
资料下载


使用TensorFlow和Artemis构建解决农村面临的问题设备
分享资料个
描述
概述:
该项目演示了如何使用TensorFlow 和 Artemis 模块构建设备,以解决任何地方农村或农业社区面临的大部分问题。该设备使用机器学习算法来检查整体植物健康、极端气候预测和保护、自动温室适应,并使用音频分析检测致命的疾病传播媒介或非法砍伐森林。该项目还展示了我们如何仅通过收集和利用从传感器获得的数据就可以对我们的农场有更多的了解。我从澳大利亚野火、印度 GDP 由于错误的农业实践而下降等新闻中获得了制作这个项目的灵感蝗虫群正在迅速破坏东非、巴基斯坦和许多其他国家的庄稼,蚊子以惊人的速度繁殖,被忽视的热带疾病,所以我在我心中找到了作为这个创新、忠诚社区的积极成员的呼声。
在制作这个项目时采取的重要措施是有效和耐心地收集数据,一旦收集到数据,工作就会变得更加容易(如果你不收集正确的数据来满足你饥饿的 ML 框架,你肯定会失败)。对于数据收集部分,我使用了我过去的项目,该项目仅从传感器收集数据并使用 Sigfox 协议发送到后端,但在这里我将根据这些数据训练我的设备。
该项目的核心是您需要在每个阶段之后调整您的设备。所以让我们开始吧,享受机器学习的学习。
技术概述:
虽然我们已经搬到了一个现代化的城市,但我仍然爱我的村庄。村庄的清新仍然让我从忧郁的心情中恢复过来,但由于周围的污染,我们的健康状况不佳,无论我们种植什么作物,它们也会对我们的身体产生一些不良影响,因此照顾这些作物以及植物和人类疾病的早期迹象,无需使用复杂、耗电的设备,这些设备需要大量维护,而且远远超出贫困农民或村民的能力范围。因此,我决定使用能够使用 ML 功能且延迟低且几乎没有碳足迹的 Edge 设备。
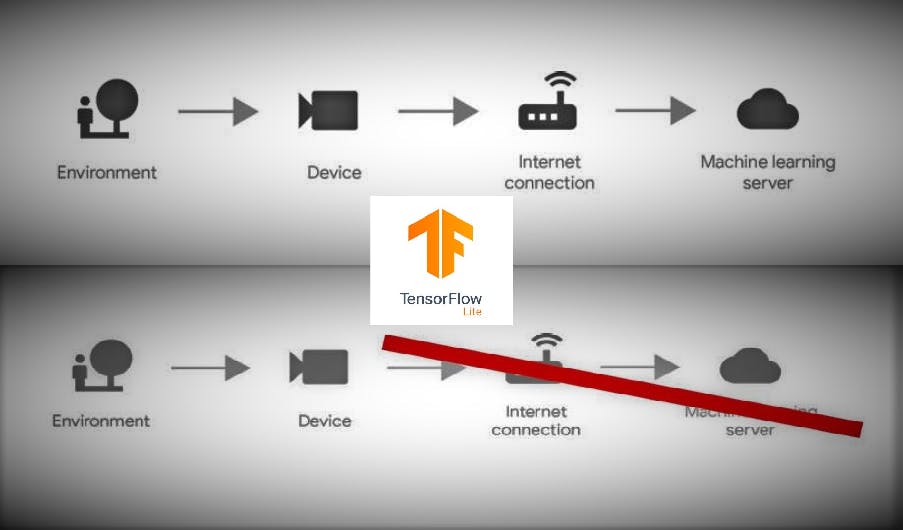
背景:
主题:自然
1)农场分析:
随着人口的增加,可持续的耕作方法变得很重要。以前我们只是用来玩传感器,但现在使用 TensorFlow,我们不仅可以感知,还可以分析、预测和采取行动。使用所有收集到的数据,我们 将这一步将农民之间的竞争使用正确的农场分析,机器会自动建议农民何时在他的农场使用化学品,从而节省他的金钱、精力和环境退化。您可以查看本网站了解更多我国农业界面临的问题。find abnormalities in crop growth, photosynthesis rate, extreme climate and need for smart green house adaptation.stop using excess fertilizers, pesticides, insecticides to boost production.
