
资料下载


使用Jetson Nano构建人脸识别系统
凤毛麟角
分享资料个
描述
几个月前,出于对教育的好奇心,我萌生了使用 Jetson Nano 构建人脸识别系统的想法。后来随着最初的想法被调整为激活滑动门。为了让它变得可行,我和我的伙伴 Mrugank 和 Suman 集思广益,用可动人偶实现了同样的效果。
但它只是一个想法,没有太多行动。多亏了由 Nvidia 和 Hackster.io 主办的“AI at the Edge Challenge”,我们组建了自己的团队 (Nerds United Alpha) 并努力将这个想法变为现实。
我们决定赋予它“复仇者联盟智能之家”的光环,只欢迎 Marvel 可动人偶,每个角色都有自定义语音欢迎信息。
创建数据集
在库存中,我们有一些可动人偶,但不幸的是,没有可用于可动人偶的数据集。因此,我们必须建造一个。由于这是一个需要深度学习的计算机视觉用例,因此大约10 -15k图像的数据集就足够了。
手动点击/收集这么多图像将是一个繁琐的过程。因此,为了拯救我们,我们想出了两个步骤来自动化创建深度学习图像数据集的过程:
1. 使用搜索查询收集图像:多亏了PyImageSearch 的有趣教程,我们才能够通过 Bing 搜索查询自动执行收集图像的过程。微软免费提供 Bing Search API,但有一定的限制(每天约 3000 次搜索查询)。您也可以使用它来填充您自己的数据集。我们为每个班级收集了大约 100 张图像。
2. 数据增强:当您缺乏足够的数据来完成您的任务时,执行一些数据增强技术来创建合成图像非常有效。随机旋转、裁剪、过滤器和水平翻转等技术可以解决问题。我们使用 skimage 库来执行相同的操作。
模型创建和训练
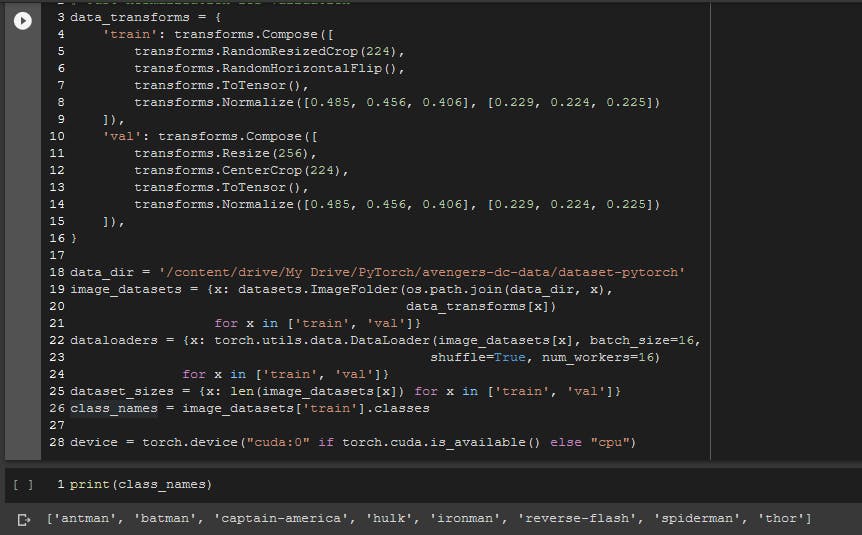
为了训练我们的模型,我们选择了 Google Collaboratory 提供的 Nvidia GPU 运行时。PyTorch 是我们选择的深度学习框架来构建和训练我们的模型。因此,我们参考了 PyTorch.org 的官方迁移学习教程。因此,您需要做的就是运行 Google Colab 实例并将您的数据集上传到谷歌驱动器。根据代码,确保将数据集文件夹分隔为“train”和“val”文件夹,并将各个类作为子目录。
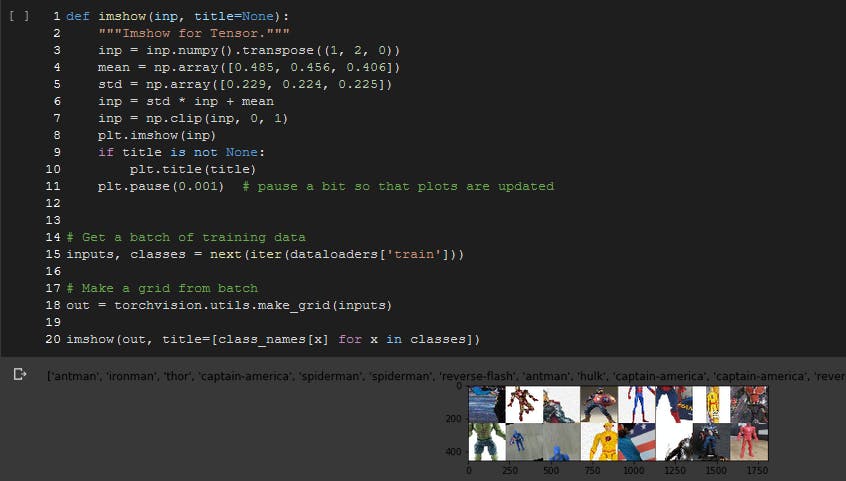
使用 ResNet-18 进行迁移学习
ResNet-18 是最受欢迎的预训练神经网络之一。我们很乐意继续使用它进行迁移学习。
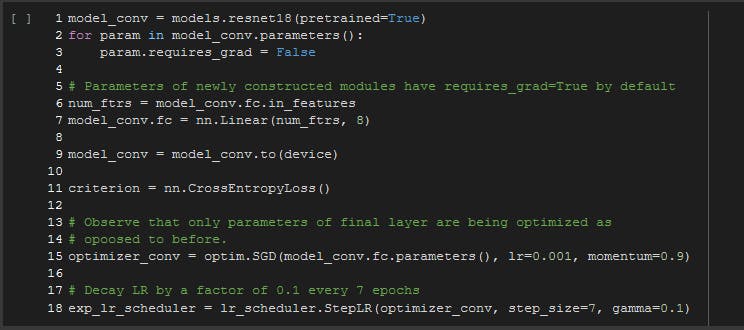
