
资料下载


×
基于视频深度学习的时空双流人物动作识别模型
消耗积分:1 |
格式:rar |
大小:1.00 MB |
2018-04-17
分享资料个
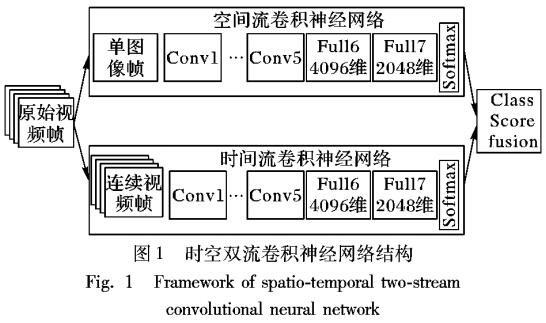
深度学习被运用于图片分类、人物脸部识别和人物位置预测等识别领域。视频人物动作识别可看作随时间变化图片的分类问题,所以图片识别的深度学习方法也被大量使用在视频人物动作识别研究中。与计算机视觉的其他领域相比,深度卷积神经网络( Convolutional Neural Network.CNN)在动作识别领域的表现并不突出,原因有以下两点:第一,现今视频数据集较小并且噪声信息较多。视频中目标的移动以及视角的变化增加了动作识别的难度,所以需要比图片识别更多的训练样本。图片数据集ImageNet每一类具有1 000个例子,而视频数据集比如佛罗里达大学YouTube行为数据集(University of Central Florida YouTube action dataset 101.UCF101)每一类仅仅有100个例子,比图片数据集少很多。第二,传统卷积神经网络结构不能充分地提取时间特征。视频是一种按时变化数据,任意像素与其邻域像素之间的相似性很大,具有很强的时间相关性与空间相关性,具有时空特征。然而卷积神经网络通常用于单一、静止的图片,不能有效地提取出连续帧之间的关联特征。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章