2)使用音频分析检测某些有益和有害的生物:
花可以听到蜜蜂的嗡嗡声——这使它们的花蜜更甜
农民正在使用大量化学品来提高他们的农场产量,但我们往往忘记,由于过度使用这些杀虫剂、杀虫剂和无机肥料、异花授粉剂,节肢动物(地球上发现的 90% 的生物体都是昆虫)不会不要被这些植物吸引或因过度接触化学物质和污染而死亡。超过2,000 种传粉昆虫现在已经灭绝,如果不加以保护,只有500 种会灭绝。
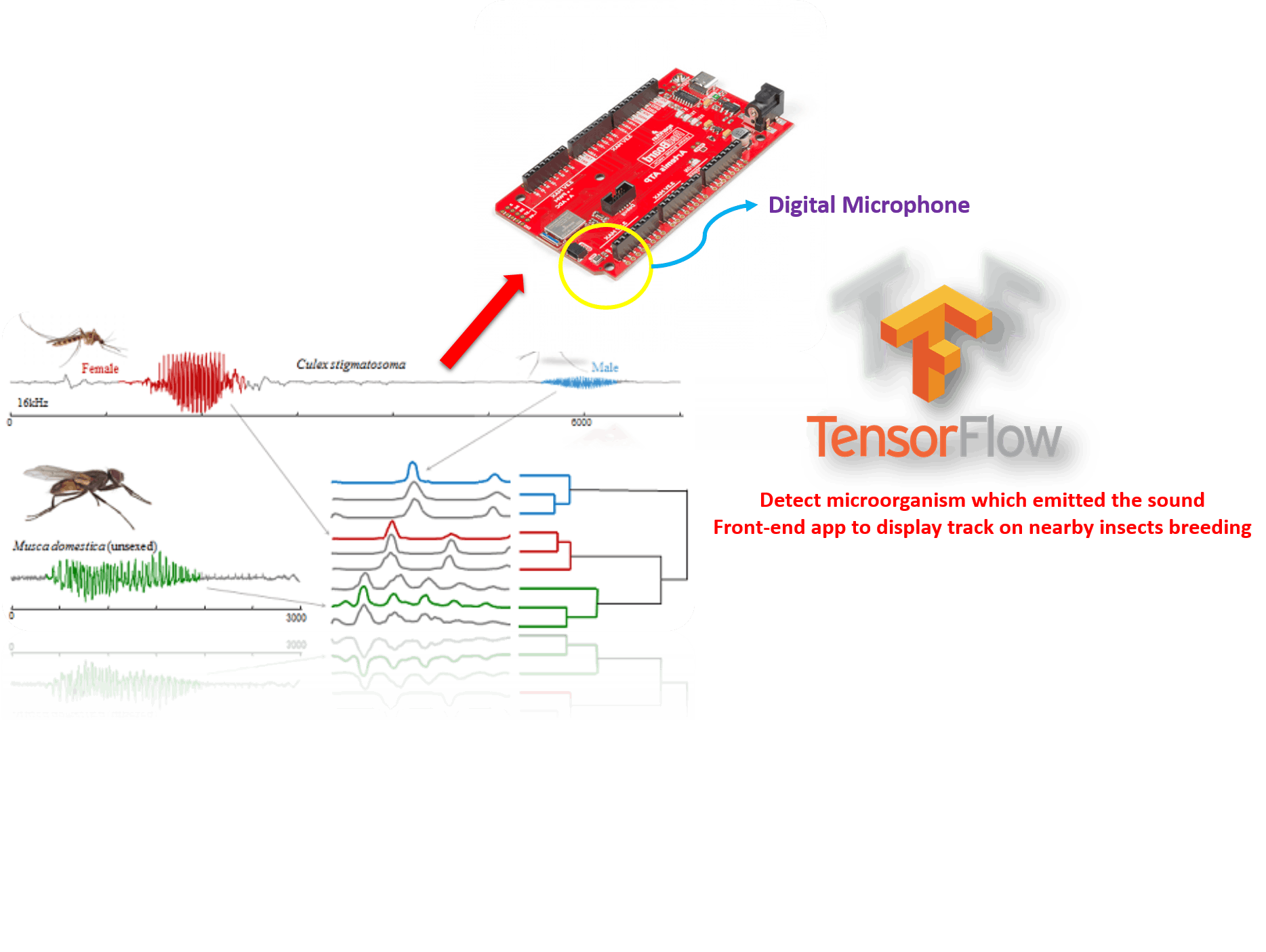
我们还需要尽早发现作物病害,以阻止其在农场传播。为了解决这个问题,我想为什么不告诉农民只有在有任何不良生长模式或有害害虫时才使用化学品,如今即使没有疾病,农民也无用地喷洒化学品并杀死蜜蜂等有用的昆虫。它还可以检测某些授粉剂以及它们在田间的频率,根据观察它可以帮助农民种植观赏植物,也可以通过声音和频率检测到破坏作物的大型动物。现在我训练我的设备来识别几种蚊子的声音,比如伊蚊、库蚊和按蚊,还有蜜蜂. 我还将添加蟋蟀、蝗虫和其他一些害虫,因为我有一个非常小的数据集。这里的重点是,一旦出现任何害虫迹象,农民或政府可以在它传播到各处之前采取行动,用户也可以确切地知道从哪个设备接收到的信号。阅读这篇文章https://www.aljazeera.com/news/2020/01/200125090150459.html
如果上述问题不解决,那么整个世界将陷入粮食危机之中。“东非蝗虫爆发引发国际援助呼声”
3) 停止砍伐森林:
有很多非法砍伐树木,所以我的设备可以通过声音分析技术让有关部门意识到砍伐树木,特别是它可以检测木材切割工具的声音和频率。
4) 预测野火并适应极端情况:
如果我们能够分析来自环境传感器和气体传感器的数据,我们就可以轻松预测野火,也可以让设备学会在植物没有获得最佳温度和光照的情况下采取行动,以便设备可以激活温室模式。
[Note: Please look every image carefully in this section,each image contains critical data required to run model successfully]
我们走吧!
音频分类:
第 1 步:收集音频分析所需的数据集:
我从 kaggle 数据集中获得了不同种类的蚊翅拍、蜜蜂的音频文件,你也可以从那里下载,文件很大,但我们不需要那么多数据集,因为我们的设备内存很小,所以我们会限制我们的每个班级的 200 个音频文件,每个 1 秒的话语。同样,您可以通过这种方式获得电锯、蝗虫、板球。如果你有一个有昆虫的安静房间,你也可以记录你自己的数据,那会更好,更准确,这会非常令人兴奋,但由于学校考试压力很大,我无法这样做。注意:如果我们直接加载为训练过程下载的音频数据,它将无法工作,因为麦克风架构会有所不同,并且设备将无法识别任何东西。因此,一旦下载了文件,我们需要通过 Artemis 麦克风再次对其进行录制,以便我们可以对准确用于运行推理的数据进行训练。因此,让我们为 Artemis Redboard ATP 配置我们的 Arduino IDE,请查看以下链接。
选择板作为 Artemis ATP,然后从 File->Examples->Sparkfun Redboard Artemis Example->PDM->Record_to_wav
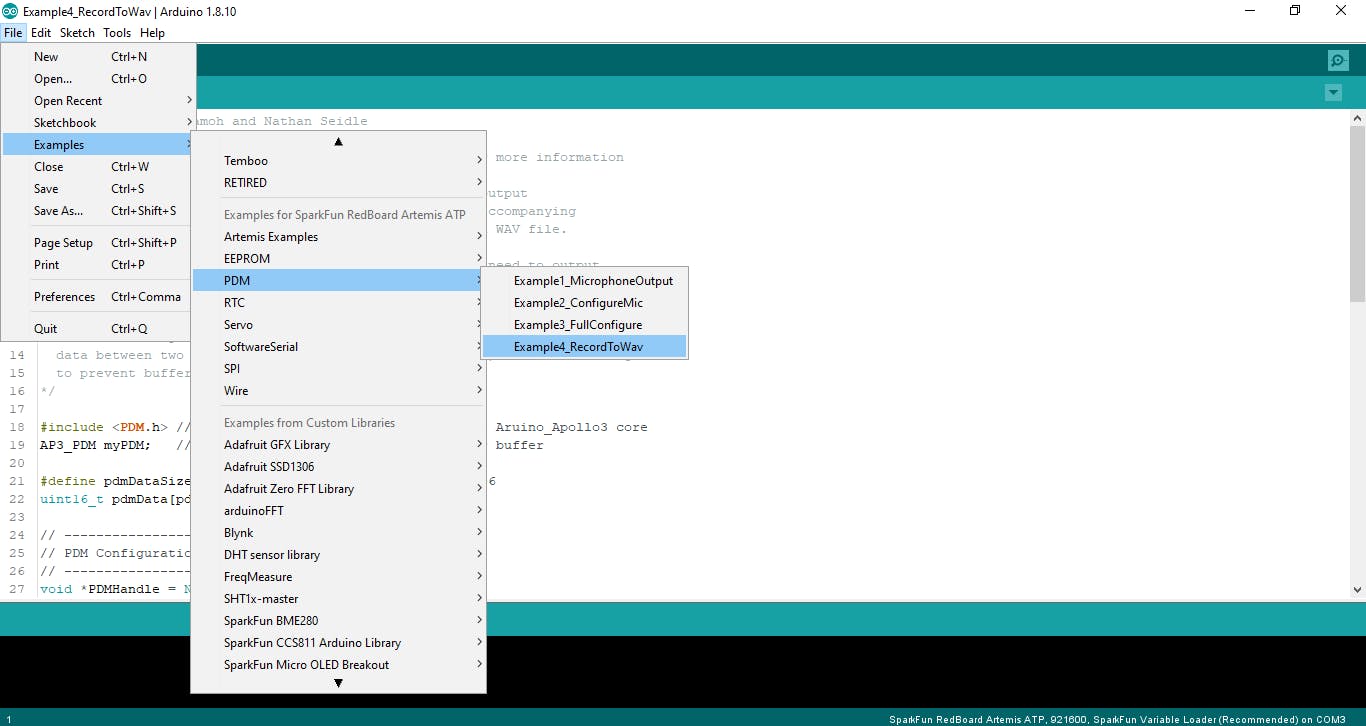
除了代码之外,还有一个 python 脚本,您需要运行它来录制来自板载麦克风的音频。这是非常必要的,因为音频文件来自不同的麦克风,因此电路板可能无法准确识别频率并将声音视为噪音。
(Protip:录音时,通过缓慢地来回移动声源来模拟真实的昆虫靠近麦克风,从而使气柱发生变化,以便我们获得更好的结果。我自己尝试过,它提高了准确性。)
#!/usr/bin/python
from __future__ import division
"""
Author: Justice Amoh
Date: 11/01/2019
Description: Python script to stream audio from Artemis Apollo3 PDM microphone
"""
import sys
import serial
import numpy as np
import matplotlib.pyplot as plt
from serial.tools import list_ports
