
资料下载


J-Eye:用于自主注射的肌内部位检测
王军
分享资料个
描述
介绍
COVID-19 大流行仍在全球范围内蔓延。它在许多方面影响了人类生活,并对公共卫生、全球交通系统和许多领域提出了前所未有的挑战。大多数政府已实施封锁政策并限制国际旅行,以减轻病毒的传播。虽然事实是目前还没有灵丹妙药能够对抗病毒,但接种疫苗仍然是目前减轻病毒死亡率和发病率的最有效手段之一。
然而,全球疫苗接种率仍然很低,尤其是在低收入国家,因为他们获得医疗资源和资金的机会有限。据世卫组织称,低收入国家只有 14.5% 的人口至少接受过一剂疫苗。许多非洲国家的疫苗接种率甚至更低,包括乍得、马达加斯加和坦桑尼亚,其免疫接种率仅为 1.5% 至 4% [1]。提供低成本的疫苗接种解决方案既紧迫又具有挑战性。开发疫苗本身成本高昂,而另一个成本高昂的组成部分是疫苗接种本身,这需要额外的资源,例如额外的医务人员和额外的医疗费用。此外,传统的疫苗接种无疑会增加病毒传播的风险和医护人员的工作量。
总而言之,当前的临床需求清楚地表明,在持续的大流行仍然威胁着全球社会并采取了看不见的措施(包括社会疏远和封锁)的时候,迫切需要安全和足够的疫苗覆盖率。
自主注射机器人
自主机器人注射作为一种安全有效的解决方案,可以在无人的环境中提供疫苗,人们只需走进去并将手臂伸入一个封闭的空间。最近,开发了几个这样的原型,它们在下面简要列出。
Cobi:滑铁卢开发了 Cobi,这是世界上第一个自主机器人无针注射。借助激光雷达传感器和人工智能位置跟踪,Cobi 能够识别人体。然后,如下图所示,360度深度感知将无用机械臂引导至患者手臂上的注射部位进行药物输送。[2]

后羿:如下图所示,上海同济大学研发的自动疫苗注射机器人,也可以通过3D人体建模,自动识别人体上的指定注射位置。识别算法将摄像头拾取的3D点与3D模型上的对应部位进行拟合,然后给出注射点。[3, 4]

值得一提的是,两种解决方案均采用无针疫苗接种,确保安全无痛注射。这些机器人的另一个关键要素是能够以智能方式检测正确的注射部位。在这两种情况下,都使用配备多维传感器的复杂 3D 模型识别算法来完成检测任务。虽然这些算法可以提供准确的站点检测,但它们也涉及大量的开发工作、昂贵的传感技术和昂贵的相机。这些都增加了这些机器人的总成本。在这个项目中,我们声称为自主注射部位提出一种低成本但有效的解决方案很重要,并且可以有所作为用于将机器人部署到世界不同地区。我们先来了解一下注射部位通常在手臂上的什么位置。
肌肉注射部位
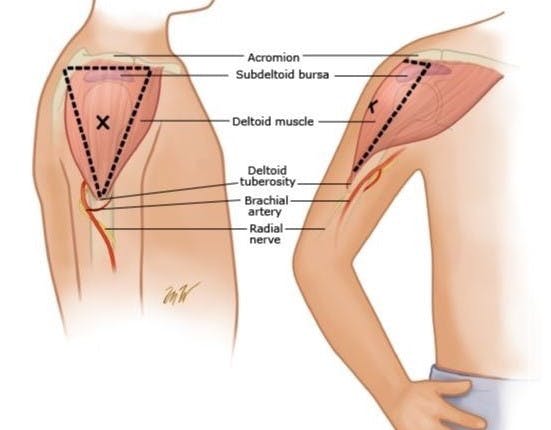
目前的 COVID-19 疫苗主要是肌肉注射,因为肌肉具有良好的血管分布,可以使注射迅速参与全身循环。综合考虑,三角肌(如下图)是最适合接种疫苗的部位,因为它的血液供应充足,面积大[5]。根据该图,我们咨询了医学专家,得出的结论是,肌肉注射部位是一个较大的身体区域,个体对该区域的暴露差异较小。这激发了我们寻找替代解决方案以使用视觉 AI 辅助技术检测站点的想法。
Vision-AI 辅助注射部位检测
上述注射部位检测的现有研究主要利用 3D 传感技术,这意味着需要支持 3D 人体视觉的先进 AI 模型和相应定制的相机。还涉及昂贵的硬件来促进这些模型。
