
资料下载


×
基于中文微博情感分析研究设计及实现
消耗积分:2 |
格式:rar |
大小:4.51 MB |
2017-12-22
分享资料个
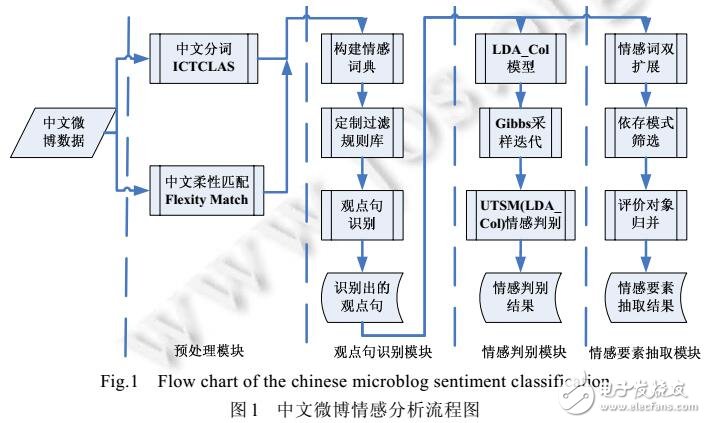
中文微博的大数据、指数传播和跨媒体等特性,决定了依托人工方式监控和处理中文微博是不现实的,迫切需要依托计算机开展中文微博情感自动分析研究.该项研究可分为3个任务:中文微博观点句识别、情感倾向性分类和情感要素抽取.为完成上述任务,研制了一个评测系统:通过构建多级词库、制定成词规则、开展串频统计等给出一种基于规则和统计的新词识别方法,在情感词和评价对象的依存模式的基础上给出基于词语特征的观点句识别算法;以词序流表示文本的LDA-Collocation模型,采用吉布斯抽样法推导了算法,实现中文微博情感倾向性自动分类;针对中文微博情感要素抽取召回率较低的问题,利用依存关系分析理论。按主语类和宾语类把依存模式分为两类,建立了6个优先级的评价对象和情感词汇的依存模式,通过评价对象归并算法实现计算机自动抽取情感要素.实验包括两个部分:一是参加NLP&CC2012的公开评测,所提方法在微博观点句识别任务中的准确率为第2,在中文微博情感要素抽取任务中的准确率和F值均为第2,验证了该算法的实用性;二是在分析公开评测结果的基础上,分别比较了参加公开评测的各类算法在处理中文微博情感分析时的效率,给出了相关结论,
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章