from time import sleep
from scipy.io import wavfile
from datetime import datetime
# Controls
do_plot = True
do_save = True
wavname = 'recording_%s.wav'%(datetime.now().strftime("%m%d_%H%M"))
runtime = 50#100 # runtime in frames, sec/10, set it according to your audio duration default is 5 seconds, I set it to 4 minutes as per my audio duration
# Find Artemis Serial Port
ports = list_ports.comports()
try:
sPort = [p[0] for p in ports if 'cu.wchusbserial' in p[0]][0]
except Exception as e:
print 'Cannot find serial port!'
sys.exit(3)
# Serial Config
ser = serial.Serial(sPort,115200)
ser.reset_input_buffer()
ser.reset_output_buffer()
# Audio Format & Datatype
dtype = np.int16 # Data type to read data
typelen = np.dtype(dtype).itemsize # Length of data type
maxval = 32768. # 2**15 # For 16bit signed
# Plot Parameters
delay = .00001 # Use 1us pauses - as in matlab
fsamp = 16000 # Sampling rate
nframes = 10 # No. of frames to read at a time
buflen = fsamp//10 # Buffer length
bufsize = buflen*typelen # Resulting number of bytes to read
window = fsamp*10 # window of signal to plot at a time in samples
# Variables
x = [0]*window
t = np.arange(window)/fsamp # [x/fsamp for x in range(10)]
#---------------
# Plot & Figures
#---------------
plt.ion()
plt.show()
# Configure Figure
with plt.style.context(('dark_background')):
fig,axs = plt.subplots(1,1,figsize=(7,2.5))
lw, = axs.plot(t,x,'r')
axs.set_xlim(0,window/fsamp)
axs.grid(which='major', alpha=0.2)
axs.set_ylim(-1,1)
axs.set_xlabel('Time (s)')
axs.set_ylabel('Amplitude')
axs.set_title('Streaming Audio')
plt.tight_layout()
plt.pause(0.001)
# Start Transmission
ser.write('START') # Send Start command
sleep(1)
for i in range(runtime):
buf = ser.read(bufsize) # Read audio data
buf = np.frombuffer(buf,dtype=dtype) # Convert to int16
buf = buf/maxval # convert to float
x.extend(buf) # Append to waveform array
