
资料下载


NVIDIA Jetson Nano上的智能视频分析
20762
分享资料个
例如,未来的城市,也被称为智慧城市,应该部署摄像头网络来提供监控以防止犯罪、有效管理交通并减少能源使用。其工作原理基于多层神经网络,使用无限数据集进行训练。然而,训练深度学习网络是一项计算密集型任务,需要并行执行许多矩阵乘法运算。因此,许多最先进的商用单板计算机不是执行上述任务的合适硬件平台,因为它们是单线程性能优化架构。随着开发人员套件的到来,例如 NVIDIA 的 Jetson Nano,专门用于运行人工智能工作负载,
在这个项目中,我们将注意力集中在计算机视觉中的一个突出主题:行人分析。我们根据人们行为分析可以为地方当局提供的不同用例做出这一选择,以定制该技术可能定位的当地人口的需求。例如,我们设想以下应用程序:
- 统计出入地铁或公交车站的人数,以规范行人交通。
- 统计在商店橱窗里看文章的人数,以建立一定数量的潜在客户。
使用深度学习算法计算人数绝非易事,因为在训练神经网络时需要考虑许多参数。例如,捕获相机所在的高度会扰乱快照的质量,从而给图片引入噪点,从而更难跟踪照片场景中的每个行人。因此,训练阶段可能意味着进一步的步骤来识别图像的属性。
解决方案
为了克服这些挑战,我们提出了一种基于 NVIDIA Jetson Nano 的解决方案来计算从摄像机前经过的人数。我们算法的工作原理基于以下任务:
- 以高捕捉率捕捉图像。
- 不同帧率下的人物检测。
- 跟踪每个检测到的人以在下一个数据帧中关联。
- 通过在每个快照上区分个体来对个体进行计数。
除了人数统计算法外,还开发了一个基于网络的应用程序,以使用用户选择的各种参数来监控跟踪和统计结果。
项目计划
这个项目使用了一个摄像头,可以从街道上无缝捕捉图像,并将它们传输到 NVIDIA 的 Jetson Nano 进行进一步处理。除了图像处理之外,Jetson Nano 还托管一个基于 Web 的应用程序,连接到托管该应用程序的互联网的所有设备都可以访问该应用程序。这个项目需要一个摄像头从街道上捕捉图像并将它们传输到 Jetson Nano 以处理信息。

硬件
本节列出了开发该项目所需的硬件组件:
- Jetson Nano 开发者套件
- Jetson Nano Waveshare 金属外壳(B 型)
- IMX219 传感器 160 度 8MP 网络摄像头
- 无线网卡AC8265
- 微型SD卡
您可以在此处找到在 Waveshare 金属外壳中组装 Jetson Nano 的说明。

执行
NVIDIA 的 Jetson Nano 附带一个软件开发工具包,称为 Jetpack 4.3.1,它是 GNU/Linux Ubuntu 操作系统的变体,用于构建人工智能应用程序。此 SDK 的安装说明可在以下链接中找到。
该应用程序有 2 个主要组件:
- 一个 python 编写的后端应用程序。
- 基于 Angular 8 框架的 typescript 编写的前端应用程序。
后端应用程序执行以下任务:
- 从相机源捕获帧。
- 加载对象检测算法。
- 在每一帧上运行推理。
- 过滤图像图像。
- 通过 API 公开结果。
