
资料下载


×
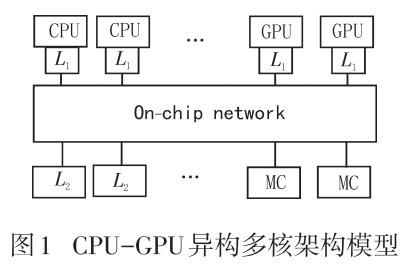
CPU-GPU异构系统下的片上网络仲裁机制研究
消耗积分:1 |
格式:rar |
大小:4.07 MB |
2018-04-26
分享资料个
在CPU-GPU异构系统架构中,由于GPU程序的多线程特点,大多数GPU程序会垄断系统中的共享资源,例如片上网络。这将给CPU程序的性能造成很大的损失。我们发现有一些GPU程序性能对网络延迟表现为不敏感。当CPU、GPU程序同时竞争片上网络时,降低这类对网络延迟不敏感的GPU程序的优先级,提高CPU程序的优先级,结果会对GPU程序的性能会造成很小的损失,同时可以大幅提高CPU程序的性能。因此,我们可以通过适时提高CPU程序的网络使用优先级来优化CPU程序的性能。当前通用的循环调度片上网络仲裁机制并没有考虑CPU、GPU程序不同的特性,系统性能存在提升的空间。基于此,我们提出一种新的基于网络延迟敏感度的仲裁机制。实验结果显示,相对于循环调度片上网络仲裁机制系统而言,基于延迟敏感度仲裁机制系统,CPU程序性能有16.6%的提高,而GPU程序性能发生3.65%的下降。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章