在这个项目中,我们提出了 J-Eye,这是一种基于Xilinx KV260 板的低成本 2D 视觉 AI 辅助肌肉注射部位检测解决方案。最终目标是为促进自主注射提供替代解决方案。
在这里,我们的目标是在 KV260 上构建一个低成本的注入点检测应用程序,并利用 Xilinx 提供的强大工具套件。我们还旨在使用轻量级 AI 模型探索 2D 物体检测/定位技术的能力,该模型可以在 FPGA 板上实现,易于设置。
目前只有少数工作专注于 2D 视觉 AI 辅助人体手臂检测,并且没有可用的大型公共数据集。考虑到 Vitis-AI 模型动物园对 KV260 的适用性及其用户友好的训练、量化、编译过程,我们专注于全面部署 Vitis-AI 的模型及其功能。此外,基于人脸比手臂更容易区分的事实以及当今人脸检测研究的蓬勃发展,我们决定利用人脸检测的价值,仅通过二维图像处理来定位“无特征”的三角肌和注射部位。这是通过利用 Vitis-AI 模型动物园中可用的面部检测模型来实现的,然后将其结果转换为针对注射部位。
项目概况
我们的项目是按照如下所示的逻辑流程开发的。
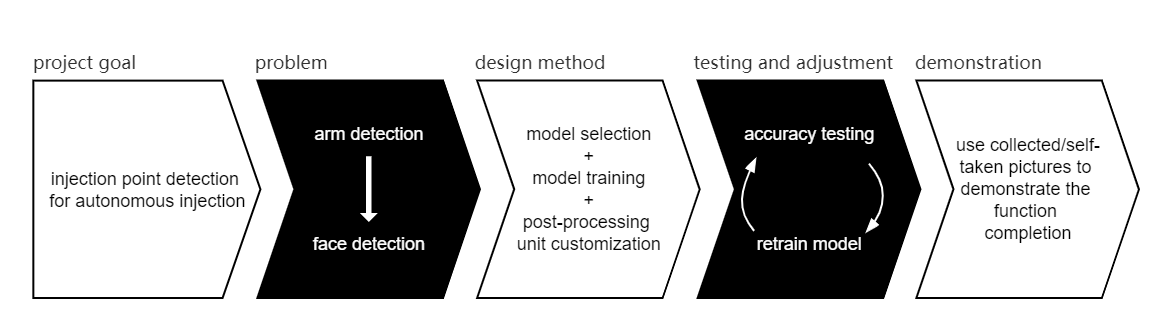
目的是让连接 KV260 的监护仪指示患者手臂上的注射部位。由于硬件资源的限制和目前现有的手臂检测工作数量较少,我们决定将问题简化为人脸检测辅助后处理来指示结果。对于我们项目的主要部分,我们研究了基于 Vitis-AI 的模型选择和训练策略。而对于后处理,主要是使用 VVAS 的 OpenCV 编码。然后在测试阶段,我们使用收集到的与我们的应用场景相匹配的图像来查看不同训练时期或训练策略下的准确性,然后相应地重新训练模型。最后,演示部分以图片输入为基础,结果呈现更加清晰稳定。
环境设置
KV260
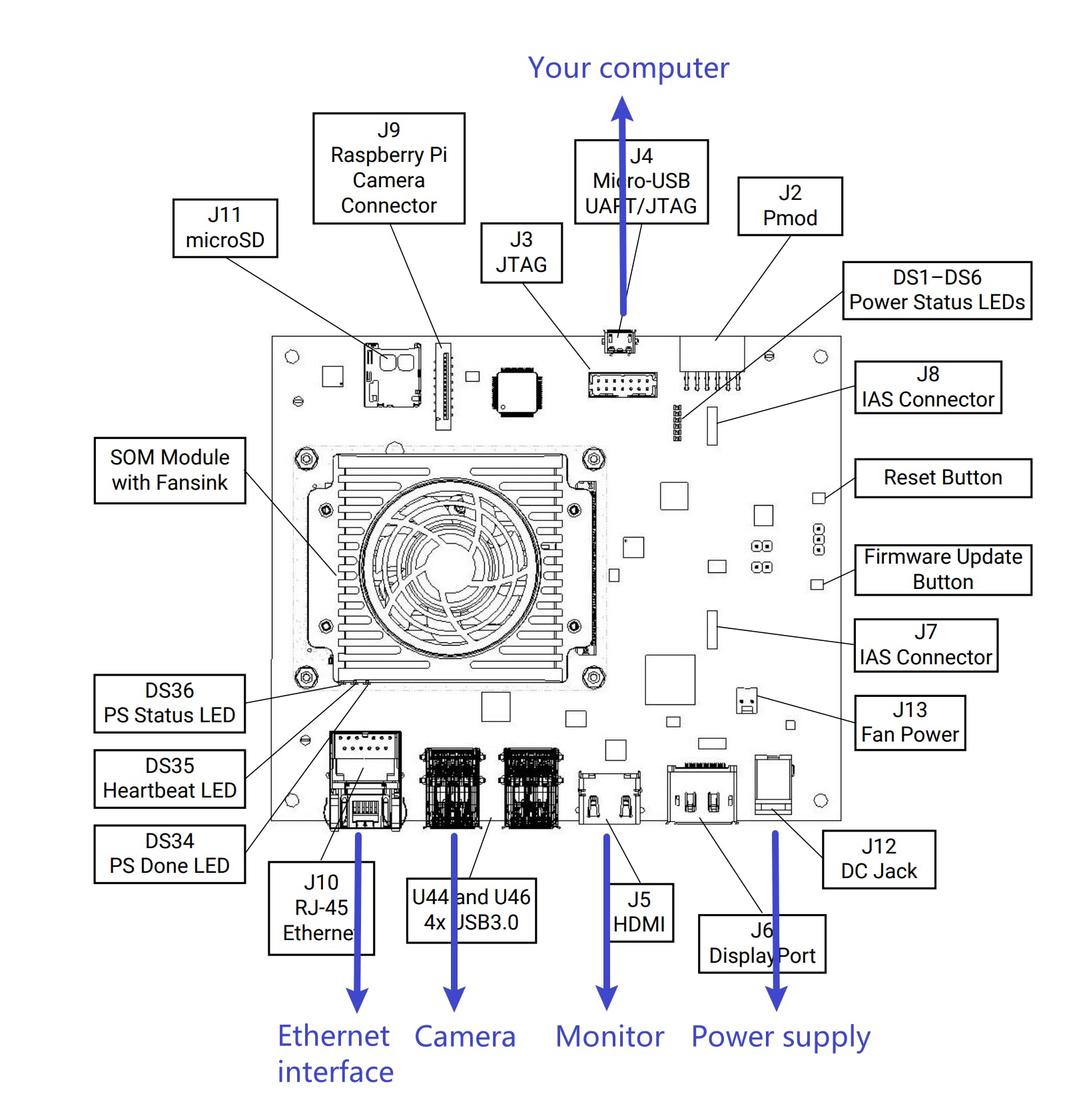
以下步骤将让您了解如何开始使用 KV260 ,以及如何在您的计算机和 KV260 之间启用便捷的文件传输。
注意:以下设置和构建过程是在Windows上实现的。
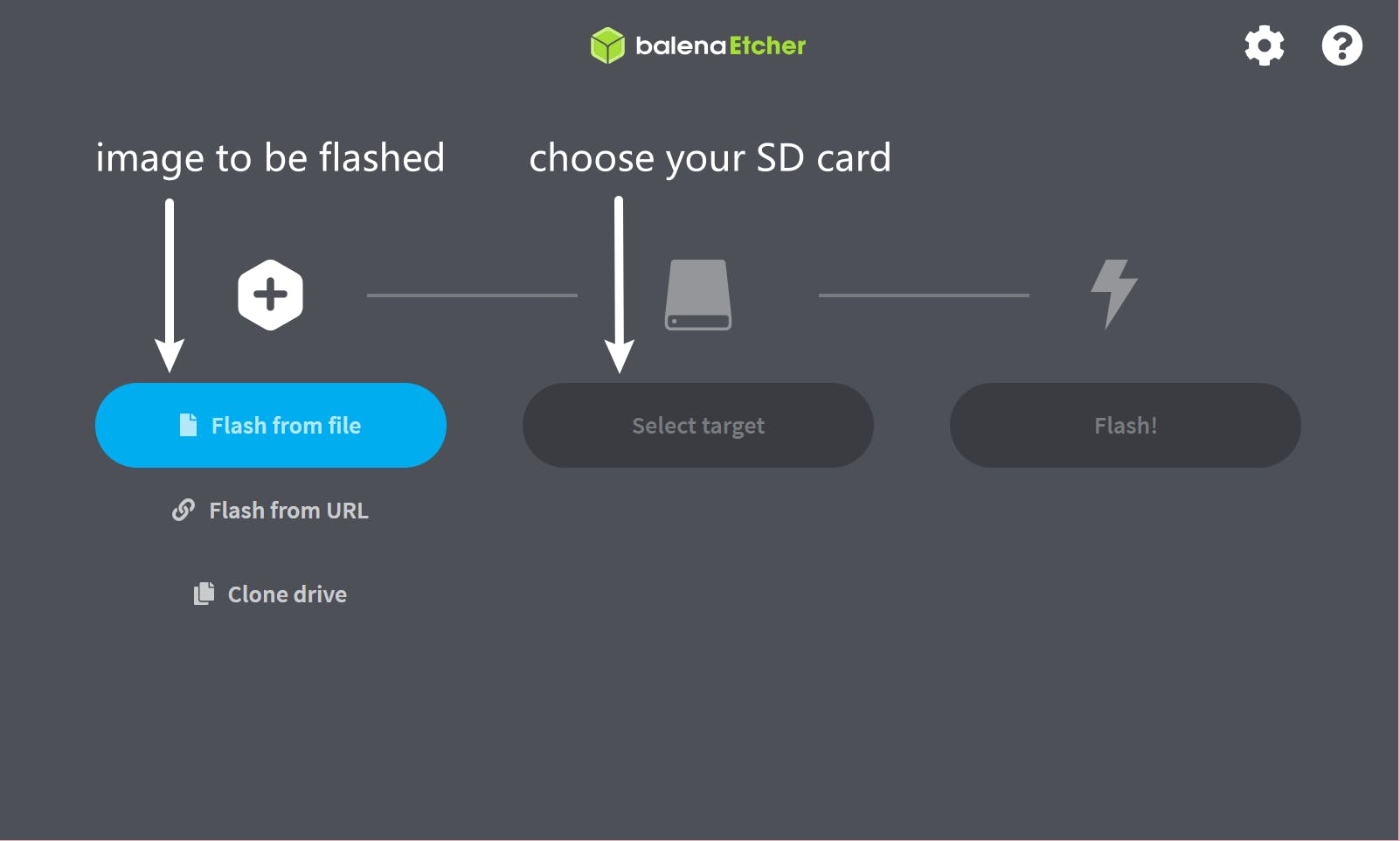
首先,获取官方发布的SD 卡镜像,并使用 balenaEtcher 将其刷入您的 SD 卡。
然后让您的 KV260 和计算机连接起来,如下所示。
打开 Mobaxterm, 创建一个新的Session并选择 “Serial”,
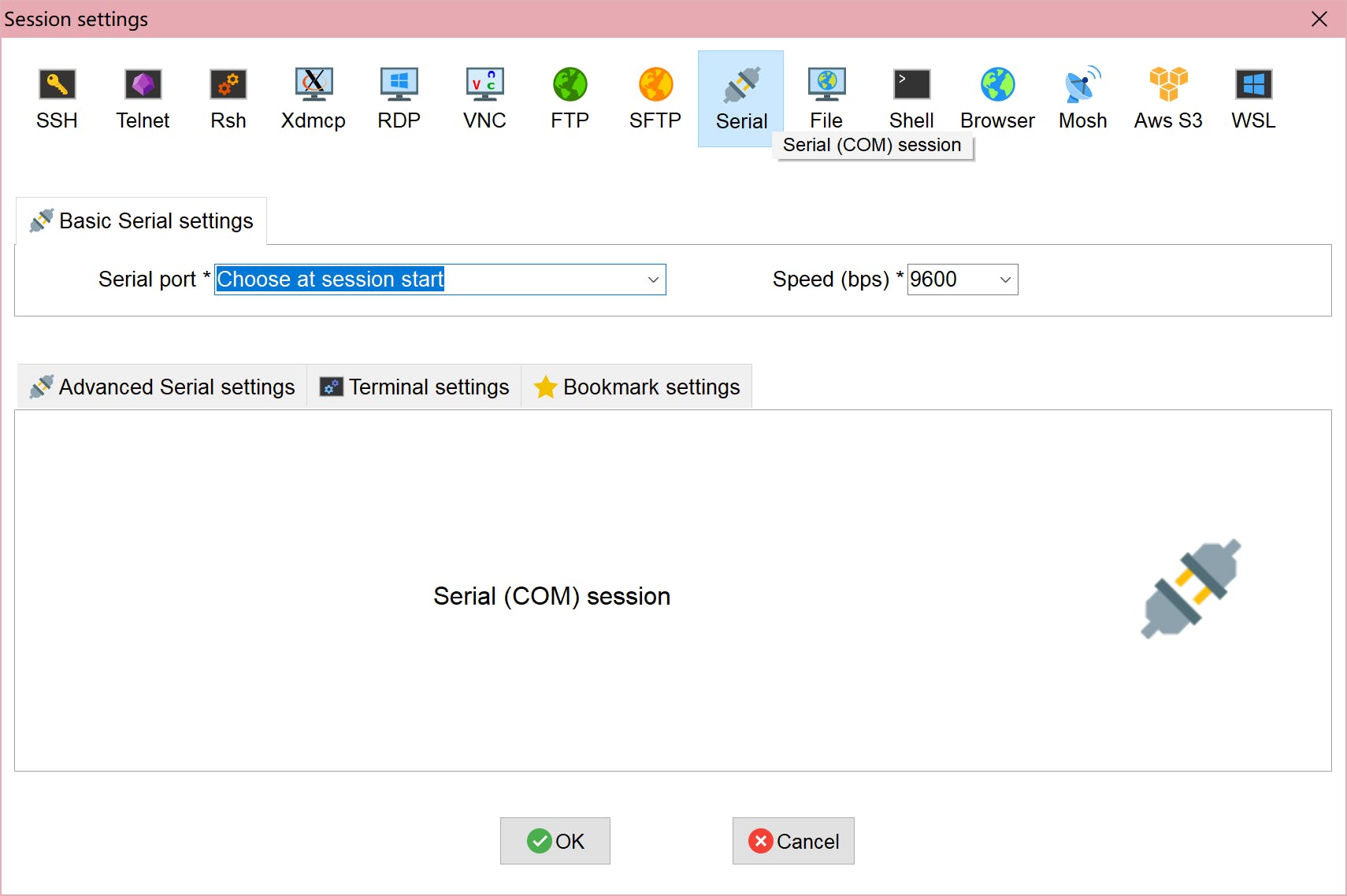
然后选择一个带有前缀“COM”的串行端口,描述为 USB 类型。通常你会看到两个具有匹配特性的串口,但索引较小的那个是正确连接的。
接下来,将Speed更改为 115200。在Advanced Serial Settings部分中,修改如下设置。
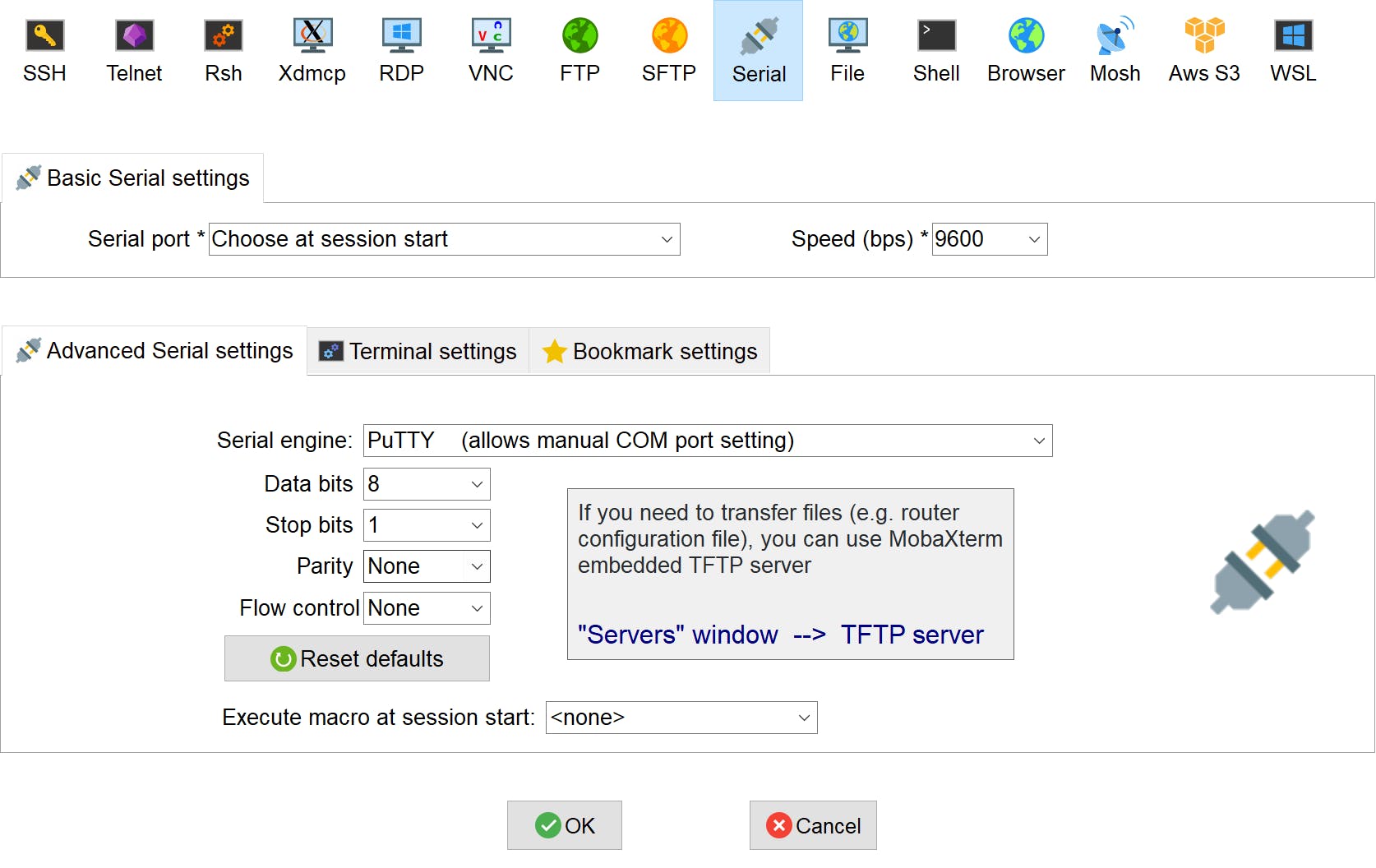
单击确定以连接到板。请注意,如果您看不到板上的任何消息并且没有报告错误消息,请按键盘上的 Enter。
为了方便我们的计算机和 KV260 之间的文件传输,首先我们应该为我们的板子启用 ssh。