前端应用程序改为使用后端的 API 来呈现结果并处理捕获的数据。在以下部分中,将详细介绍后端和前端应用程序,重点介绍其每个组件。读者可以在本文末尾找到完整的源代码。
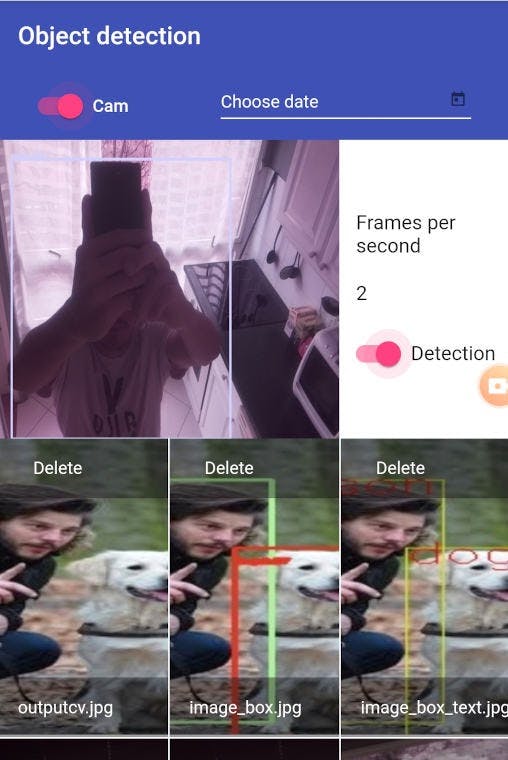
后端 - 捕获信息
将摄像头捕获的数据提取到 NVIDIA 的 Jetson Nano 中的最快方法是使用 gstream-lib 库,该库从插入的 CSI 摄像头的流源中设置。OpenCV 的 VideoCapture 函数通过从设备内存中的指定缓冲区获取图像数据来读取流式源。
后端 - 对象检测
对象检测 API 基于构建在 TensorRT 之上的检测框架,可简化 Mobilenet SSD 模型的加载。在初始化期间,NVIDIA 的 Jetson Nano 使用 PyCUDA python 库来访问 CUDA 的并行计算 API。同时,它创建了一个流属性,可以在 Jetson Nano 的内存中获取拍摄的图像,以使用深度学习训练的模型执行推理操作。
class TrtSSD(object):
""" TensorRT SSD mobilenet implementation """
def _load_plugins(self):
ctypes.CDLL("models/ssd_mobilenet/libflattenconcat.so")
trt.init_libnvinfer_plugins(self.trt_logger, '')
def _load_engine(self):
TRTbin = 'models/ssd_mobilenet/TRT_%s.bin' % self.model
with open(TRTbin, 'rb') as f, trt.Runtime(self.trt_logger) as runtime:
return runtime.deserialize_cuda_engine(f.read())
def _create_context(self):
for binding in self.engine:
size = trt.volume(self.engine.get_binding_shape(binding)) * \
self.engine.max_batch_size
host_mem = cuda.pagelocked_empty(size, np.float32)
cuda_mem = cuda.mem_alloc(host_mem.nbytes)
self.bindings.append(int(cuda_mem))
if self.engine.binding_is_input(binding):
self.host_inputs.append(host_mem)
self.cuda_inputs.append(cuda_mem)
else:
self.host_outputs.append(host_mem)
self.cuda_outputs.append(cuda_mem)
return self.engine.create_execution_context()
def __init__(self, model, input_shape, output_layout=7):
