


Kaggle 是一个网站流量预测项目,项目采用Python语言开发,可以给大家的流量预测建模提供一些思路。
数据模型
Kaggle的训练数据集由大约14.5万套时间序列组成,每一套时间序列代表的是每天不同维基百科文章页的浏览次数,时间记录的周期为2015年7月1日到2017年9月10日。而我们的目标是为了预测2017年9月13日到2017年11月13日之间每天的页面浏览量。其中,需要检测的流量包括移动端、桌面端以及爬虫流量。
注:模型的评价指标为SMAPE。
测评方法
使用了一个单一的神经网络来对14.5万套时间序列进行建模,该模型架构跟WaveNet非常相似,主要由扩展卷积和因果卷积网络组成,整个概念如下图所示:

为了让数据模型适应并生成整个64天的相干预测值,我们还需要对模型进行一些修改。为了在条件信息不足的情况下尽量减少错误序列信息的生成,我们采用了一种“序列-序列”的方法,其中的编码器和解码器不会共享参数。这样一来,我们就可以在模型生成长序列的情况下让解码器来负责处理积累的噪声了。
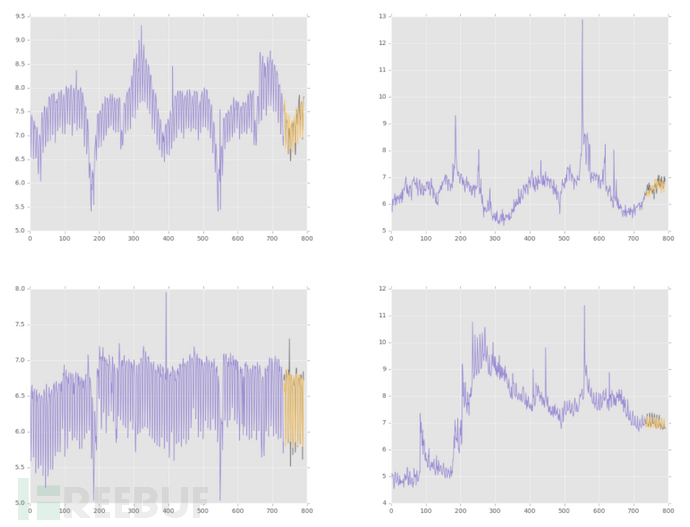
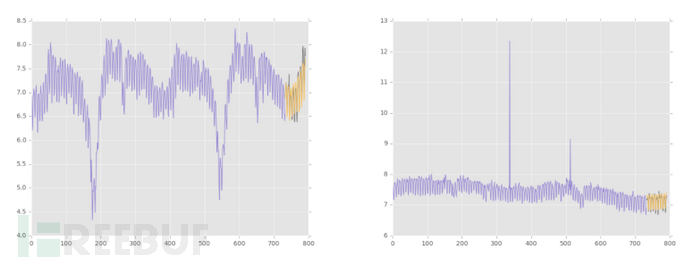
下面给出的是一些样本预测,并演示了一些可以捕捉和预测的网络模型。其中,预测值为黄色,灰色的是真实数据值,Y轴为对数变换:
配置要求
12 GBGPU(建议)+Python2.7
Python数据包:
numpy==1.13.1
pandas==0.19.2
scikit-learn==0.18.1
tensorflow==1.3.0
介绍内容来自 FreeBuf