在您刚刚在 Mobaxterm for KV260 中打开的终端中,输入
ifconfig
获取板子的IP地址。
然后仍然在 Mobaxterm 中,创建一个新会话。选择“SSH”并填写您刚刚拥有的IP地址并将用户名指定为“petalinux”。
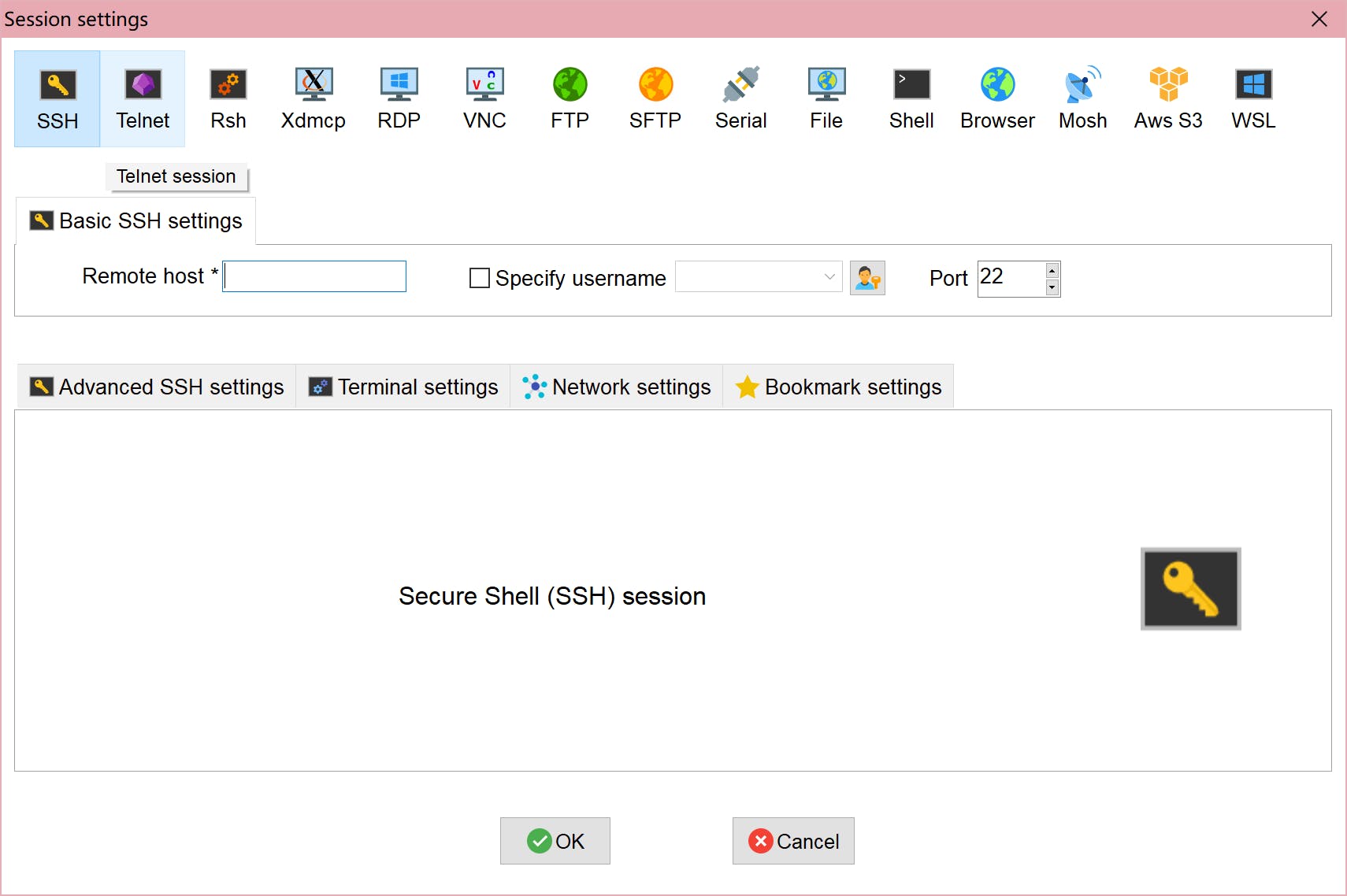
并在高级 SSH 设置部分,将 ssh-browser 类型修改为“ SCP(增强速度)”。然后单击确定,您将看到终端如下所示。
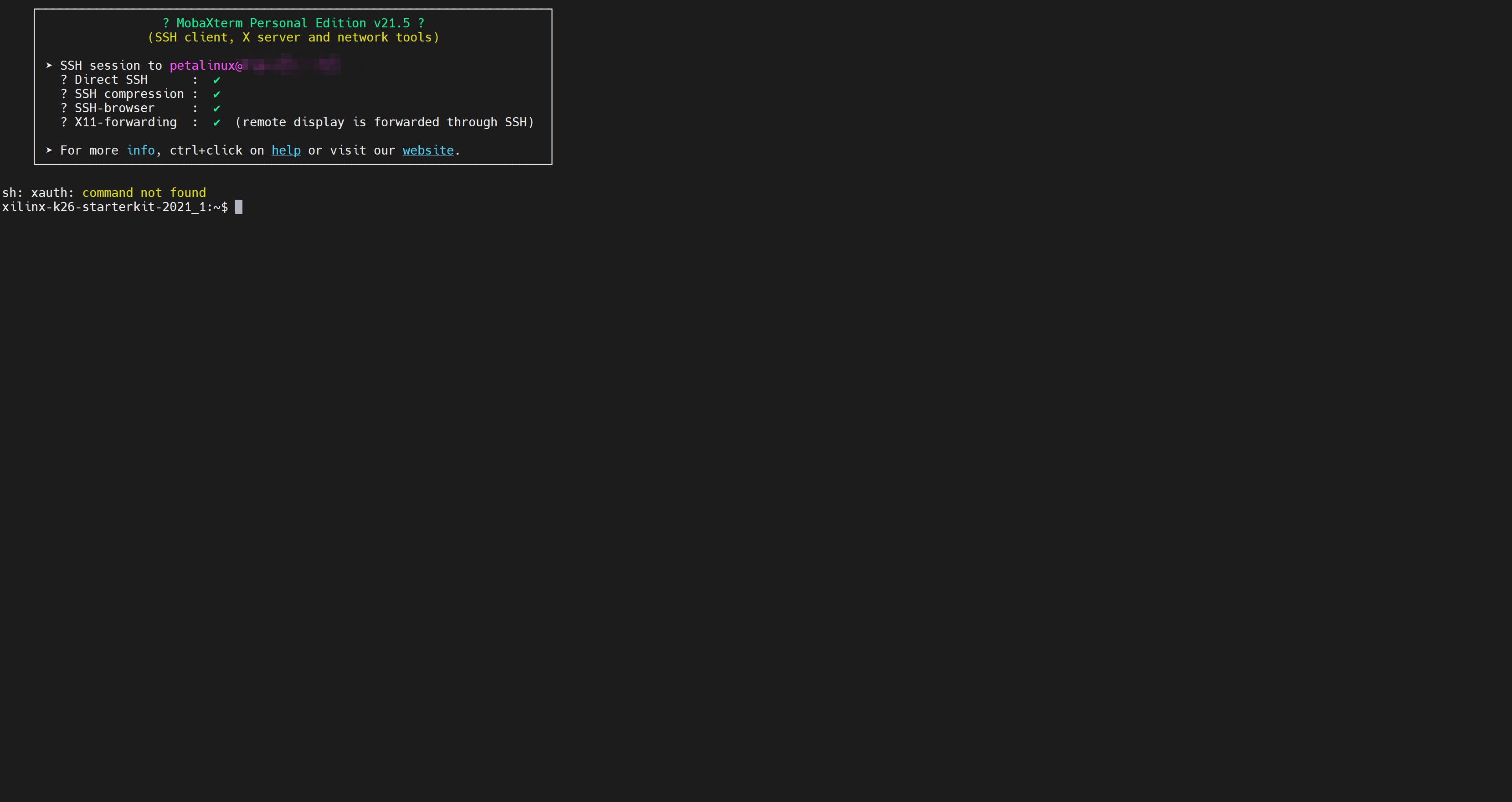
现在,对于文件传输,在 Mobaxterm 中转到您要上传/下载文件的目录。然后只需将要传输的文件拖入/从目录中传输,如下图所示。
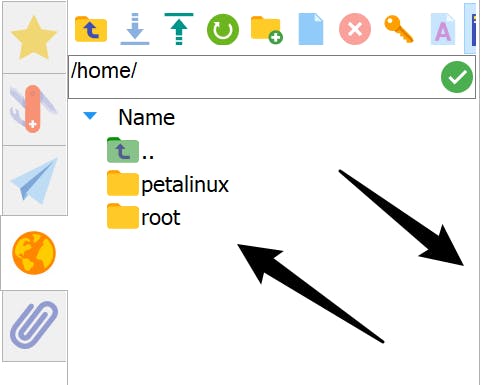
如果文件传输过程中出现权限错误提示,可以尝试修改目标目录的权限
sudo chmod 777 ${TARGET_DIRECTORY}
Vitis-AI
以下步骤将告诉您如何在您自己的计算机上设置 Vitis-AI。
注意:以下设置和构建过程在Ubuntu 20.04上实现。
先决条件:码头工人
首先,通过此命令克隆 Vitis-AI 存储库。
git clone --recurse-submodules https://github.com/Xilinx/Vitis-AI
转到克隆的目录。
cd Vitis-AI
建议通过以下命令从 docker hub 拉取 docker 镜像,因为这样更快。
docker pull xilinx/vitis-ai:latest
请注意,上面的命令只为您构建 CPU 版本的 Vitis-AI,对于 GPU 版本,您可以使用位于下的 shell 文档Vitis-AI/setup/docker/
./docker_build_gpu.sh
拉取过程完成后,您可以通过以下方式启动 Vitis-AI
./docker_run.sh xilinx/vitis-ai
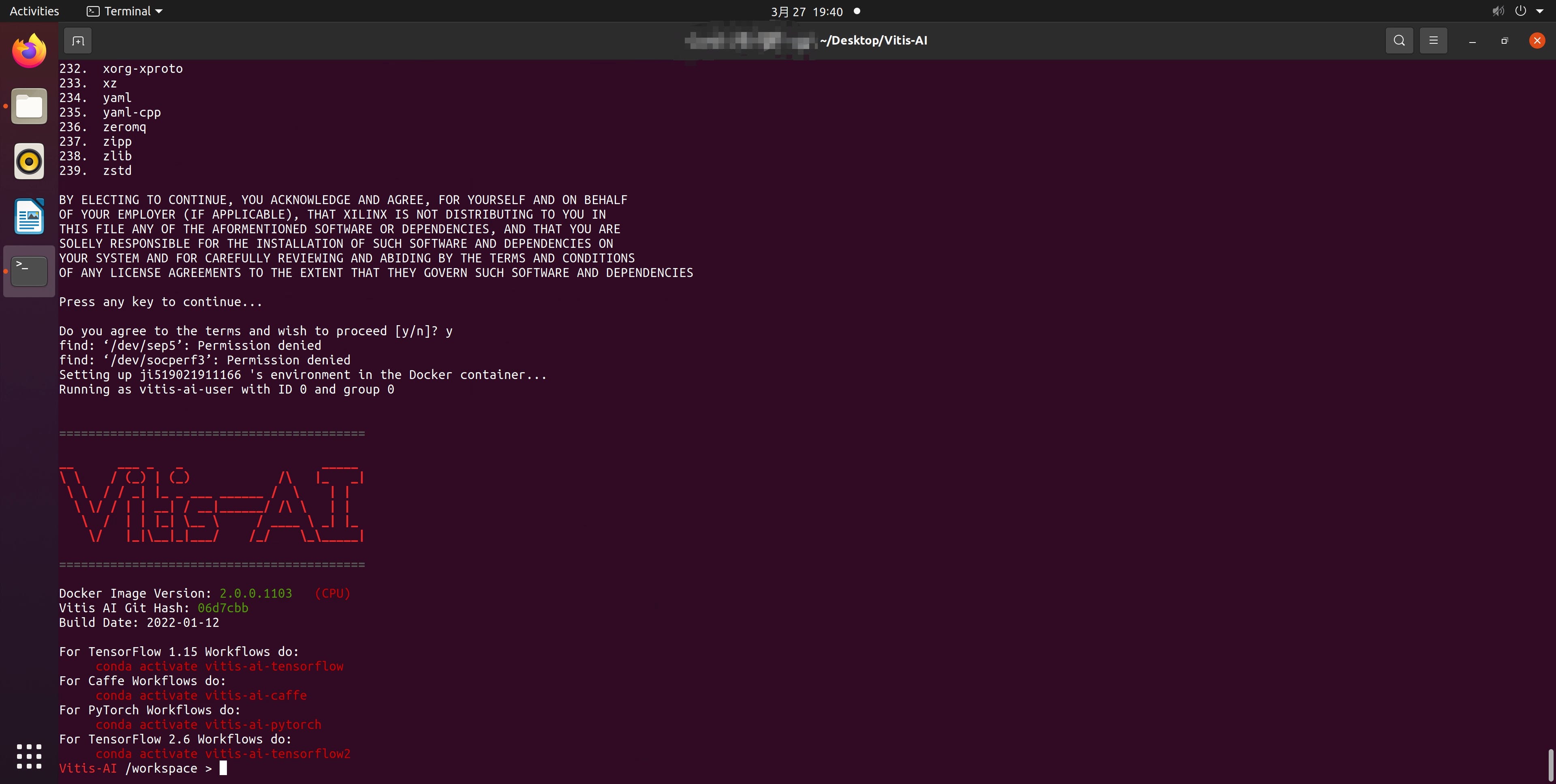
。
如果您想为您的自定义应用程序修改/编写 VVAS 相关代码,以下步骤将让您了解如何设置 VVAS 交叉编译环境。
注意:以下设置和构建过程在Ubuntu 20.04上实现。
我们将首先设置 Xilinx 提供的 VVAS 的交叉编译环境。转到克隆的 Vitis-AI 存储库的目录(如果没有,请转到上面的 Vitis-AI 设置部分)。然后导航到setup/mpsoc/VART并在命令行中键入以下内容。
./host_cross_compiler_setup.sh
运行命令完成后,它将告诉您如何启动 setup 交叉编译环境,如下所示。
source ${PATH_TO}/environment-setup-cortexa72-cortexa53-xilinx-linux
请注意,每次启动新终端时,请重新运行此命令以启动环境。
接下来,ls在当前目录下,你会看到一个 sdk shell 文件。然后运行以下命令。
./${SDK_NAME}.sh -d `pwd` -y