"""Initialize TensorRT plugins, engine and conetxt."""
self.model = model
self.input_shape = input_shape
self.output_layout = output_layout
self.trt_logger = trt.Logger(trt.Logger.INFO)
self._load_plugins()
self.engine = self._load_engine()
self.host_inputs = []
self.cuda_inputs = []
self.host_outputs = []
self.cuda_outputs = []
self.bindings = []
self.stream = cuda.Stream()
self.context = self._create_context()
def __del__(self):
"""Free CUDA memories."""
del self.stream
del self.cuda_outputs
del self.cuda_inputs
def detect(self, img, conf_th=0.3, conf_class=[]):
"""Detect objects in the input image."""
img_resized = _preprocess_trt(img, self.input_shape)
np.copyto(self.host_inputs[0], img_resized.ravel())
cuda.memcpy_htod_async(
self.cuda_inputs[0], self.host_inputs[0], self.stream)
self.context.execute_async(
batch_size=1,
bindings=self.bindings,
stream_handle=self.stream.handle)
cuda.memcpy_dtoh_async(
self.host_outputs[1], self.cuda_outputs[1], self.stream)
cuda.memcpy_dtoh_async(
self.host_outputs[0], self.cuda_outputs[0], self.stream)
self.stream.synchronize()
output = self.host_outputs[0]
return _postprocess_trt(img, output, conf_th, self.output_layout, conf_class)
在推理结束时,根据检测目的,基于置信概率阈值做出对象检测决策。SSD MobileNet 模型在 Coco 数据集上获取神经网络的预训练权重,产生 80 个输出类。对于行人分析,引入了一个名为“Person”的类来收集检测算法执行期间使用的所有属性。
检测模型的验证是通过样本图像在模块中完成的,这使我们能够毫不费力地交换被测模型。随后,我们使用 Github 的 Actions 来评估每个模型的性能,避免在引入修改时出现故障。用户可以使用 Pytest 框架访问目录“Test”中的模型评估。
