
资料下载


如何使用Spark进行并行化出租车轨迹热点区域的提取与分析资料概述
分享资料个
从出租车GPS轨迹数据中可挖掘出丰富的居民出行规律信息,但数据量的不断增加,对数据挖掘的准确性和效率提出了新的要求。本文以成都市出租车GPS轨迹数据为研究对象,首先对原始数据进行失真数据剔除、多余字段删除和部分时段数据过滤三方面的预处理,其次进行地图匹配,最后利用Spark大数据处理平台,实现K-Means||算法,分为工作日和休息日的不同时段进行挖掘分析,得到成都市居民出行热点区域及其时空分布特征,并将单机K-Means算法和K-Means||算法的性能进行对比分析,结果表明:相比于单机,K-Means||算法在准确性和时间效率上具有优越性。
随着城市中出租车数量的不断增多,GPS 卫星定位技术的不断发展与普及,装有车载GPS 的出租车在行驶过程中产生了大量的出租车轨迹数据,记录了车辆的位置、时间、方位和速度等信息,通过挖掘出租车GPS 轨迹数据可用于分析车辆移动轨迹特征、预测交通流、改善交通服务,对城市交通管理、道路规划具有重要意义。
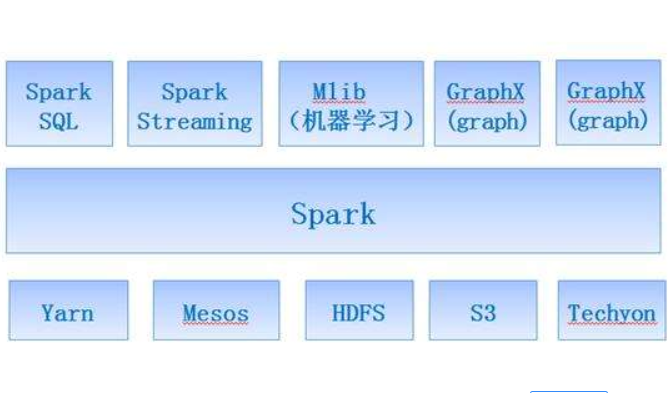
城市热点区域通常是人流量大、商业发达、经济水平发展高的中心地区,利用出租车轨迹数据提取城市热点区域的方法主要有根据数据场势值阈值法探测轨迹点的聚集模式进行提取,基于高斯定律的轨迹挖掘方法,将轨迹转换为网格序列进行聚类。但由于出租车GPS 轨迹数据数量庞大且分布状态多样,因此对轨迹数据挖掘的方法提出了新的要求,需要研究高效的分布式并行轨迹数据挖掘算法。借鉴传统研究方法之后,结合现在流行的Spark 大数据处理平台,优化K-Means 聚类算法,将成都市出租车GPS 轨迹数据进行研究,挖掘分析工作日休息日不同时段的数据,得到居民出行热点区域及其分布特点,并将单机K-Means 算法和K-Means||算法的时间效率进行对比,结果表明后者在处理大数据量的时间效率上有较好的效果。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章