完成此操作后,您已经设置了 VVAS SDK,命令行会告诉您激活它,例如,
. ${PATH_TO}/environment-setup-cortexa72-cortexa53-xilinx-linux
请注意,每次启动新终端时,请重新运行此命令以启动 SDK。
现在您已准备好为您的应用程序编译 VVAS 相关代码的一切。详细的编译过程将在后处理单元构建部分给出。
在接下来的 3 部分中,我们将为您提供详细的构建流程说明,包括我们的应用模型的 Vitis-AI 模型训练,我们定制的后处理单元的 VVAS 使用,最后,如何将它们与原始 kv260-smartcam 集成构建我们的应用程序 J-Eye。它们的结构简介如下所示。
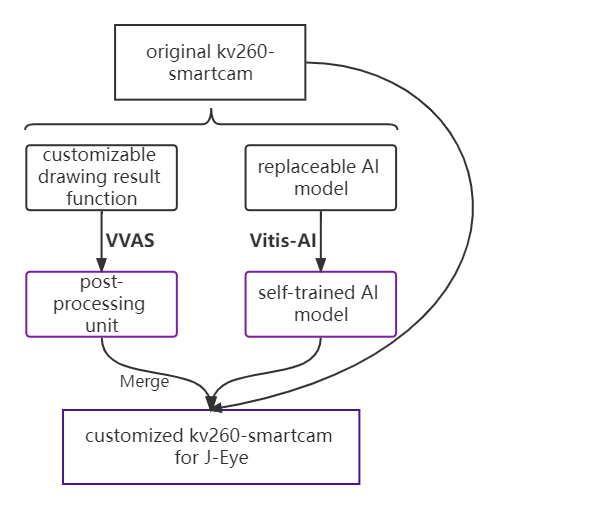
Vitis-AI 模型准备
可与 VVAS 一起使用的受支持 Vitis-AI 模型是有限的。对于我们需要的模型类 FACEDETECT,VVAS 中只有 densebox 可用,并且精度很高。考虑到我们的应用场景是疫苗接种。为了降低病毒传播的风险,人们在打针时大多戴口罩。Vitis-AI 中预训练的密集框使用数据库WIDER FACE进行一般人脸检测训练,其中不强调医学蒙面的人脸。为了确保可以很好地检测蒙面人脸,尤其是当人们在注射过程中将侧脸转向相机时,我们使用MAFA(最流行的蒙面人脸数据集之一)基于预训练的密集框增量训练。
准备 AI 模型的详细构建过程如下所示。
模型训练
我们的模型是使用 caffe 训练的,它在 Vitis-AI 中的环境可以被激活为
conda activate vitis-ai-caffe
训练过程基于Vitis-AI 提供的预训练模型。通过上面的链接进入你下载的官方模型的目录。然后导航到code/train/并运行以下命令。
vai_q_caffe finetune -solver solver.prototxt -weights quantize_train_test.caffemodel -model train.prototxt
请注意,此处所需的所有文件均由 Vitis-AI 密集盒模型提供,但我们对训练过程进行了一些重大修改。您可以通过https://github.com/iCAS-SJTU/J-eye/tree/main/models/train访问我们修改后的文件。但是当你在做这一步时,请修改训练数据集的路径train.prototxt。并且根据您的计算机配置,您可以分别更改批量大小和最大迭代train.prototxt次数solver.prototxt。至于数据集,您可以通过此链接下载它https://drive.google.com/drive/folders/1nbtM1n0--iZ3VVbNGhocxbnBGhMau_OG
完成此步骤后,您将派生一个带后缀的浮点模型。caffemodel在目录${DOWNLOADED_MODEL_FILE_PATH}/code/train/snapshot中,将在下一步中量化
模型量化
这里我们使用 Vitis-AI 提供的量化命令生成编译所需的量化模型。