后端 - 对象跟踪
当人在图像中可见时,对象定位模块会绘制一个边界框。对象跟踪算法连接到对象定位模块的输出,以确定何时有人进入快照场景,量化在捕获摄像机前经过的人数。两种算法都使用称为“t”的时间度量来存储与边界框质心相关的信息。在下一个时间间隔“t+1”中,它使用以下参数关联两个检测到的质心:
- 最近的帧被认为是同一个对象。
- 当存储在内存中的前一帧和当前帧不匹配时,一个离开的对象被认为是“消失的”。
- 当没有检测到对象的先前帧时,对象被认为是“新的”。
- 考虑到质心在先前帧中的位置,计算质心之间的距离。
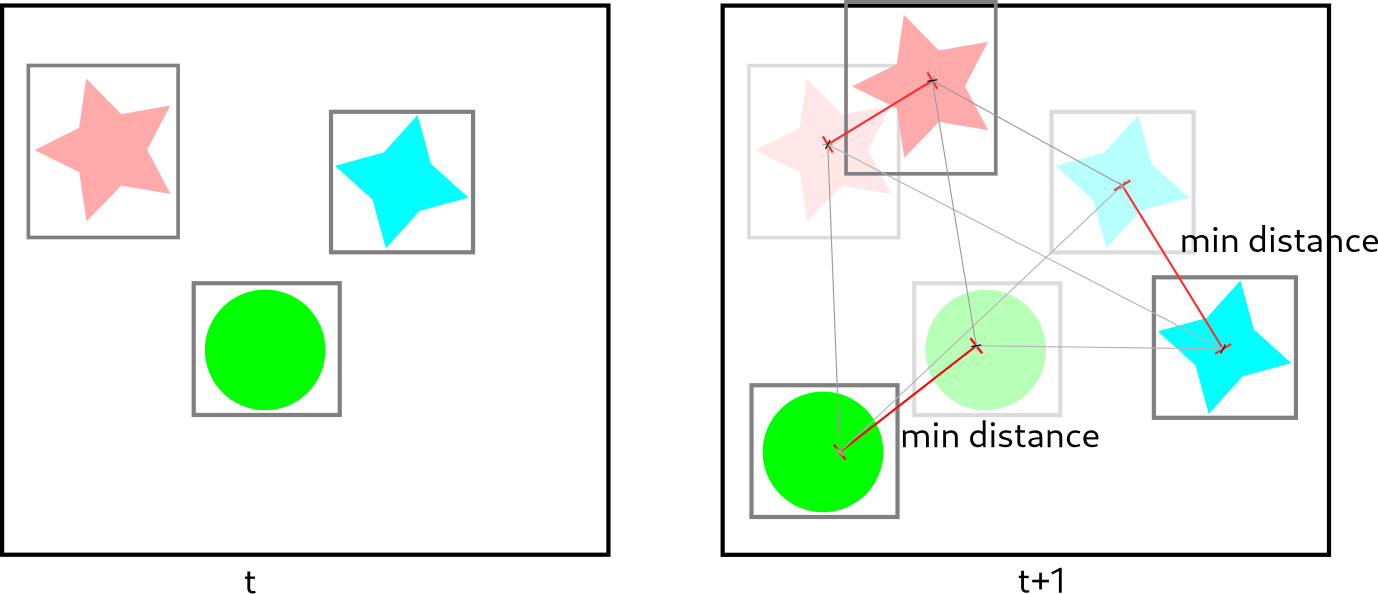
该算法的鲁棒性依赖于在保持与先前帧的质心位置相关的信息的基础上跟踪快照场景中多个对象的准确性。有关实现算法的更多详细信息,请参阅 pyimagesearch 的博客。
后端 - Flask 应用程序
后端 API 构建在 Flask Web 应用程序框架之上,它将 URL 路由链接到 Python 函数。本项目应用的主要路线有:
- ”/” 和 “/” 渲染来自静态前端应用程序的 html、css 和 js 文件。
- “/imgs/” 以 jpg 字节发送图像
- “/api/delete”删除本地图片
- “/api/single_image” 从相机捕获图像,如果需要运行对象检测算法,然后将其发送到前端。
- “/api/images”根据日期、时间和检测到的对象类型等输入过滤器发送图像列表。
- “/api/list_files” 用于计算每种过滤器的图像数量,例如日期、时间和检测到的对象类型。
前端
开发了一个基于 Angular 8 的 Web 应用程序来执行一些处理操作并直接从图像中提取信息。这个基于 Web 的应用程序通过 API 与后端应用程序交互,可以在没有主要限制的情况下加载保存的图像。
用户可以通过四个按钮与 Web 应用程序交互:
- 实时捕获模式用于动态修改每秒帧数,并执行对象检测和跟踪算法。
- 统计模式通过 ChartJS 图表即时查看快照的统计数据。此外,它还提供了以马赛克模式可视化照片的选项。
- Celery 任务模式可视化在处理阶段执行的循环异步任务。
- 按日期过滤马赛克照片的数据选择器。

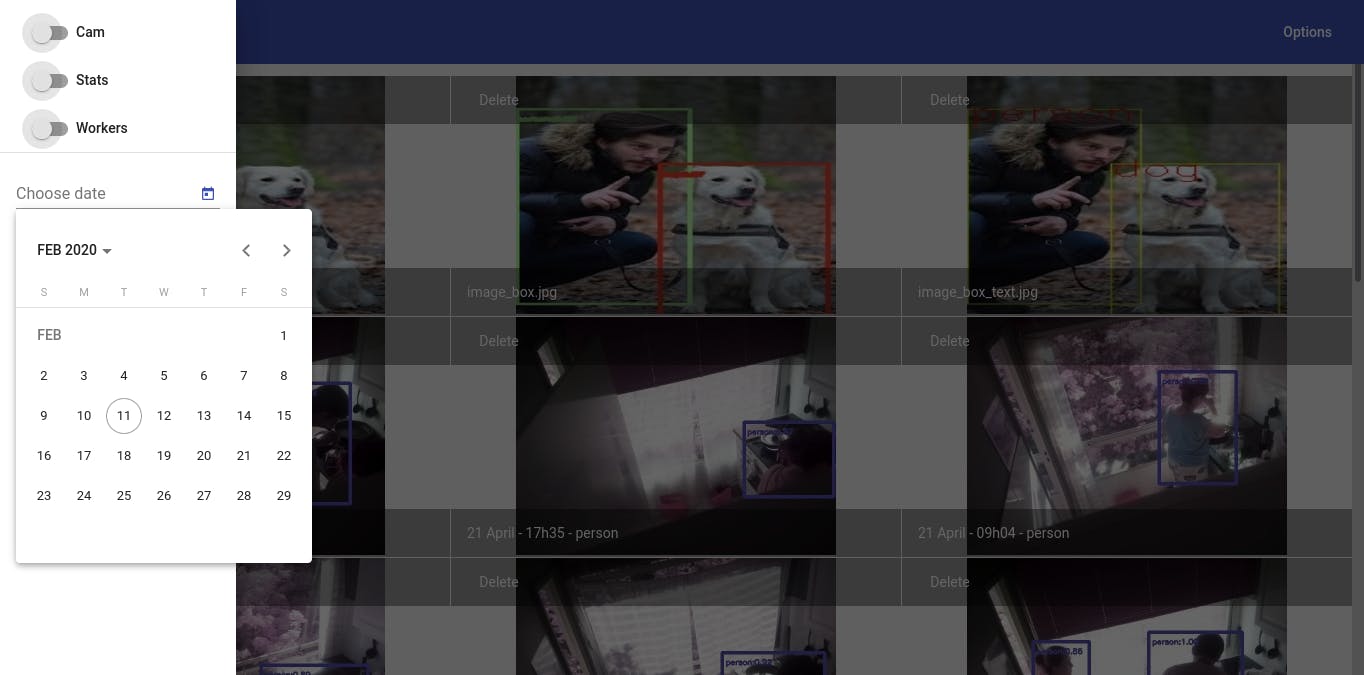
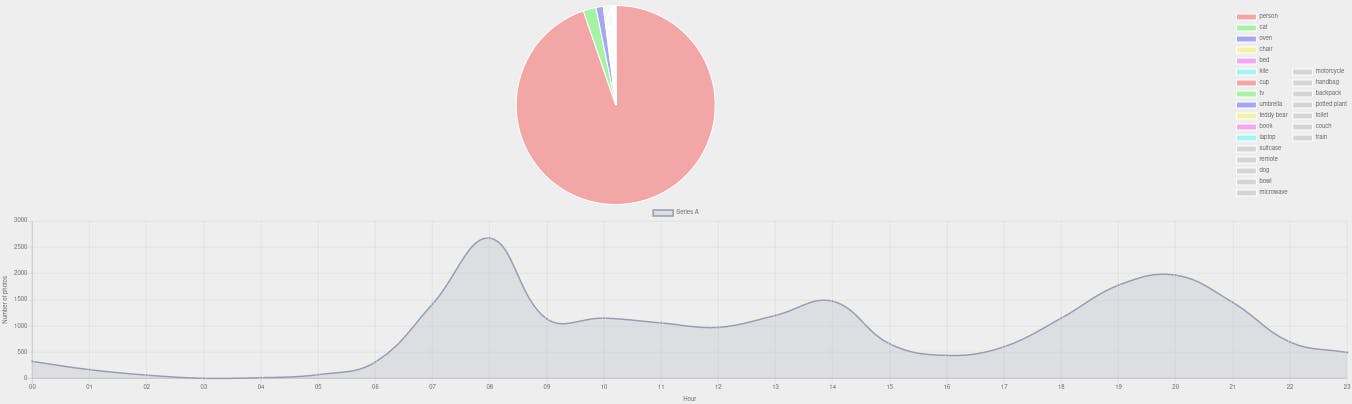
结果
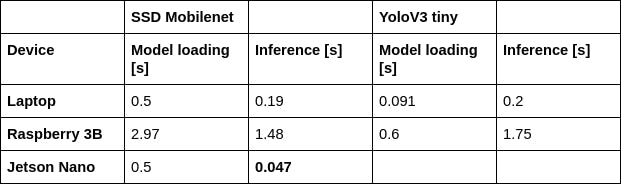
在许多深度学习用例中,算法的推理阶段是在边缘设备上完成的,而神经网络的训练阶段是在云端完成的。我们在三种不同的硬件架构上测试了对象检测应用程序的推理阶段:x86、ARM 和 Maxwell GPU。广泛使用的 Intel 和 AMD 处理器中的 x86 架构简化了深度学习算法的开发,因为许多库可用于执行对象检测任务。然而,由于严格的功耗限制,这种架构不适合物联网设备。另一方面,Raspberry Pi 内置的 ARM 处理器在实时检测阶段和干扰阶段都没有提供良好的性能。