
资料下载


×
两级分类实现车牌字符识别
消耗积分:1 |
格式:rar |
大小:0.4 MB |
2017-11-30
分享资料个
车牌识别系统LPR(License Plate Recognition)包括车牌定位、字符分割和字符识别三大部分。其中,字符识别的准确及高效成为整个车牌识别系统的关键。
车牌字符识别是模式识别的一个重要研究领域,字符特征提取可分为基于统计特征和基于结构特征两大类[1],统计方法具有良好的鲁棒性和抗干扰性等,但是,由于其采用累加的方法,对于“敏感部位”的差异也随之消失,即对形近字的区分能力较差。而结构方法对细节特征较敏感,区分形近字符的能力较强,但是难以抽取、不稳定、算法复杂度高。分类器设计方面,人工神经网络和支持向量机SVM(Support Vector Machine)[2]等技术已被用于车牌字符识别研究中,有效地提高了识别率,但缺少基于特征的优化设计。
本文针对实际采集的车牌图像质量不高所导致的字符形变、噪声、易混淆的问题,根据人类视觉活动的问题,选取基于轮廓的统计特征反映字符整体信息;选取结构特征反映字符细节信息,采用SVM作为分类器,并对基于轮廓的特征提取方法进行了优化设计。
1 车牌字符识别算法框架
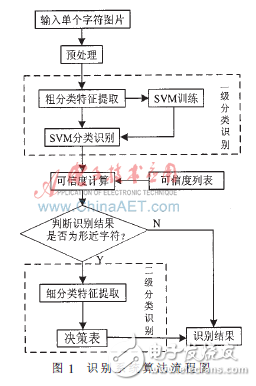
本文提出的识别算法模拟人类智能,采用两级分类识别的思想处理车牌字符识别问题,引入可信度评判机制。经预处理后的字符首先进入粗分类识别,采用基于轮廓的统计特征作为粗分类的特征提取方法,利用SVM分类器得出分类识别结果,并计算结果的可信度。识别系统将粗分类识别结果的可信度与预先设置好的用于判别形近字的可信度阈值相比较,如果可信度大于阈值,则识别系统将字符归为非形近字,并将结果输出;否则, 识别系统将字符归为形近字,并根据粗分类识别结果,计算字符所属的形近字类别,将字符送入细分类识别,提取字符的结构特征作为细分类的特征提取方法,利用决策表中的形近字区分规则,得到识别结果。图1为识别系统算法流程图。
2 一级分类识别
2.1 粗分类特征提取
粗分类的特征提取方法应该能够描绘字符的整体信息,基于轮廓的统计特征描绘字符外围轮廓的变化。利用距离反映轮廓的方法,通过计算字符图像左、右、上、下四个边框到笔画间的距离,得到图像轮廓的统计特征。设预处理后的二值化字符图像为f(i,j),具体算法为:

其中,width、length为字符图像的宽和高。规定此行或此列没有笔画时,其特征值为零。
车牌字符识别是模式识别的一个重要研究领域,字符特征提取可分为基于统计特征和基于结构特征两大类[1],统计方法具有良好的鲁棒性和抗干扰性等,但是,由于其采用累加的方法,对于“敏感部位”的差异也随之消失,即对形近字的区分能力较差。而结构方法对细节特征较敏感,区分形近字符的能力较强,但是难以抽取、不稳定、算法复杂度高。分类器设计方面,人工神经网络和支持向量机SVM(Support Vector Machine)[2]等技术已被用于车牌字符识别研究中,有效地提高了识别率,但缺少基于特征的优化设计。
本文针对实际采集的车牌图像质量不高所导致的字符形变、噪声、易混淆的问题,根据人类视觉活动的问题,选取基于轮廓的统计特征反映字符整体信息;选取结构特征反映字符细节信息,采用SVM作为分类器,并对基于轮廓的特征提取方法进行了优化设计。
1 车牌字符识别算法框架
本文提出的识别算法模拟人类智能,采用两级分类识别的思想处理车牌字符识别问题,引入可信度评判机制。经预处理后的字符首先进入粗分类识别,采用基于轮廓的统计特征作为粗分类的特征提取方法,利用SVM分类器得出分类识别结果,并计算结果的可信度。识别系统将粗分类识别结果的可信度与预先设置好的用于判别形近字的可信度阈值相比较,如果可信度大于阈值,则识别系统将字符归为非形近字,并将结果输出;否则, 识别系统将字符归为形近字,并根据粗分类识别结果,计算字符所属的形近字类别,将字符送入细分类识别,提取字符的结构特征作为细分类的特征提取方法,利用决策表中的形近字区分规则,得到识别结果。图1为识别系统算法流程图。
2 一级分类识别
2.1 粗分类特征提取
粗分类的特征提取方法应该能够描绘字符的整体信息,基于轮廓的统计特征描绘字符外围轮廓的变化。利用距离反映轮廓的方法,通过计算字符图像左、右、上、下四个边框到笔画间的距离,得到图像轮廓的统计特征。设预处理后的二值化字符图像为f(i,j),具体算法为:
其中,width、length为字符图像的宽和高。规定此行或此列没有笔画时,其特征值为零。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章