vai_q_caffe quantize -model quantize.prototxt -weights armdetect_float.caffemodel -keep_fixed_neuron
你可以quantize.prototxt从下载的densebox模型和https://github.com/iCAS-SJTU/J-eye/tree/main/models/floatarmdetect_float.caffemodel中找到。您应该在准备好所有需要的文件的目录中运行此命令,或者您需要更改命令中的相对路径。
模型编译
我们使用 Vitis-AI 提供的编译命令进行编译,您将导出一个.xmodel可以放在 KV260 上的文件。
vai_c_caffe -p quantized/deploy.prototxt -c quantized/deploy.caffemodel -a arch.json -o compiled/ -n arm_detect
您可以在https://github.com/iCAS-SJTU/J-eye/tree/main/models/quantized中找到deploy.prototxt、deploy.caffemodel和。您应该在准备好所有需要的文件的目录中运行此命令,或者您需要更改命令中的相对路径。arch.json
后处理单元大楼
利用 VVAS 将帮助我们将检测结果转换到监控屏幕上。在这里,我们将向您展示如何将修改后的源代码编译为可供后处理配置文件使用的库文件。
首先,我们必须从 github 克隆 VVAS 存储库,以便为我们的后处理代码编译获取所需的实用程序和库。
git clone https://github.com/Xilinx/VVAS.git
要获得我们需要的所有实用程序和库,我们必须按以下顺序进行编译
- vvas-utils
- vvas-gst-插件
- vvas-accel-sw-libs
vvas-utils
首先我们应该meson.cross根据提供的VVAS/vvas-utils/meson.cross.template. 只有两件事你需要做修改,${SYSROOT}和${NATIVESYSROOT},其中${SYSROOT}指代${PATH_TO}/petalinux_sdk_2021.1/sysroots/cortexa72-cortexa53-xilinx-linux和${NATIVESYSROOT}指代${PATH_TO}/petalinux_sdk_2021.1/sysroots/x86_64-petalinux-linux。
如果您是第一次为 VVAS 进行交叉编译,请执行以下命令。
cp meson.cross ${NATIVESYSROOT}/usr/share/meson/aarch64-xilinx-linux-meson.cross
然后我们准备编译:)
使用设置交叉编译环境和 SDK 时提供的命令获取编译环境。
. ${PATH_TO}/environment-setup-cortexa72-cortexa53-xilinx-linux
source ${PATH_TO}/petalinux_sdk_2021.1/environment-setup-cortexa72-cortexa53-xilinx-linux