# Update Plot lines
lw.set_ydata(x[-window:])
plt.pause(0.001)
sleep(delay)
# Stop Streaming
ser.write('STOP')
sleep(0.5)
ser.reset_input_buffer()
ser.reset_output_buffer()
ser.close()
# Remove initial zeros
x = x[window:]
# Helper Functions
def plotAll():
t = np.arange(len(x))/fsamp
with plt.style.context(('dark_background')):
fig,axs = plt.subplots(1,1,figsize=(7,2.5))
lw, = axs.plot(t,x,'r')
axs.grid(which='major', alpha=0.2)
axs.set_xlim(0,t[-1])
plt.tight_layout()
return
# Plot All
if do_plot:
plt.close(fig)
plotAll()
# Save Recorded Audio
if do_save:
wavfile.write(wavname,fsamp,np.array(x))
print "Recording saved to file: %s"%wavname
录制音频后,您可以使用任何音频拆分器将音频文件拆分为 1 秒。我将以下代码与 jupyter notebook 一起使用来实现上述步骤。
from pydub import AudioSegment
from pydub.utils import make_chunks
myaudio = AudioSegment.from_file("myAudio.wav" , "wav")
chunk_length_ms = 1000 # pydub calculates in millisec
chunks = make_chunks(myaudio, chunk_length_ms) #Make chunks of one sec
