
资料下载


×
基于哈希算法和近邻算法的缓存数据选择策略
消耗积分:0 |
格式:pdf |
大小:2.30 MB |
2021-04-19
分享资料个
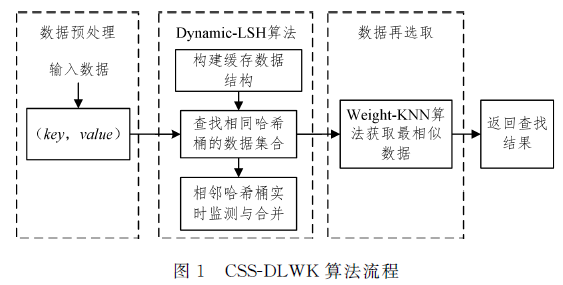
针对终端用户产生大量相同或相似计算请求的情况,可以通过近似匹配在边缘服务器缓存空间中查找相似数据,选取可复用的计算结果。现有算法大多未考虑数据分布不均的问题,导致计算量和时间开销较大,对此文中提出基于动态局部敏感哈希算法与加权k近邻算法的缓存数据选择策略( Cache Selection Strategy based on Dynamic- LSH algorithm and Weighted-KNN algorithm,CSS-DLWK)。其中, Dynamic-LSH算法能够针对数据分布不均的问题,根据数据分布的变化动态调整哈希桶粒度,从缓存空间中选出与输入数据相似的数据集合; Weighted-knn算法以距离和样本数为权重,对由 Dynamic-LSH算法获取的相似数据集合进行数据再选取,得到与输入数据最相似的数据,获取相应的计算结釆以供复用。仿真实验结果表明,在CIFAR-10数据集中,与基于A-LSH算法与H-KNN算法的缓存选取策略相比,CSS-DLWK策略的平均选取准确率提高了4.1%;与传统的LSH算法相比,其平均选取准确率提高了16.8%。¢SS-DLWK策略能够在可接受的数据选取时间开销内,有效地提高可复用数据选取的准确率,从而减少边缘服务器的重复计算。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章