假设你在目录下VVAS/vvas-utils/,
mkdir build
meson build
cd build
ninja
这部分编译成功后(假设你还在目录中build),我们必须键入以下命令,以使我们后面的编译步骤更容易。
cp pkgconfig/ivas-utils.pc ${SYSROOT}/usr/lib/pkgconfig
cp utils/libivasutil.so utils/libxrtutil.so ${SYSROOT}/usr/lib
另外,将目录下的所有头文件复制vvas-utils/到 ${SYSROOT}/usr/include
vvas-gst-插件
假设你在目录下VVAS/vvas-gst-plugins/,
mkdir build
meson build
cd build
ninja
这部分编译成功后(假设你还在目录中build),做下面的复制工作,让我们后面的编译步骤更简单。
cp pkgconfig/ivas-utils.pc ${SYSROOT}/usr/lib/pkgconfig
cp ${SO_FILE_NAME}.so ${SYSROOT}/usr/lib
另外,将目录下的所有头文件复制vvas-gst-utils/到 ${SYSROOT}/usr/include
vvas-accel-sw-libs
假设你在目录下VVAS/vvas-accel-sw-libs/,去vvas_xboundingbox/src替换为vvas_xboundingbox.cpp我们的后处理代码(我们的源代码ivas_airender.cpp由Xilinx提供修改)。然后
cd ../..
mkdir build
meson build
cd build
ninja
现在,vvas_xboundingbox/您将在下面找到vvas_xboungdingbox.so将用作在 KV260 上进行后期处理的重要文件。
在 KV260 上组装
在 KV260 上,下载应用程序 smartcam 的软件包。
sudo dnf install packagegroup-kv260-smartcam.noarch
在KV260 上的目录下,/opt/xilinx/share/ivas/smartcam/
mkdir armdetect
cd armdetect
然后将https://github.com/iCAS-SJTU/J-eye/tree/main/models/config中的所有配置文件复制到这个目录下(配置文件是官方发布的修改)。
接下来,进入目录/opt/xilinx/share/vitis_ai_library/models/kv260-smartcam/,
mkdir armdetect
cd armdetect
然后将https://github.com/iCAS-SJTU/J-eye/tree/main/models/编译好的所有模型相关文件复制到这个目录下。
对于后处理部分,从https://github.com/iCAS-SJTU/J-eye/tree/main/post-processing复制库文件并将其放在/opt/xilinx/lib.
