKS}}
5. 我们需要定义独立性。
RDEPENDS_${PN} += "\
python3-pynq \
python3-pillow \
pynq-overlay \
libstdc++ \ "
RDEPENDS_${PN}-notebooks += "\
python3-jupyter \ "
6. 运行:
> petalinux-build -c python3-pynq-temp&hum
7. 我们可能会遇到需要修复的兼容性错误,方法是创建一个用简单添加替换格式字符串的补丁。
8. 我们必须将补丁放在一个子文件夹中才能被识别。
> mkdir python3-pynq-temp&hum
> cp $patch_file python3-pynq-temp¬hum/build-fixes.patch
有必要用一个页面来告诉我们。
9. 现在我们必须执行命令,以便 Petalinux 识别新安装的软件包。
> cd ../../
> vim conf/user-rootfsconfig
CONFIG_python3-pynq-temp¬hum
CONFIG_python3-pynq-temp¬hum-notebooks
> petalinux-config -c rootfs
10. 现在我们可以创建完整的图像了:
> petalinux-build
> petalinux-package --boot --u-boot --atf --pmufw
11. 我们可以测试板子,它会给我们终端地址来直接启动 Jupyter。
12. 我们为我们的传感器运行代码,它们可以在这个项目的最后找到。
谷歌云物联网配置
为了实时可视化我们的作物并获取传感器记录的图表,我们使用 Jupyter Notebook 配置了 Google Cloud。
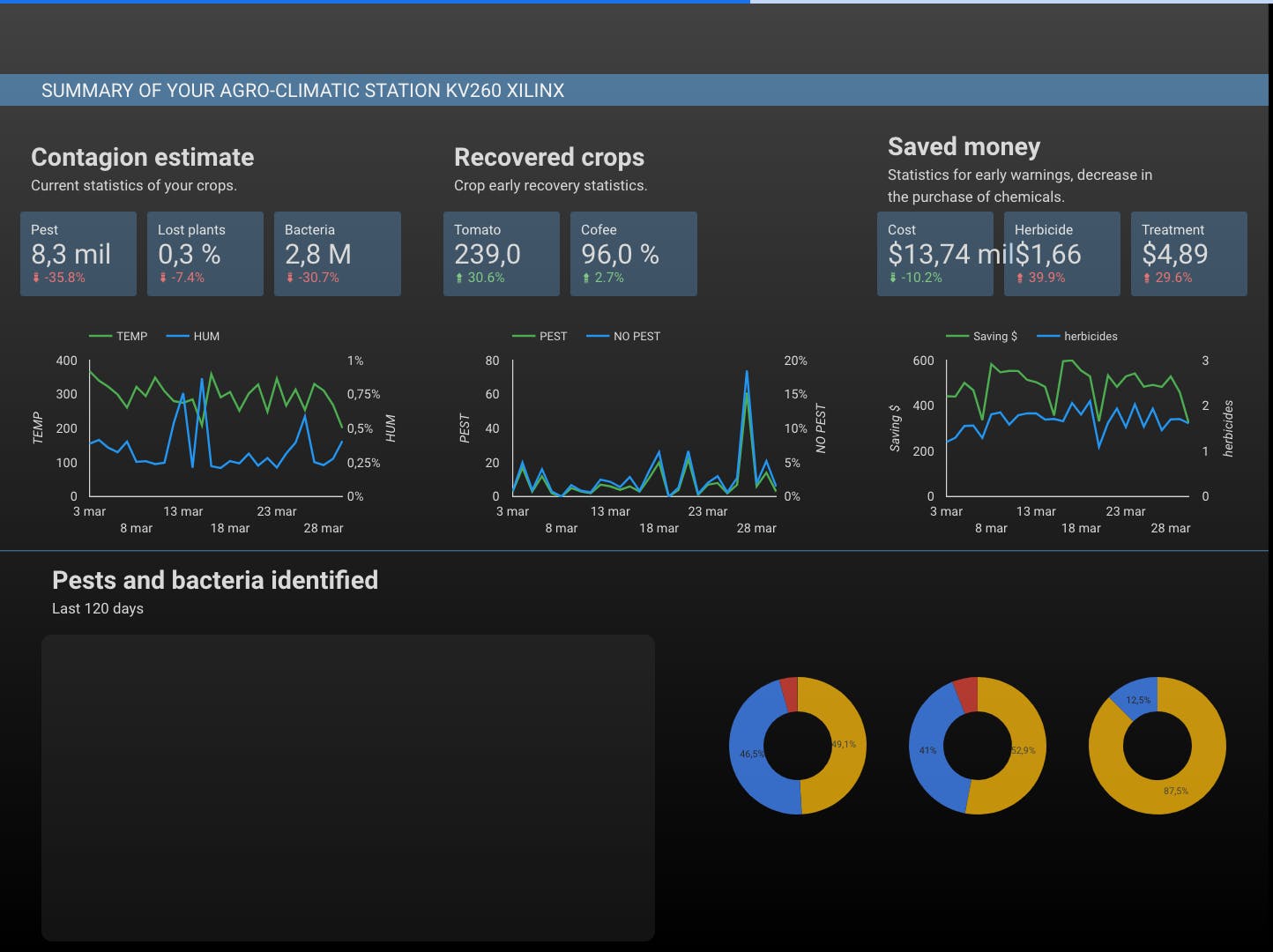
惊厥神经网络模型的表格数据库
它使用了 20 多种不同类型农作物的 5000 多张参考图像,您可以在此处获取。

赛后进展:我们希望能够整合用于喷洒除草剂的电动泵系统、用于作物灌溉的水以及开发与谷歌云集成的移动应用程序,从而使农场实现自动化。
同样,我们希望与赛灵思一起,通过 Pynq 实现更多对极端条件具有更强抵抗力的传感器,以实时和持续监测新变量,例如磷、钾的水平、气体的存在、我们系统中的红外摄像机。农业气候监测。
非常感谢整个 Xilinx 团队有机会使用最先进的产品开发项目,并随时为我们提供支持,使该项目的开发得以实现。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章