除了被其他架构超越之外,Raspberry Pi 的 ARM 内核需要持续冷却,以避免在神经网络训练期间发生节流。最后,集成在 NVIDIA 的 Jetson Nano 上的 Maxwell GPU 在性能和功耗之间提供了良好的平衡,因为基于 Tensor RT 框架构建的对象检测算法由于其被动冷却可以在很长一段时间内平稳执行系统和一个附加的外部风扇。一个突出的事实是,与 x86 架构相比,我们在 SSD Mobilenet 模型的推理阶段获得了更好的性能。下表显示了每个架构在训练和推理阶段的延迟结果:集成在 NVIDIA 的 Jetson Nano 上的 Maxwell GPU 在性能和功耗之间提供了良好的平衡,因为基于 Tensor RT 框架构建的对象检测算法由于其被动冷却系统可以在很长一段时间内平稳执行,并且一个附加的外部风扇。一个突出的事实是,与 x86 架构相比,我们在 SSD Mobilenet 模型的推理阶段获得了更好的性能。下表显示了每个架构在训练和推理阶段的延迟结果:集成在 NVIDIA 的 Jetson Nano 上的 Maxwell GPU 在性能和功耗之间提供了良好的平衡,因为基于 Tensor RT 框架构建的对象检测算法由于其被动冷却系统可以在很长一段时间内平稳执行,并且一个附加的外部风扇。一个突出的事实是,与 x86 架构相比,我们在 SSD Mobilenet 模型的推理阶段获得了更好的性能。下表显示了每个架构在训练和推理阶段的延迟结果:
对象跟踪是使用 Celery 任务管理器执行的。通过基于 Web 的应用程序内置的按钮,可以启动对象跟踪任务,检查后台运行的其他进程。
最后但并非最不重要的一点是,用于验证对象检测和跟踪的场景是办公室内的走廊,在正常工作日期间有 130 人经过。在下面的捕获编译中,读者可以观察到我们实现的结果。
结论
在这个项目的制定和部署过程中,我们了解了 NVIDIA 的 Jetson Nano 提供的许多优势,可以执行应用于真实场景中的对象检测和跟踪的深度学习任务。该设备成功地在长时间内识别和跟踪人员,而不会达到失控的内部温度。此外,它的小尺寸因素使其成为物联网应用的理想选择,因为它有助于在偏远或危险区域进行安装。
我们通过将神经网络的训练阶段卸载到服务器上,在边缘设备上维护推理阶段来展示边缘计算的概念。为了利用云上的计算,我们将数据从其来源(在本例中为 CSI 摄像机)移动到外部处理单元,克服了这种迁移的隐性挑战,例如延迟、可扩展性、隐私和动态网络内部的协调条件。
总之,我们的检测和跟踪深度学习算法的实施有效地解决了办公室场景的动态行为,而不会被大量的物体所淹没,在这种情况下,人们在一个普通的工作日出现。基于网络的应用程序通过引入简单的图像过滤器实现了进一步的图像处理。
最后,我们想强调的是,这只是深度学习算法的众多用例之一,在 NVIDIA 的 Jetson Nano 等强大平台上实施,可以提供解决社会日常问题的方法。通过添加更好的捕获设备、实施新的检测解决方案,或者在将数据迁移到云中的集中位置期间简单地建立新的漏洞条件,可以利用这项工作的许多扩展。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章