完成所有这些后,您就可以开始我们的应用程序了
sudo xmutil unloadapp
sudo xmutil loadapp kv260-smartcam
sudo smartcam -u ${USB_PORT_NUMBER} -W 1920 -H 1080 --target dp -a armdetect
请注意,${USB_PORT_NUMBER}可以通过以下方式找到可用的ls /dev | grep media
结果
为了验证我们训练的模型和后处理单元的检测能力,我们从Google.com中选择了一组图片显示刚接种疫苗的人。我们的测试集涵盖了不同的性别、种族和年龄。验证输出标记在图片上。请注意,这里我们仅将部分结果作为示例显示。红色矩形表示面部,白色实心圆圈表示注射部位。根据结果,它表明在口罩可用或不可用的情况下,以及在提供侧视图或前视图的情况下,人脸都能被正确识别。我们的解决方案能够正确定位该点,这通过将白点与图片上的原始绷带重叠来反映。已经测试了 100 多张图片,并且显示了类似的结果。这大大增强了我们的信心。
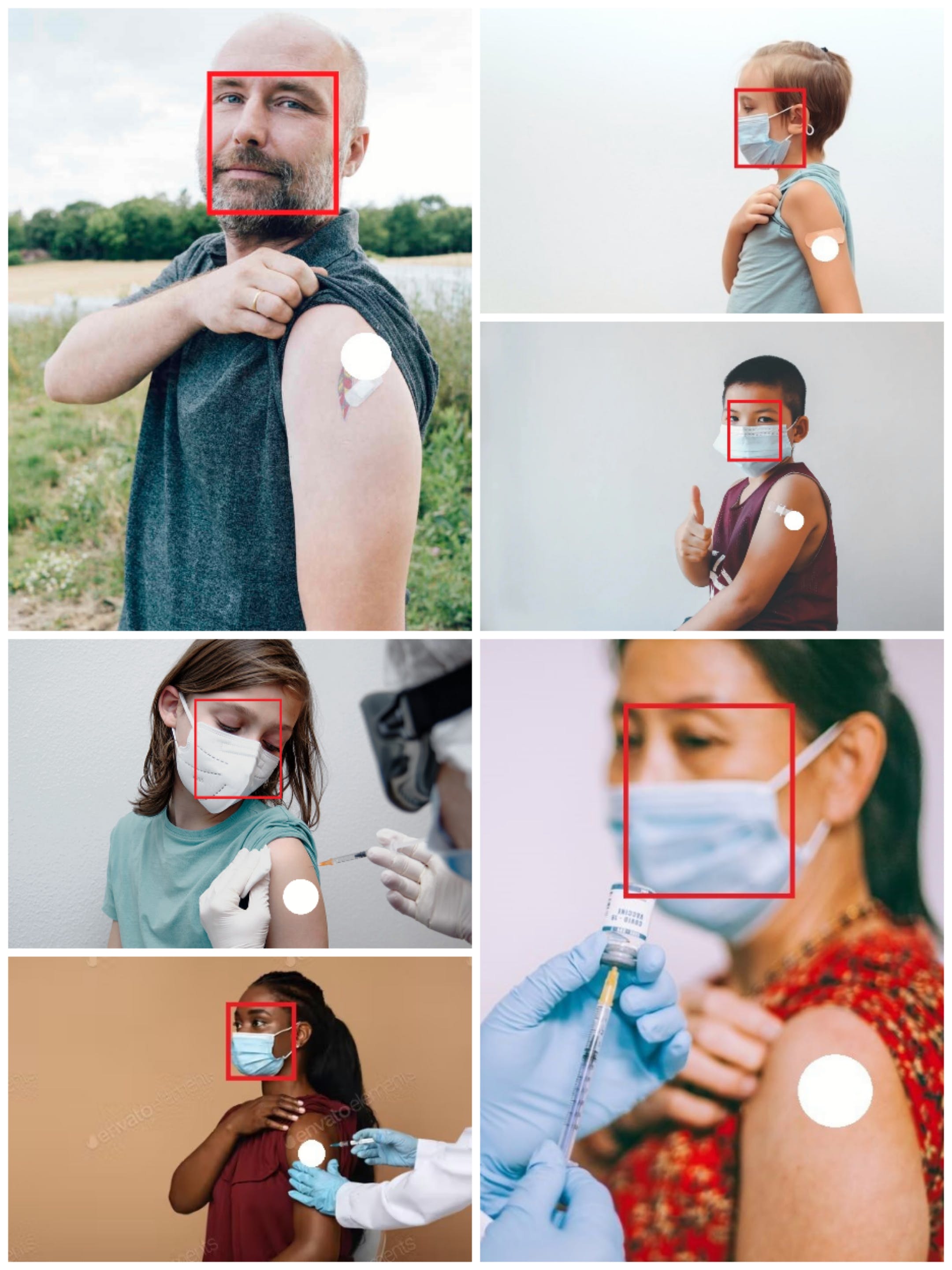
。
下面是我们在 KV260 上启动 J-Eye 后如何进行演示。KV260 连接 USB 摄像头和监视器,如下图所示。监视器也是机器人系统的一部分。屏幕将显示检测结果。接受注射的人员应按地面标明的位置站立。
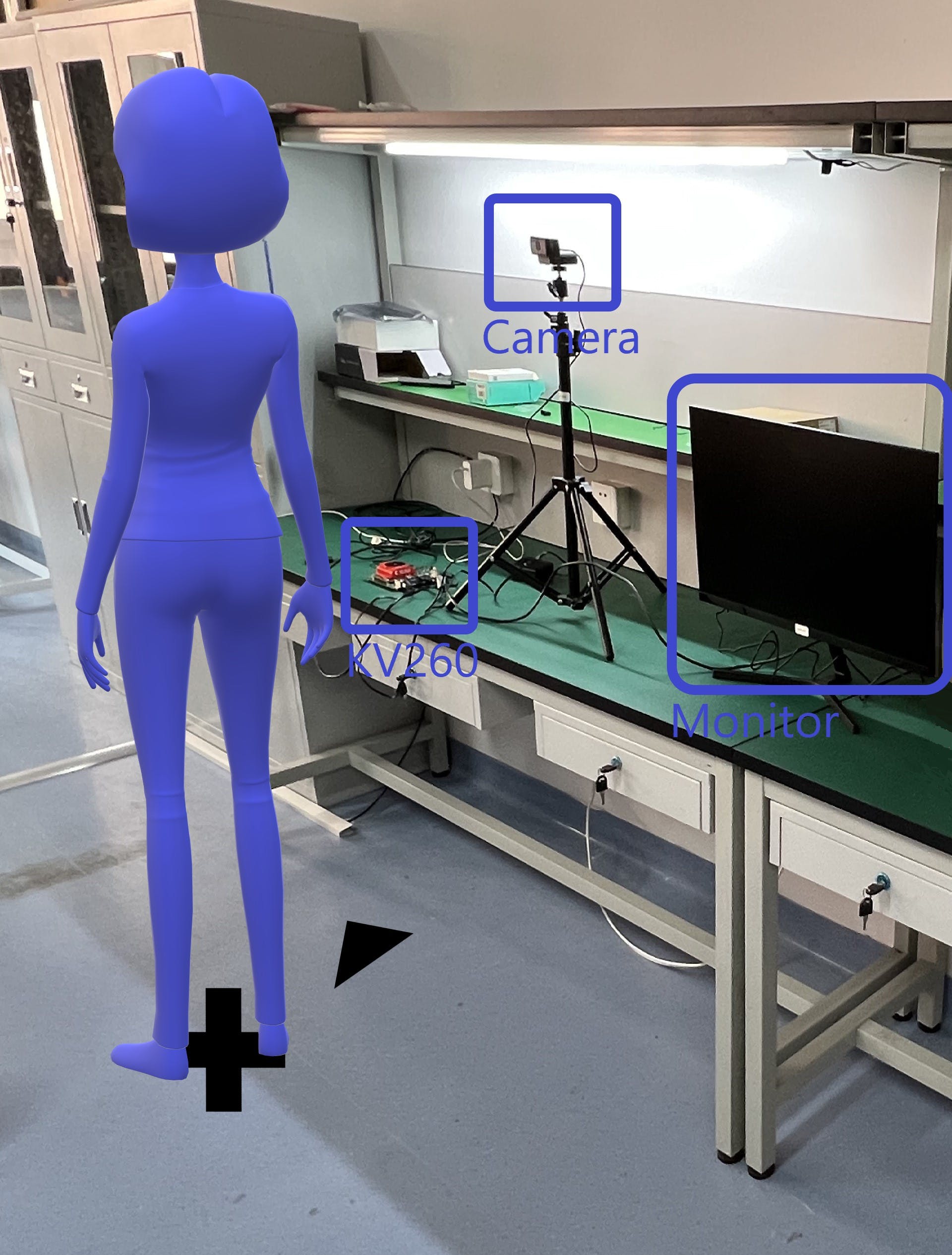
确保您在相机前笔直站立,并且您的左侧脸大约在屏幕中心。
如果您不在机器人可达范围内怎么办?
