
资料下载


×
探索性大数据分析系统对基因组医学研究的帮助
消耗积分:1 |
格式:rar |
大小:0.6 MB |
2017-10-11
分享资料个
基于高性能计算集群这样的新一代测序器和快速演化分析平台,基因研究领域已经被海量数据淹没。众多基因、癌症、医学研究机构和制药公司不断产生的海量数据,已不再能被及时的处理并恰当的存储,甚至通过常规通讯线路进行传输都变得困难。而通常情况下,这些数据必须能被快速存储、分析、共享和归档,以适应基因研究的需要。于是他们不得不诉诸于磁盘驱动器及运输公司,来转移原始数据到国外的计算中心,这为快速访问和分析数据带来了巨大障碍。与规模和速度同等重要的是,所有基因组信息都能基于数据模型和类别被链接,并以机器或人类语言进行标注,这样智能化的数据就能被分解成方程式,在处理基因、临床和环境数据时应用于普通分析平台。
概述
机遇与挑战并存的基因组医学革命
自人类启动基因组计划以来,各项工程已逐步开始揭示人类基因组与疾病间关联的奥秘。随着测序技术的不断进步,仅用1000美元即可识别出基因组。

图1 基因组医学技术进步的十年
人类基因组计划是首个用来确定人类基因组序列的科研项目。该项目历时13年,耗费近30亿美元,于2003年完成,是目前为止最大的生物学合作项目。从那时起,一系列的技术进步在DNA测序和大规模基因组数据分析中展露头脚,对单个人类全基因组进行测序的时间和成本随之急剧下降,下降速度甚至超过了摩尔定律。
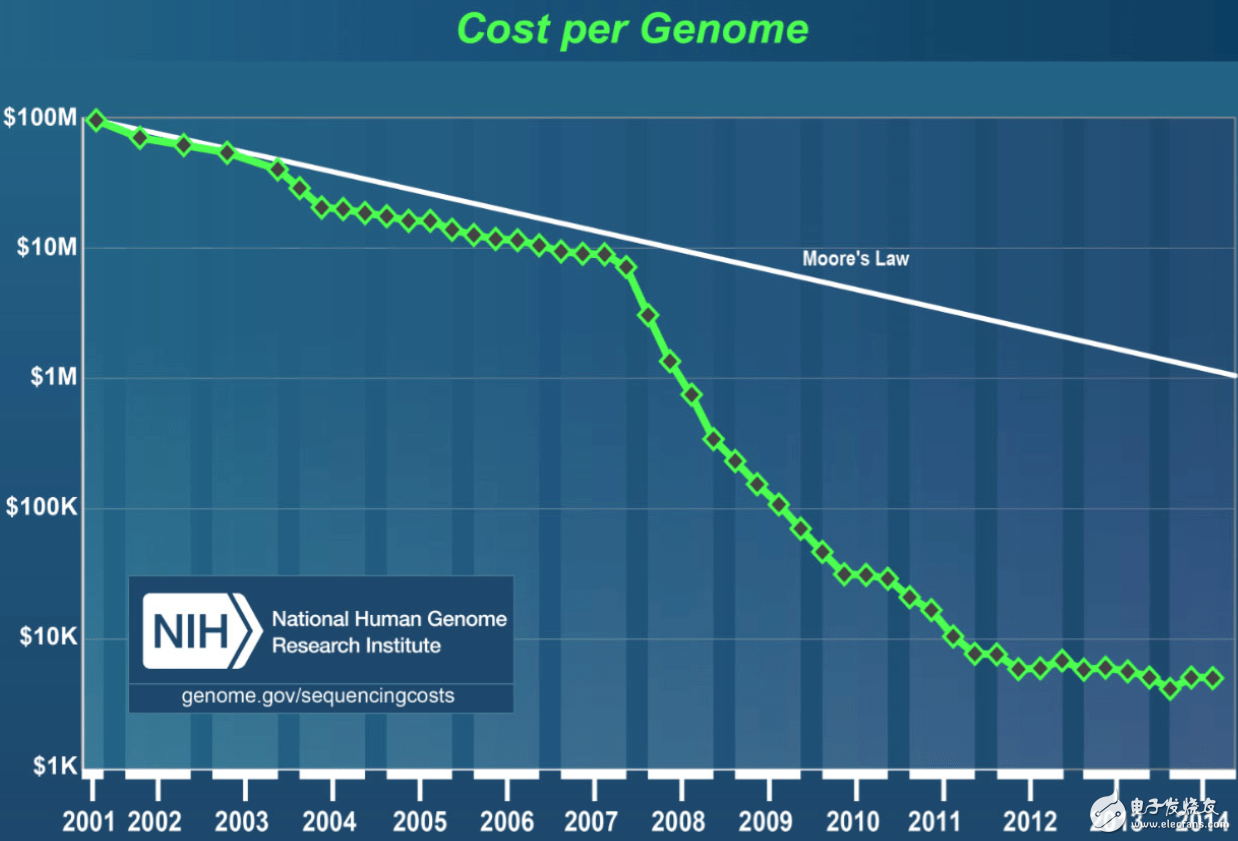
图2 DNA测序成本的快速下降
(自2001年以来,美国国家人类基因组研究所(NHGRI)对由美国国立卫生研究院(NIH)资助的测序中心所进行的所有DNA测序工作进行了跟踪,并统计了相关费用,这些信息已作为DNA测序的重要改进评估基准。图中展现出近年来DNA测序技术和数据产生流程的显著改善。来源:NHGRI,http://www.genome.gov/sequencingcosts/)
作为测序技术进步的一个例子,Illumina公司在2014年发布了新一代测序器HiSeq X10,它以每个基因组仅1000美元的成本,一年可解密18000个人类全基因组。这个所谓的“千元基因组技术”使人类全基因组测序比以往任何时候更廉价可行,并有望对医疗保健和生命科学行业产生巨大影响。
新技术和研究方法的成功同样带来了相当大的成本,海量数据成为亟待解决的难题:
基因组数据在过去的8年中,每5个月翻一番。基因编码项目为80%的基因组赋予了明确的含义,所以获取全基因组序列变得尤为重要。癌症基因组研究揭示了一组不同的癌细胞基因变体,通过全基因组测序的跟踪和监控,每次分析都会产生约1TB的数据。已有越来越多的国家启动了基因组测序项目,如美国、英国、中国和卡塔尔。这些项目动辄就会产生数以百PB级的测序数据。
对端到端架构的要求
为了满足基因医药研究对于速度、规模和智能化的苛刻要求,需要端到端参考架构涵盖基因计算的关键功能,如数据管理(数据集线器),负载编排(负载编排器)和企业接入(应用中心)等。为了确定参考架构(能力与功能)和映射解决方案(硬件与软件)的内容和优先级,需要遵循以下三个主要原则:
软件定义:即基于软件的抽象层进行计算、存储和云服务,以此定义基础架构和部署模式,以便在未来通过数据量和计算负载的积累进行基因组基础设施的增长和扩展。数据中心:以数据管理功能面向基因组研究、成像和临床数据的爆炸式增长。应用就绪:整合多种应用到一致的环境,提供数据管理、版本控制、负载管理、工作流编排,以及通过访问执行和监控等多种功能。
概述
机遇与挑战并存的基因组医学革命
自人类启动基因组计划以来,各项工程已逐步开始揭示人类基因组与疾病间关联的奥秘。随着测序技术的不断进步,仅用1000美元即可识别出基因组。
图1 基因组医学技术进步的十年
人类基因组计划是首个用来确定人类基因组序列的科研项目。该项目历时13年,耗费近30亿美元,于2003年完成,是目前为止最大的生物学合作项目。从那时起,一系列的技术进步在DNA测序和大规模基因组数据分析中展露头脚,对单个人类全基因组进行测序的时间和成本随之急剧下降,下降速度甚至超过了摩尔定律。
图2 DNA测序成本的快速下降
(自2001年以来,美国国家人类基因组研究所(NHGRI)对由美国国立卫生研究院(NIH)资助的测序中心所进行的所有DNA测序工作进行了跟踪,并统计了相关费用,这些信息已作为DNA测序的重要改进评估基准。图中展现出近年来DNA测序技术和数据产生流程的显著改善。来源:NHGRI,http://www.genome.gov/sequencingcosts/)
作为测序技术进步的一个例子,Illumina公司在2014年发布了新一代测序器HiSeq X10,它以每个基因组仅1000美元的成本,一年可解密18000个人类全基因组。这个所谓的“千元基因组技术”使人类全基因组测序比以往任何时候更廉价可行,并有望对医疗保健和生命科学行业产生巨大影响。
新技术和研究方法的成功同样带来了相当大的成本,海量数据成为亟待解决的难题:
基因组数据在过去的8年中,每5个月翻一番。基因编码项目为80%的基因组赋予了明确的含义,所以获取全基因组序列变得尤为重要。癌症基因组研究揭示了一组不同的癌细胞基因变体,通过全基因组测序的跟踪和监控,每次分析都会产生约1TB的数据。已有越来越多的国家启动了基因组测序项目,如美国、英国、中国和卡塔尔。这些项目动辄就会产生数以百PB级的测序数据。
对端到端架构的要求
为了满足基因医药研究对于速度、规模和智能化的苛刻要求,需要端到端参考架构涵盖基因计算的关键功能,如数据管理(数据集线器),负载编排(负载编排器)和企业接入(应用中心)等。为了确定参考架构(能力与功能)和映射解决方案(硬件与软件)的内容和优先级,需要遵循以下三个主要原则:
软件定义:即基于软件的抽象层进行计算、存储和云服务,以此定义基础架构和部署模式,以便在未来通过数据量和计算负载的积累进行基因组基础设施的增长和扩展。数据中心:以数据管理功能面向基因组研究、成像和临床数据的爆炸式增长。应用就绪:整合多种应用到一致的环境,提供数据管理、版本控制、负载管理、工作流编排,以及通过访问执行和监控等多种功能。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章