因为我们只是迁移学习,所以我们不需要在我们的神经网络中进行反向传播。因此,我们在获得预训练模型后的第一步停用它,并修改全连接层,使其变为线性并提供类数,即“8”,以及模型中的特征数,如下争论。
这是使用 GPU 进行更快训练的必要步骤,因此,模型需要传输到“设备”,这恰好是 Nvidia GPU。您可以自由选择您的标准。'CrossEntropyLoss' 和 'NLLLoss' 都是首选。
现在是时候用我们的模型训练和分类图像了。请参阅笔记本中的train_model方法以获得进一步的见解。
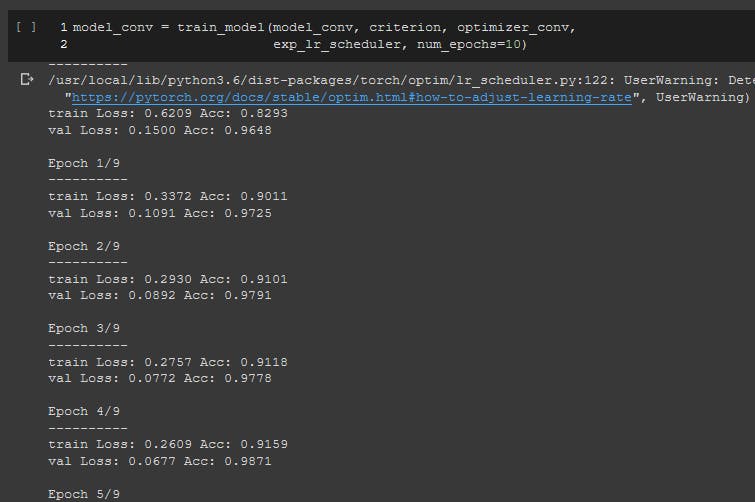
对我们来说,最佳验证准确率约为 0.99,这是一个相当不错的表现。预测结果也很惊人!现在,使用必要的 torch.save() 函数保存模型。
让我们开始使用 Jetson Nano 部署我们的推理模型吧!
设置 Jetson Nano 进行推理
Nvidia Jetson Nano 是一款带有板载 Tegra GPU 的嵌入式 SoC,针对“边缘人工智能”进行了优化和构建。要开始使用 Jetson Nano,您可以参考官方指南进行首次启动设置。简而言之,您只需要使用 Nvidia 最新的“Linux For Tegra (L4T)”映像刷入 UHS-I SD 卡。之后,确保您拥有为 Jetson Nano 供电和启动的先决条件硬件。
1.先决条件
我们建议您拥有:
- microSD 卡(32 - 64 GB UHS-1)
- USB 键盘和鼠标
- 电脑显示器(HDMI 或 DP)
- 电源适配器(5V=4A)【OnePlus、MiA1等手机适配器】
- USB 至 5V DC (2.1 mm) 桶形插孔电缆
该设备随JetPack一起提供,其中包含一套内置的 Nvidia 软件和必要的 CUDA 库。Nano 的最新 L4T (r32.1.1) 更新带有默认的 OpenCV 4 版本,这对计算机视觉社区来说是一个巨大的福音。
2.推理库
请注意,Jetson Nano 是一款非常适合AI 推理任务的边缘设备。请不要误会,您可以用它来训练您的模型。它会升温并繁荣!为了我们的深度学习推理目的,我们需要以下库和包。
- 火炬
- 火炬视觉
- Py2trt - 构建与 PyTorch 模型兼容的TensorRT推理引擎
要获得上面的先决条件列表,只需访问Nvidia 论坛链接,了解从源代码构建的分步过程。要安装 py2trt 模块,只需在终端中执行以下命令:
pip install torch2trt
3.加载和转换我们的模型(Py2TRT)
Nvidia 使得将在 PyTorch 中训练的模型移植到它的 TensorRT 对应模型变得非常容易,只需一行。请参阅下图了解必要的步骤。

