
资料下载


形象的理解深度网络架构
分享资料个
在过去几年里,许多计算机视觉相关的深度学习的发展,都可以归结于少数几个神经网络架构。抛开所有关于数学、代码和实现的细节,来探索一个简单的问题:这些模型如何工作以及为什么工作?
在撰写这篇文章时,Keras 库(http://suo.im/4aLGEd)中已经涵盖了6种预训练模型,分别是:
VGG16
VGG19
ResNet50
Inception v3
Xception
MobileNet
▍VGG
VGG网络和从2012年早期的 AlexNet 网络一样,遵循着现有卷积网络的典型布局:在最终的全连接分类层(fully-connected classification layers)之前,由一系列的卷积层(convolutional layers),最大池化层(max-pooling layers)和激活层(activation layers)构成。
MobileNet 本质上是 Xception 架构,针对移动应用而优化的线性版本。剩下的三种架构则真正重新定义了我们看待深度网络的方式。
这篇文章接下来的部分将侧重于ResNet,Inception和Xception三种架构的直观理解,以及为什么它们成为计算机视觉中许多后续工作的基石。
▍ResNet
为什么深度网络在不断增加层的时候,表现反而变的更差?
直观来想, 更深层次的网络,应该不比较浅的网络表现的差,至少在训练的时候应该这样(这时没有过拟合over-fitting的风险)。
让我们作一个思维实验,假设我们已经建立了一个n层的网络,达到了一定的准确性。 如果仅通过复制相同的前n个层并对最后一层执行单位映射,则n + 1层的网络至少应该能够获得完全相同的精度。
类似地,n + 2,n + 3和n + 4层的网络都可以继续执行单位映射并获得相同的准确性。 然而,实际上,这些更深层的网络在性能上几乎都会有所下降。
ResNet的作者将这些问题归结为一个假设:直接映射难以学习。
他们提出了一个解决办法:用学习 x到 H(x) 两者之间的差异,或者“残差”的方式,替代尝试学习从x到 H(x) 的底层映射。这样,我们就可以可以通过输入残差来计算 H(x) 。
假设我们用 F(x)=H(x)-x 来表示残差。 ResNet 网络现在不是试图直接学习 H(x) , 而是学习 F(x)+x。
这引出了你可能知道的著名的ResNet(或“残差网络”)模块:
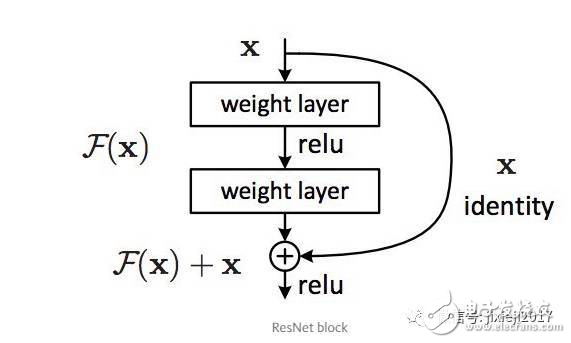
ResNet中的每个“模块”都由一系列层和一个“捷径”连接,捷径连接将模块的输入值直接添加到其输出值。 “添加”操作以元素对应方式执行,如果输入和输出的大小不同,可以使用补零法(zero-padding)或投影(通过1x1卷积)匹配尺寸。
回到我们的思维实验,捷径连接大大简化了我们对单位层的构建。 直观的看,学习将 F(x) 推到0并将输出值保留为x比从头开始学习单位交换(identity transformation)要容易得多。 一般情况下,ResNet为层提供了一个“参考”点—x—来开始学习。
这个想法在实践中效果惊人。在此之前,深度神经网络经常遇到梯度消失(vanishing gradients)的问题,来自误差函数的梯度信号随着它们向较早层反向传播而呈指数下降。
从本质上说,当误差信号一直传到到早期层时,它们已经小到网络无法进行学习了。然而,由于ResNet中的梯度信号可以通过捷径连接直接返回到早期层,突然间我们就可以建立 50层,101层,152层,甚至(想当然)1000+层的网络,而它们仍然表现良好。用22层的网络赢得了2014年ILSVRC挑战,这在当时是一个巨大的技术飞跃。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章



