


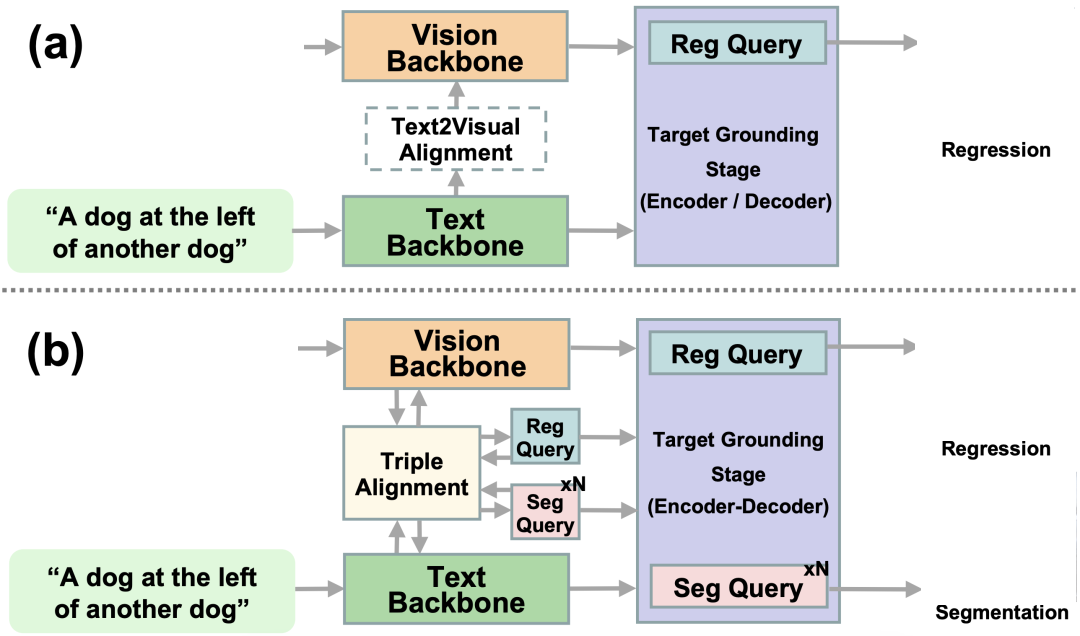
SegVG视觉定位方法的各个组件
详解E2E-MFD多模态融合检测端到端算法
Vision Mamba:速度与内存的双重突破

Adobe提出DMV3D:3D生成只需30秒!让文本、图像都动起来的新方法!

高分工作!Uni3D:3D基础大模型,刷新多个SOTA!

ICLR 2024 清华/新国大/澳门大学提出一模通吃的多粒度图文组合检索MUG:通过不确定性建模,两行代码完成部署

Harvard FairSeg:第一个用于医学分割的公平性数据集

谷歌MIT最新研究证明:高质量数据获取不难,大模型就是归途

顶刊TIP 2023!浙大提出:基于全频域通道选择的的无监督异常检测
北京大学提出Repaint123:纹理质量、多视角一致性新SOTA!

基于DiAD扩散模型的多类异常检测工作
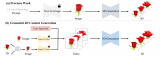
4DGen:基于动态3D高斯的可控4D生成新工作
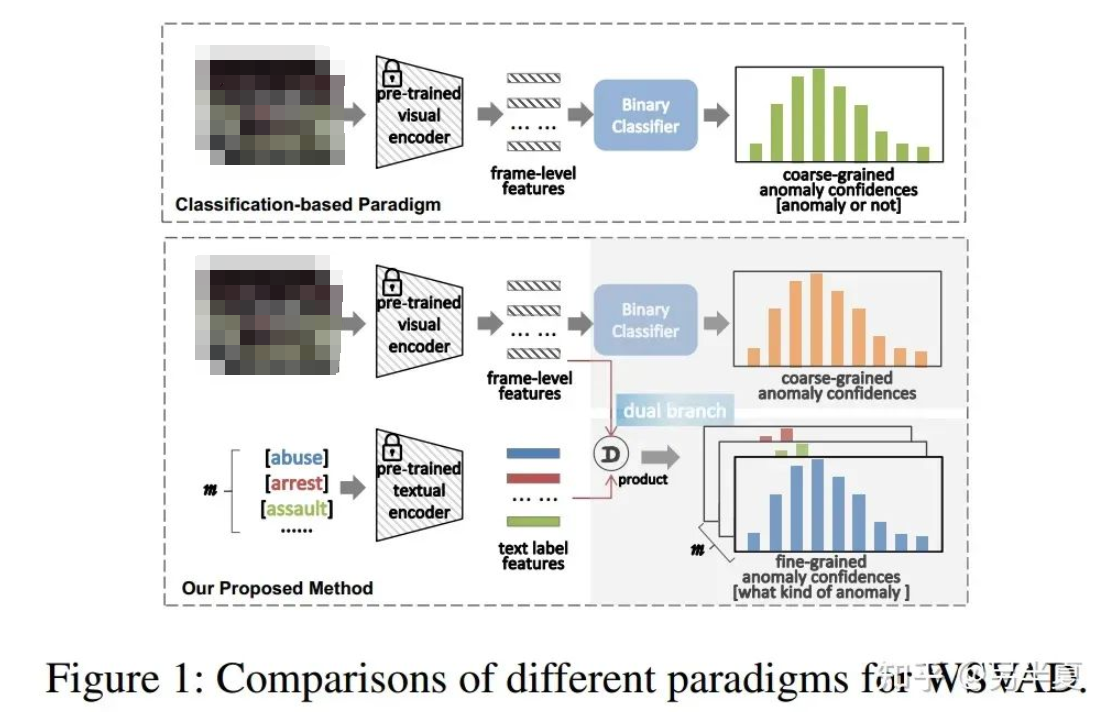
语言模型的弱监督视频异常检测方法

SegRefiner:通过扩散模型实现高精度图像分割
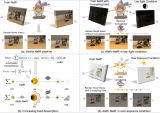
Aleth-NeRF:低光增强与曝光纠正的新方向!不良光照场景下的新视角合成

没有证据证实LK-99为常温超导体

更强!Alpha-CLIP:让CLIP关注你想要的任何地方!
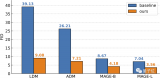
何恺明新作RCG:无自条件图像生成新SOTA!与MIT首次合作!

计算机视觉迎来GPT时刻!UC伯克利三巨头祭出首个纯CV大模型!

超分画质大模型!华为和清华联合提出CoSeR:基于认知的万物超分大模型