- 初始化pytorch模型对象
- 加载模型状态字典
-
创建一个示例张量(确保它与您通常训练的 cv2 窗口捕获大小/图像大小的分辨率相匹配):我们提供 (480, 640) 以匹配 640x480 分辨率大小。准备好了!
请参阅此代码以进一步了解 GPIO 模式操作以设置电机运动。
这个旋转电机将帮助我们方便滑动门
3.选择滑动门机构

上图是齿条和小齿轮机构的参考图像,用于前后滑动我们的门。旋转的直流电机产生旋转齿轮所需的力。当齿轮连接到兼容的牙齿时,有助于连接的下颌沿相反方向滑动。

根据上图,您可以看到我们带推拉门的智能住宅的原型。Jetvengers House 已准备就绪。我们 3D 打印了滑动门的重要部件,即“架子”。
PS:我们用硬纸板建造了我们的房子,L2989N(其中一个带有红色 LED)由 UPS 电池供电 XD!
整合人工智能和物联网
现在是时候让我们的 Jetvengers HQ 智能功能付诸行动了。感谢JKJung 与自定义 tegra-cam 的合作,我们能够让GStreamer管道与 Jetson Nano 上的 OpenCV 一起工作。
请注意,为了在计算机视觉中更快地传输数据,您需要 gstreamer 插件管道,否则流会严重滞后,从而阻碍您的工作。
要了解如何创建 gstreamer 管道,您可以查看我们的代码,但我们不会深入探讨。我们的重点是如何通过简单的图像分类来识别可动人偶。
1.捕获帧进行预处理
此代码位于我们存储库中的gstreamer.py文件中。看一眼熟悉代码。
首先,确保导入这些必要的模块

