
资料下载


×
HBase客户端实践重试机制
消耗积分:1 |
格式:rar |
大小:0.6 MB |
2017-10-10
分享资料个
现在,网易视频云与大家分享HBase客户端实践–重试机制。
在运维HBase的这段时间里,发现业务用户一方面比较关注HBase本身服务的读写性能:吞吐量以及读写延迟,另一方面也会比较关注HBase客户端使用上的问题,主要集中在两个方面:是否提供了重试机制来保证系统操作的容错性?是否有必要的超时机制保证系统能够fastfail,保证系统的低延迟特性?
这个系列我们集中介绍HBase客户端使用上的这两大问题,本文通过分析之前一个真实的案例来介绍HBase客户端提供的重试机制,并通过配置合理的参数使得客户端在保证一定容错性的同时还能够保证系统的低延迟特性。
案发现场
最近某业务在使用HBase客户端读取数据时出现了大量线程block的情况,业务方保留了当时的线程堆栈信息,如下图所示:
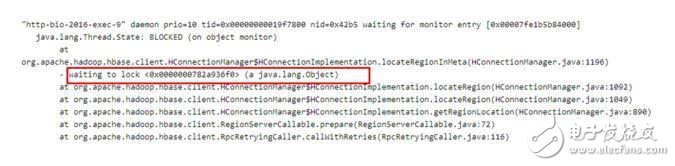
看到这样的问题,首先从日志和监控排查了业务表和region server,确认了在很长时间内确实没有请求进来,除此之外并没有其他有用的信息,同时也没有接到该集群上其他用户的异常反馈,从现象看,这次异常是在特定环境下才会触发的。
案件分析过程
1.根据上图图1所示,所有的请求都block在《0x0000000782a936f0》这把全局锁上,这里需要关注两个问题:
哪个线程持有了这把全局锁《0x0000000782a936f0》?
这是一把什么样的全局锁(对于问题本身并不重要,有兴趣可以参考步骤3)?
2.哪个线程持有了这把锁?
2.1 很容易在jstack日志中通过搜索找到全局锁《0x0000000782a936f0》被如下线程持有:
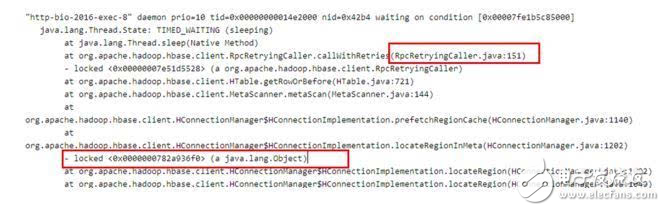
定睛一看,该线程持有了这把全局锁,而且处于TIMED_WAITING状态,因此这把锁可能长时间不释放,导致所有需要这把全局锁的线程都阻塞等待。好了,那问题就转化成了:为什么这个线程会处于TIME_WAITING状态?
2.2 根据上图提示,查看源码中RpcRetryingCall.java的115行代码,可以确定该线程处于TIME_WAITING状态是因为自己休眠导致,如下图所示:
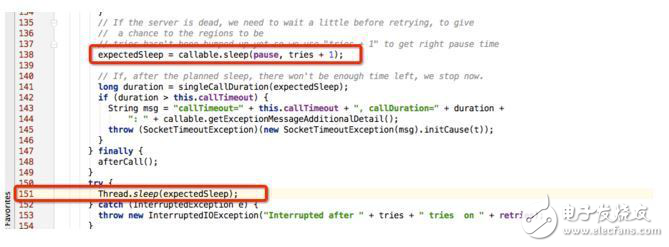
RpcRetryingCall函数是Rpc请求重试机制的实现,所以可以有两点推断:
HBase客户端请求在那个时间段网络有异常导致rpc请求失败,进入重试逻辑
根据HBase的重试机制(退避机制),每两次重试机制之间会休眠一段时间,即上图115行代码,这个休眠时间太长导致这个线程一直处于TIME_WAITING状态。
休眠时间由上图中expectedSleep = callable.sleep(pause,tries + 1)决定,根据hbase算法(见第三部分),默认最大的expectedSleep为20s,整个重试时间会持续8min,这也就是说全局锁会被持有8min,可这并不能解释持续将近几个小时的阻塞无请求。除非有两种情况:
配置有问题:需要客户端检查hbase.client.pause和hbase.client.retries.number两个参数配置出现异常,比如hbase.client.pause参数如果手抖配成了10000,就有可能出现几个小时阻塞的情况
网络持续有问题:如果线程1持有全局锁重试失败之后退出,线程2竞争到这把锁,此时网络依然有问题,线程2会再次进入重试,重试8min之后失败退出,循环下去,也有可能出现几个小时阻塞的情况
和业务方确认配置,所有参数基本属于默认配置,因此猜测一不成立,那最有可能的情况就是猜测二。经过确认,在事发当时(凌晨0点~早上6点)确实存在很多服务因为云网络升级异常发生抖动的情况出现。然而因为没有具体的日志信息,所以并不能完全确认猜测是否正确。但是,通过问题的分析可以进一步明白HBase重试机制以及部分客户端参数优化策略,这也是写这篇文章的初衷之一。
在运维HBase的这段时间里,发现业务用户一方面比较关注HBase本身服务的读写性能:吞吐量以及读写延迟,另一方面也会比较关注HBase客户端使用上的问题,主要集中在两个方面:是否提供了重试机制来保证系统操作的容错性?是否有必要的超时机制保证系统能够fastfail,保证系统的低延迟特性?
