
资料下载


基于M-DSP的浮点乘累加器设计
分享资料个
数字信号处理器(Digital Signal Processor.DSP)从专用信号处理器开始发展到今天的超长指令字( Very Long Instruction Word.VLIW)阵列处理器,其应用领域已经从最初的语音、声纳等低频信号的处理发展到今天雷达、图像等视频大数据量的信号处理。由于浮点运算和并行处理技术的应用,信号处理能力已得到极大的提高。随着数字信号处理器在处理速度和运算精度两个方向的发展,体系结构中数据流结构甚至人工神经网络结构等,将可能成为下一代数字信号处理器的基本结构模式。近些年,从传统DSP结构中已不能有效地提高DSP处理器的性能,许多新的提高DSP性能的方法被提出。其中提高频率的方法已达到瓶颈阶段,最有效的途径是提高并行性。数字信号处理领域的核心算法根据运算类型可以分为两大类:一类是以密集的浮点乘加运算为典型的信号处理算法,包括快速傅里叶变换( Fast Fourier Transformation,FFT)、有限冲激响应( Finite Impulse Response,FIR)和离散傅里叶变换(Discrete Fourier Transform, DFT)等算法;另一类足以密集的复数矩阵操作为主的算法,包括信道估计和多输入多输出( Multiple-Input Multiple-Output,MIMO)均衡等算法。这两类算法均需要DSP处理器提供较高的浮点乘加运算的计算性能。第一类算法主要是进行乘加运算(a*b+c),第二类算法主要进行大量的复数矩阵乘和矩阵求逆等运算,而在这些运算中都存在密集的乘后加运算(a*c+c*d)浮点乘累加器(Floating-point Multiply ACcumulate.FMAC)已经成为提高并行计算以减少计算延时的有效方法,其运算能力已经成为衡量数字信号处理器DSP性能的一个重要特征。
浮点乘加结构已被研究多年,IBM学者Montoye和Hokenek于1990年最先提出了融合乘加的概念,即将乘法和加法融合成一条指令执行,并将加法操作融合在乘法的部分积压缩阵列中,从而减少硬件开销和延时;这种乘加结构的主要缺点是求和尾数长且结果尾数舍入延时长。Lang等于2004年提出了低延时融合乘加结构,这种结构采用前导零预测( Leading Zero Anticipation,LZA),将尾数舍入和加法合并,并在尾数加法之前进行规格化移位。目前大多数处理器中的浮点乘加设计实现均采用这种技术,为进一步提高浮点融合乘加结构的并行度以提升浮点乘加器的性能,Lang等于2005年设计了双通路浮点融合乘加结构,该乘加结构主要优点是延时更低、处理性能得到进一步提高;但该乘加结构逻辑设计复杂,硬件资源消耗大。国防科技大学研制的vr-XDSP中设计了多功能快速浮点融合乘加运算单元,但该设计硬件资源消耗太多,功耗过大。
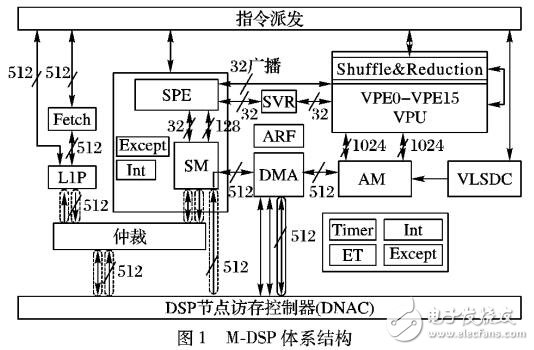
本文基于高性能计算的应用需求,以M型数字信号处理器( M-DSP)为研究背景,深入研究FMAC的各功能模块和流水线结构,对已有浮点融合乘加结构p1的关键模块和算法进行了研究与优化,设计了6级流水线结构的FMAC单元,可支持双精度和单精度浮点乘法、乘累加、乘累减、单精度点积和复数运算。对所设计的FMAC单元的寄存器传送语言(Register Transfer Language,RTL)代码实现迸行了仿真测试,并基于45 nm工艺采用Synopsys公司的DC( Design Compiler)对硬件实现进行了综合,运行频率可达1 GHz。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章



