
资料下载


基于Hadoop集群的自然语言处理平台实现
分享资料个
随着互联网技术的迅猛发展,数据的智能化处理获取越来越重要。在自然语言处理领域,大规模语料库技术和其他基于概率统计的研究方法蓬勃发展,为自然语言的研究提供了新的思路和工具。各种新模型、新技术、新应用层出不穷,对计算机的计算和存储能力提出了更高的要求。当前流行的一些数据密集型的计算方法,处理过程比较复杂,处理耗时较长。如对大规模语料进行word2vec模型训练,往往一次就需要数天时间。传统的单机计算模式,其计算速度和存储能力不能满足大规模数据处理的需求。
目前,现有的算法成果主要是各种程序包,一般对应某种编程语言,包含一个或多个功能,针对特定领域,具有较高的处理效率和精确度。使用前需要先下载相应的工具包,再针对所处理的语言、计算机硬件环境和具体处理需求等进行参数配置。这种方法需要算法使用者维护数据文件和执行文件,还要掌握相应的编程语言。由于开发习惯不尽相同,不同程序包内文件组成方式千差万别,参数配置过程复杂且不通用,不便于使用者学习掌握,提高了使用的门槛。
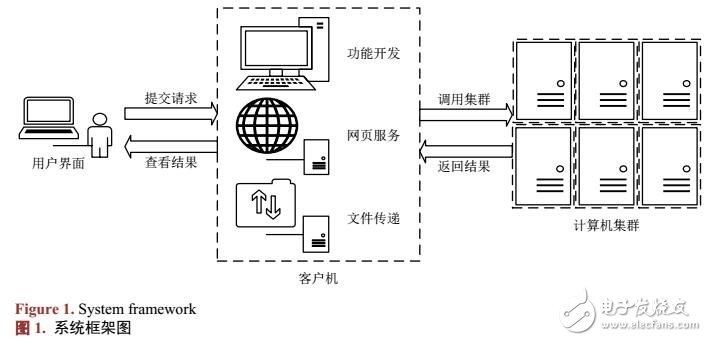
综合考虑上述情况,提出建设自然语言处理平台的方案。借助Hadoop集群,解决大规模数据存储的问题,同时提升计算能力;使用插件式的应用开发棋式,整合改进自然语言处理领域的各种成熟算法,缩短了产品开发周期;实现友好的交互界面,用户通过便捷的操作,即可上传数据,调用算法,得到处理结果。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章