这个系列我们集中介绍HBase客户端使用上的这两大问题,本文通过分析之前一个真实的案例来介绍HBase客户端提供的重试机制,并通过配置合理的参数使得客户端在保证一定容错性的同时还能够保证系统的低延迟特性。
案发现场
最近某业务在使用HBase客户端读取数据时出现了大量线程block的情况,业务方保留了当时的线程堆栈信息,如下图所示:
看到这样的问题,首先从日志和监控排查了业务表和region server,确认了在很长时间内确实没有请求进来,除此之外并没有其他有用的信息,同时也没有接到该集群上其他用户的异常反馈,从现象看,这次异常是在特定环境下才会触发的。
案件分析过程
1.根据上图图1所示,所有的请求都block在《0x0000000782a936f0》这把全局锁上,这里需要关注两个问题:
哪个线程持有了这把全局锁《0x0000000782a936f0》?
这是一把什么样的全局锁(对于问题本身并不重要,有兴趣可以参考步骤3)?
2.哪个线程持有了这把锁?
2.1 很容易在jstack日志中通过搜索找到全局锁《0x0000000782a936f0》被如下线程持有:
定睛一看,该线程持有了这把全局锁,而且处于TIMED_WAITING状态,因此这把锁可能长时间不释放,导致所有需要这把全局锁的线程都阻塞等待。好了,那问题就转化成了:为什么这个线程会处于TIME_WAITING状态?
2.2 根据上图提示,查看源码中RpcRetryingCall.java的115行代码,可以确定该线程处于TIME_WAITING状态是因为自己休眠导致,如下图所示:
RpcRetryingCall函数是Rpc请求重试机制的实现,所以可以有两点推断:
HBase客户端请求在那个时间段网络有异常导致rpc请求失败,进入重试逻辑
根据HBase的重试机制(退避机制),每两次重试机制之间会休眠一段时间,即上图115行代码,这个休眠时间太长导致这个线程一直处于TIME_WAITING状态。
休眠时间由上图中expectedSleep = callable.sleep(pause,tries + 1)决定,根据hbase算法(见第三部分),默认最大的expectedSleep为20s,整个重试时间会持续8min,这也就是说全局锁会被持有8min,可这并不能解释持续将近几个小时的阻塞无请求。除非有两种情况:
配置有问题:需要客户端检查hbase.client.pause和hbase.client.retries.number两个参数配置出现异常,比如hbase.client.pause参数如果手抖配成了10000,就有可能出现几个小时阻塞的情况
网络持续有问题:如果线程1持有全局锁重试失败之后退出,线程2竞争到这把锁,此时网络依然有问题,线程2会再次进入重试,重试8min之后失败退出,循环下去,也有可能出现几个小时阻塞的情况
和业务方确认配置,所有参数基本属于默认配置,因此猜测一不成立,那最有可能的情况就是猜测二。经过确认,在事发当时(凌晨0点~早上6点)确实存在很多服务因为云网络升级异常发生抖动的情况出现。然而因为没有具体的日志信息,所以并不能完全确认猜测是否正确。但是,通过问题的分析可以进一步明白HBase重试机制以及部分客户端参数优化策略,这也是写这篇文章的初衷之一。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章




下载排行榜
- 暂无相关数据