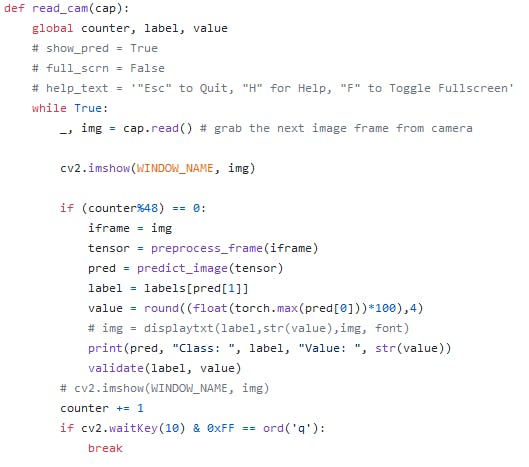 read_cam() 捕捉帧
read_cam() 捕捉帧提供一个计数器变量以捕获流中的每 48 帧(如果 framerate = 24 每秒,则每 2 秒捕获一次)。将捕获的帧传递给预处理。在所有过程之后增加计数器。确保为等待键和中断提供条件以继续/中断流。
2.图像预处理
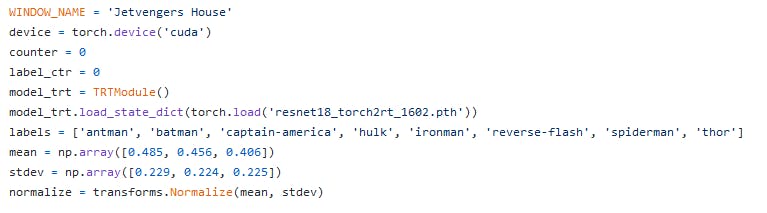 检查传递给标准化变量的均值和标准差,我们将使用它
检查传递给标准化变量的均值和标准差,我们将使用它当然,我们需要执行此步骤以匹配在训练过程中转换训练和验证图像时的状态。
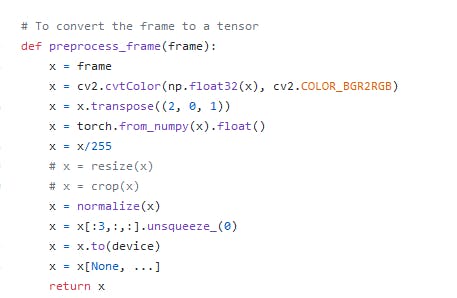
确保执行这些步骤。不要忘记将图像转换为 RGB,因为 OpenCV 以 BGR 格式捕获每一帧。
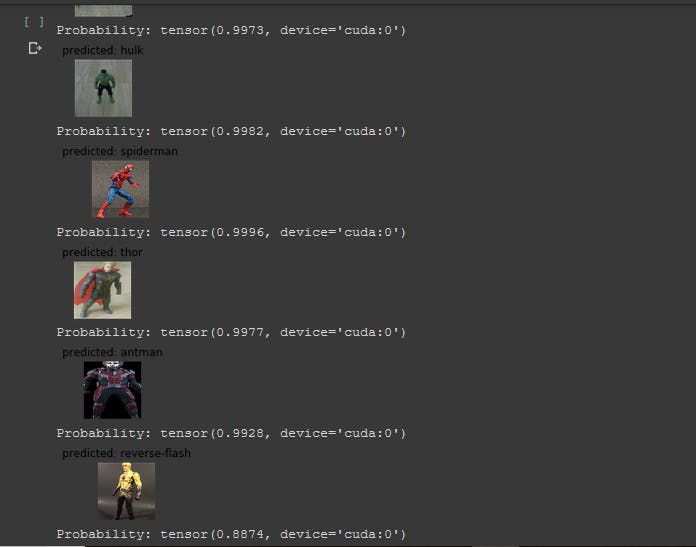
3. Image Prediction(识别动作人物)

我们附加了一个 softmax 层以获取可读格式的概率,否则我们将无法解释这些值以进行进一步处理。我们需要返回概率和顶级类别,以便我们可以在终端中打印它的值,并将其用于进一步的处理。
 我们的模型处于早期阶段。类别正确预测为“蝙蝠侠”,置信度值为 85%
我们的模型处于早期阶段。类别正确预测为“蝙蝠侠”,置信度值为 85%4.是时候执行物联网操作了
由于识别(AI 部分)已完成,让我们自动执行其余操作:
i) 用语音消息问候人偶 ii) 打开/关闭门让我们的客人进来 iii) 如果角色来自 DC(比如蝙蝠侠),播放必要的消息音频并且不允许角色进入开门

我们执行验证步骤以确保该角色仅来自漫威宇宙。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章





