
资料下载


如何使用粗糙集进行数据流多标记分布特征的选择
分享资料个
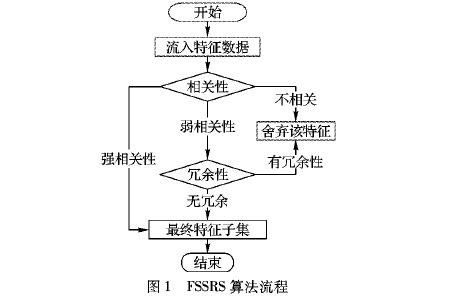
针对传统特征选择算法无法处理流特征数据、冗余性计算复杂、对实例描述不够准确的问题,提出了基于粗糙集的数据流多标记分布特征选择算法。首先,将在线流特征选择框架引入多标记学习中;其次,用粗糙集中的依赖度替代原有的条件概率,仅仅利用数据自身的信息计算,使得数据流特征选择算法更加高效快捷;最后,由于在现实世界中,每个标记对实例的描述程度并不相同,为更加准确地描述实例,将传统的逻辑标记用标记分布的形式进行刻画。在多组数据集上的实验表明,所提算法能保留与标记空间有着较高相关性的特征,使得分类精度相较于未进行特征选择的有一定程度的提高。
多标记学习作为机器学习研究热点,对现实世界中多义性对象的研究具有重要意义。1 0,并且多标记学习对象在日常生活中广泛存在。在多标记学习框架之下,数据往往面临多标记性和高维性等多种问题,使得手工标记一般费时费力。同时随着数据维数的不断增加,分类器的分类精度也在不断下降,因此探究高效的分类算法就显得尤为重要。近年来,相关学者在此问题上的研究已经取得了卓越的成绩,提出了多种算法‘“副。在现有的多标记分类算法中,与实例相关的标记重要程度被视作相同,然而在现实世界中,不同昀标记对于同一个实例的描程度并不都是相同的。例如在一幅自然风景图中,如果出现大量的“蓝天”,那么出现大量“白云”的概率也就高,其他标记的可能性也就比较低,这种现象被称为标记的不平衡性。针对这种标记的不平衡性,Geng等‘61提出了一种标记分布学习(Label Distribution Learning,LDL)范式,将传统的逻辑标记用概率分布的形式来进行描述,更加准确地反映了实例的相关内容。目前也有很多学者在标记分布学习范式下对人年龄‘“引、人脸面部识别‘刚、文本情感分类‘101等领域进行研究。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章