如果接受注射的人站在可检测范围的角落,我们的应用程序支持在屏幕上显示提醒消息。

检测结果如何显示在屏幕上?
如果您站在可检测范围内,应用程序将在屏幕上定位您的面部和注射部位,如下图所示。

概括
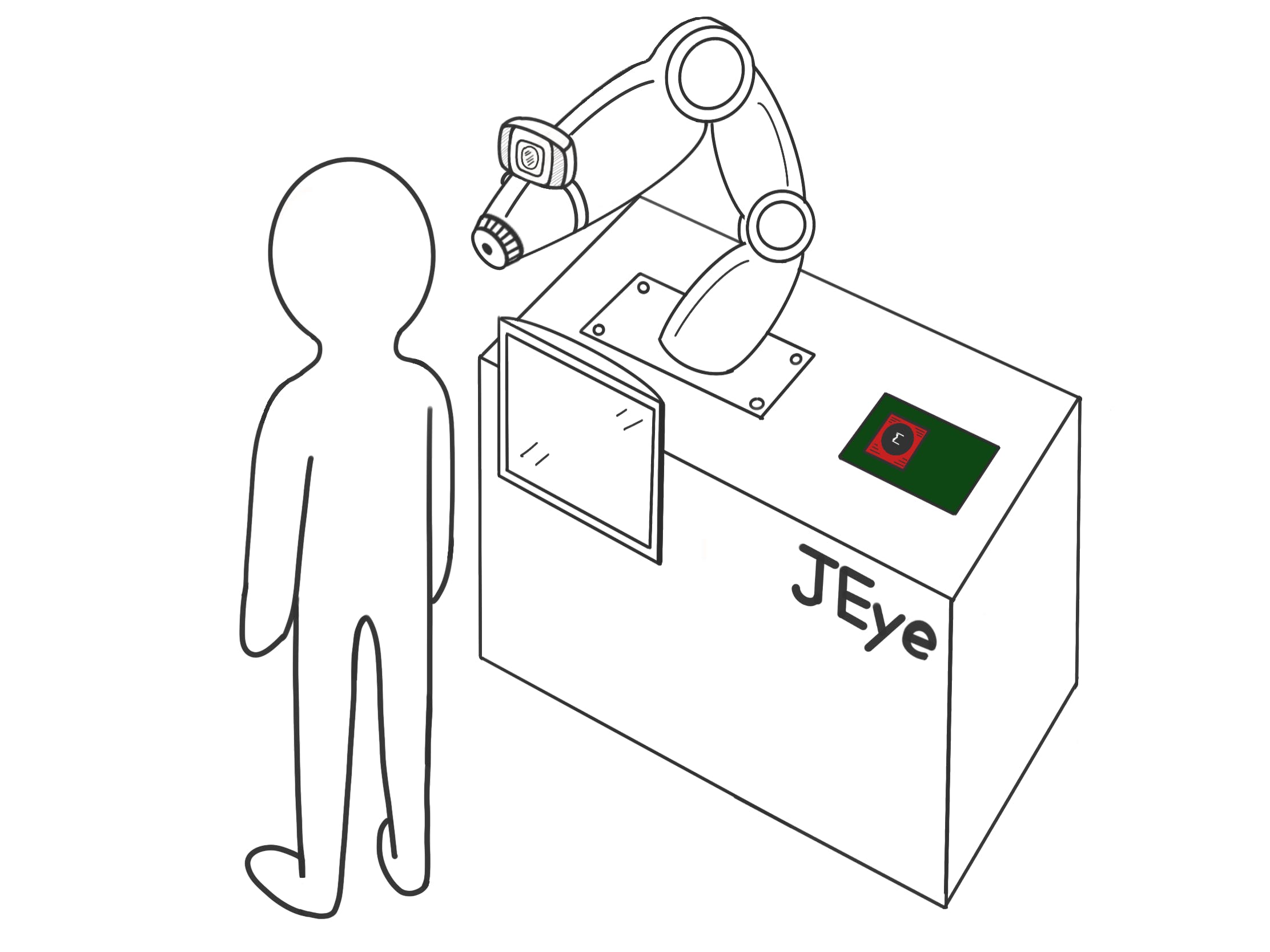
上述结果和演示表明,当患者处于可检测范围内并处于如上图所示的准备注射姿势时,我们提出的解决方案效果很好。与 3D 解决方案相比,它在更复杂的条件下的检测性能肯定会受到限制,但这确实是我们的第一次尝试。我们正在进行的努力包括整合更复杂的模型,并与机械工程系的研究人员合作对整个系统进行原型设计。概念图如下所示。
这里我们简要讨论整个系统的工作流程。嵌入在机械臂上的摄像头将与 KV260 板连接。检测结果将显示在监视器屏幕上。机械臂将接收到来自电路板的准确检测信息(例如坐标)并做出相应的移动。在患者超出摄像头范围的情况下,警告信息将显示在监视器上,直到恢复正常状态。一旦人静止不动并且面部在相机视图中,检测将开始。
最后,我们在下面总结了我们对这个项目的主要贡献。
- 低成本、高适应性的2D注射部位检测:我们的项目开发周期较短,成本肯定低于基于3D传感的注射部位检测项目。同时,J-eye 有很大的潜力用于其他模型。至于功能,根据我们展示的结果和演示,我们证明了最初的尝试是有效的。我们正在努力通过查看更复杂的模型以及从多个摄像头对人体图片进行采样的潜在用途来提高检测精度。
- 使用 Vitis-AI 模型支持无特征的身体区域检测:在我们的应用场景中,手臂检测是必不可少的,但人的手臂特征太少,无法在 2D 图像中足够区分。许多其他人体部位也是如此,它们虽然是纯皮肤,但对于医疗仍然很重要。我们观察到,人脸检测是当今成熟的视觉 AI 模型之一,其准确性已被证明因其在市场上的广泛使用而令人满意。我们的项目通过适当的后处理动作转移了其在检测其他无特征的人体部位方面的价值。
- 增强赛灵思流程:我们的项目充分受益于赛灵思的硬件和软件支持。但是在 VVAS 设置和编译部分,一些描述已经过时或对初学者来说很难。在开发过程中,我们还记录了整个构建过程的详细说明。它是完全开源的,可供社区使用。
致谢
我们要感谢 Xilinx 团队的慷慨帮助和耐心回答整个项目期间的所有问题,尤其是在公司并购期间。我们感谢当地卫生专家和医务人员提供专业建议。
参考
[3] https://www.globaltimes.cn/page/202201/1246148.shtml
[4] https://inf.news/en/tech/1fe00617cfdae9eda4464a2b42006525.html
[5] https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7886662/
[6] https://www.eet-china.com/mp/a86386.html
[7] https://www.xilinx.com/support/documentation/sw_manuals/vitis_ai/1_3/ug1414 -vitis-ai.pdf
[8] https://xilinx.github.io/kria-apps-docs/main/build/html/docs/smartcamera/docs/app_deployment.html
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章