#Export all of the individual chunks as wav files
for i, chunk in enumerate(chunks):
chunk_name = "chunk{0}.wav".format(i)
print "exporting", chunk_name
chunk.export(chunk_name, format="wav")
我使用 Audacity 来清理我下载的音频文件,然后再将它们切片,还有一些非常棒的功能可以用来判断你的音频是否纯净,音频频谱图。
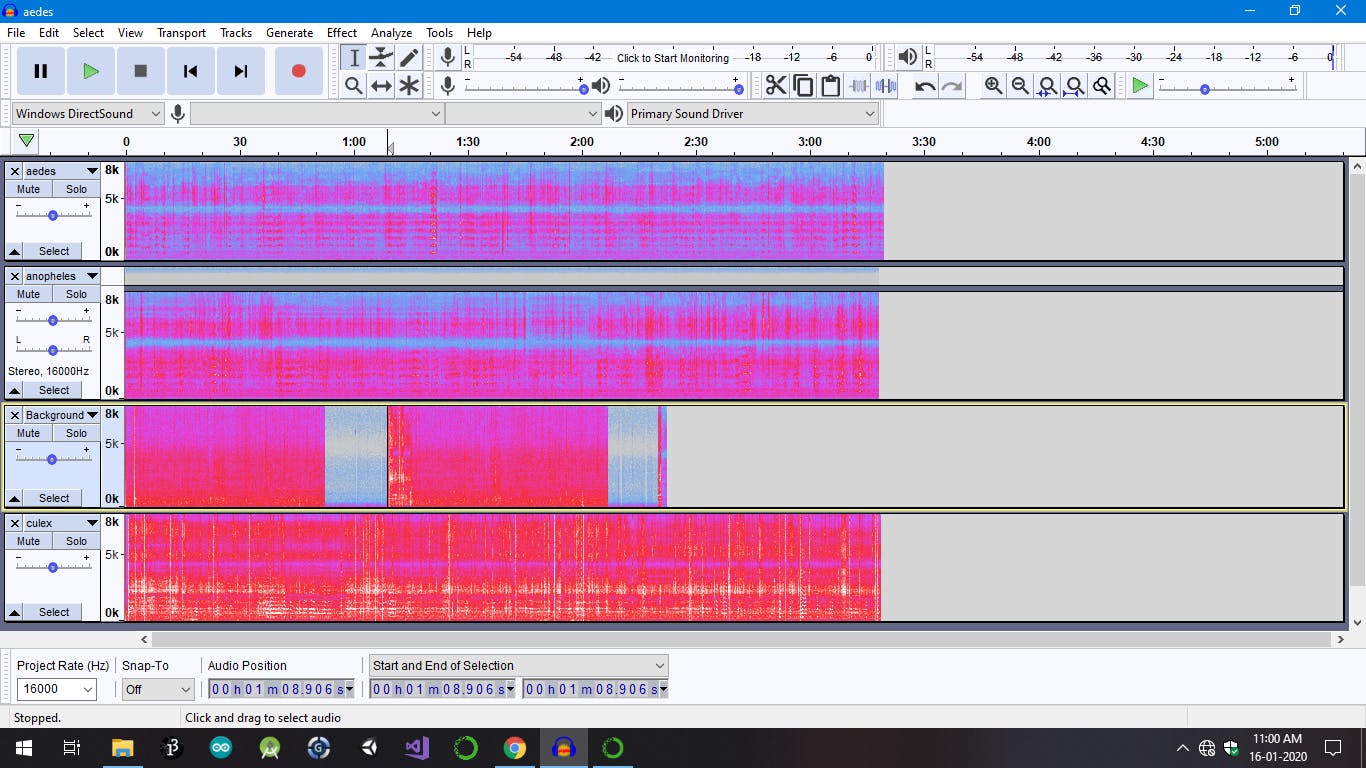
分割音频文件后,您就可以为 Artemis 训练这些文件了。但是,您需要调整以使其完美运行,因为由于外壳或工作环境,数据可能包含大量噪声,因此我建议您也训练背景数据集,以便即使存在持续的特殊噪声也可以工作。背景包含 Audacity 软件中所有修剪过的音频片段和一些明显的噪音。
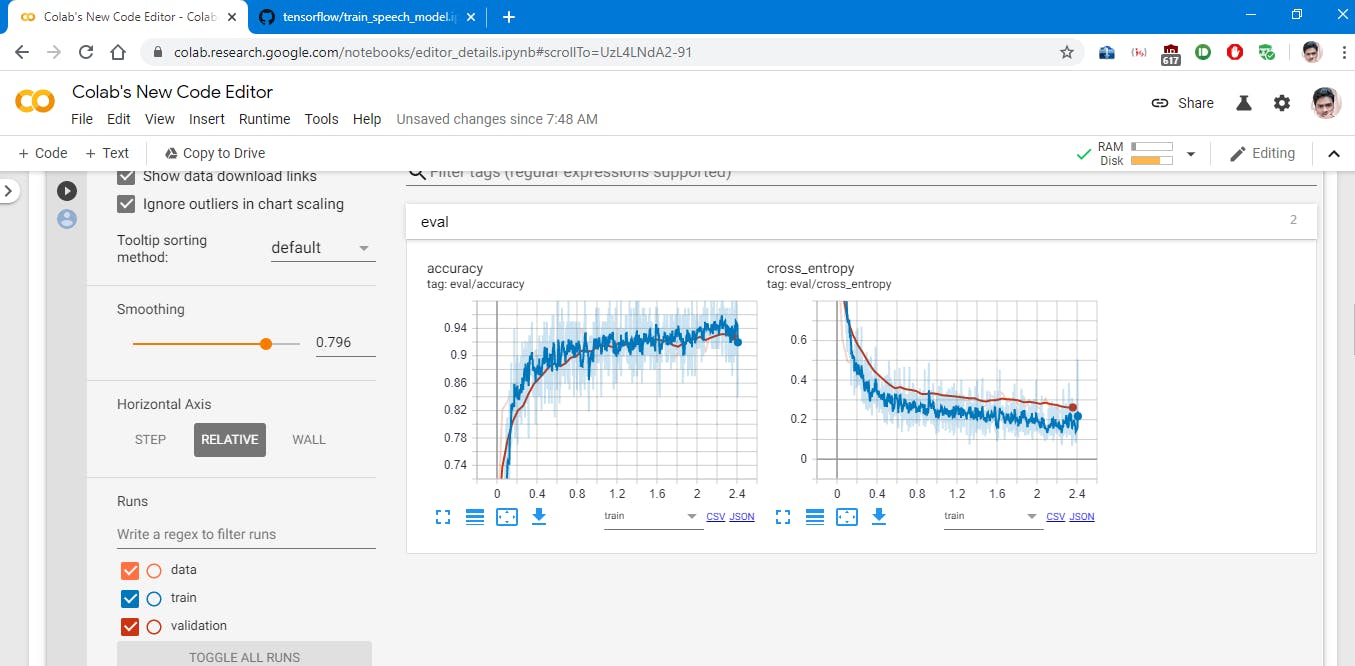
我使用 Google Colab 进行训练,下面是完整的训练过程图像,您需要在 Colab notebook 中训练时上传这些文件并在 GPU 上运行,对我来说花了将近 2 个小时。我不得不训练三次,因为由于我的互联网连接速度慢,笔记本一直断开连接,所以我首先训练了一个小数据集,只有蜜蜂、蚊子(没有基因或品种分类)和电锯,然后我训练了整个数据集两次,幸运的是我成功了。
第 2 步:训练音频数据
音频培训 #1:标签 = 蚊子、蜜蜂、电锯
训练完成后,我们需要冻结模型并将其转换为 lite 模型以在 Edge 设备中使用。我将附上代码以及所有必需的注释。
音频培训 #2:标签 = 伊蚊、库蚊、按蚊、蜜蜂、电锯
下载上述步骤生成的所有文件,还需要为每个类音频文件生成微特征文件,我将在我们编写设备时解释这一点。您还可以阅读 TensorFlow Lite for Microcontrollers 文档以获取更多信息。
数据分类:
第 1 步:收集所需行为和不良行为的传感器数据
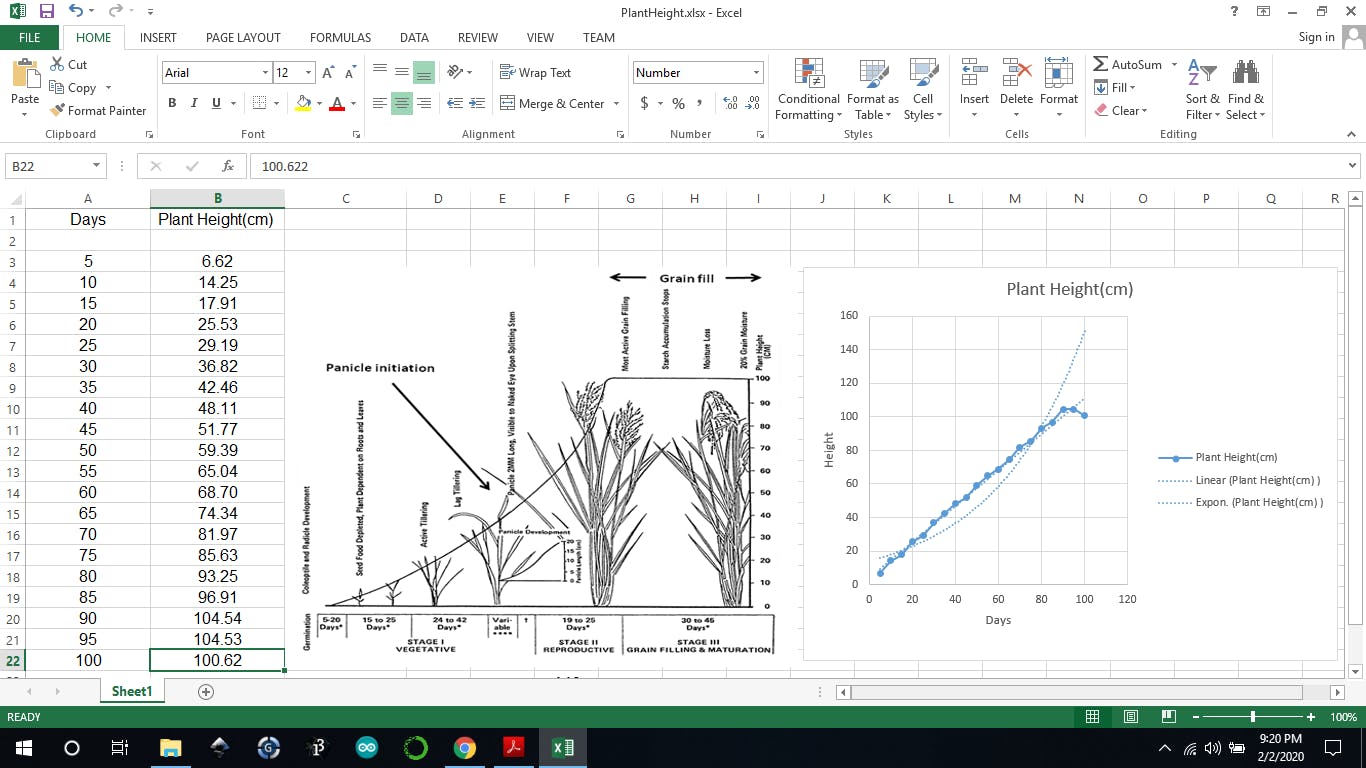
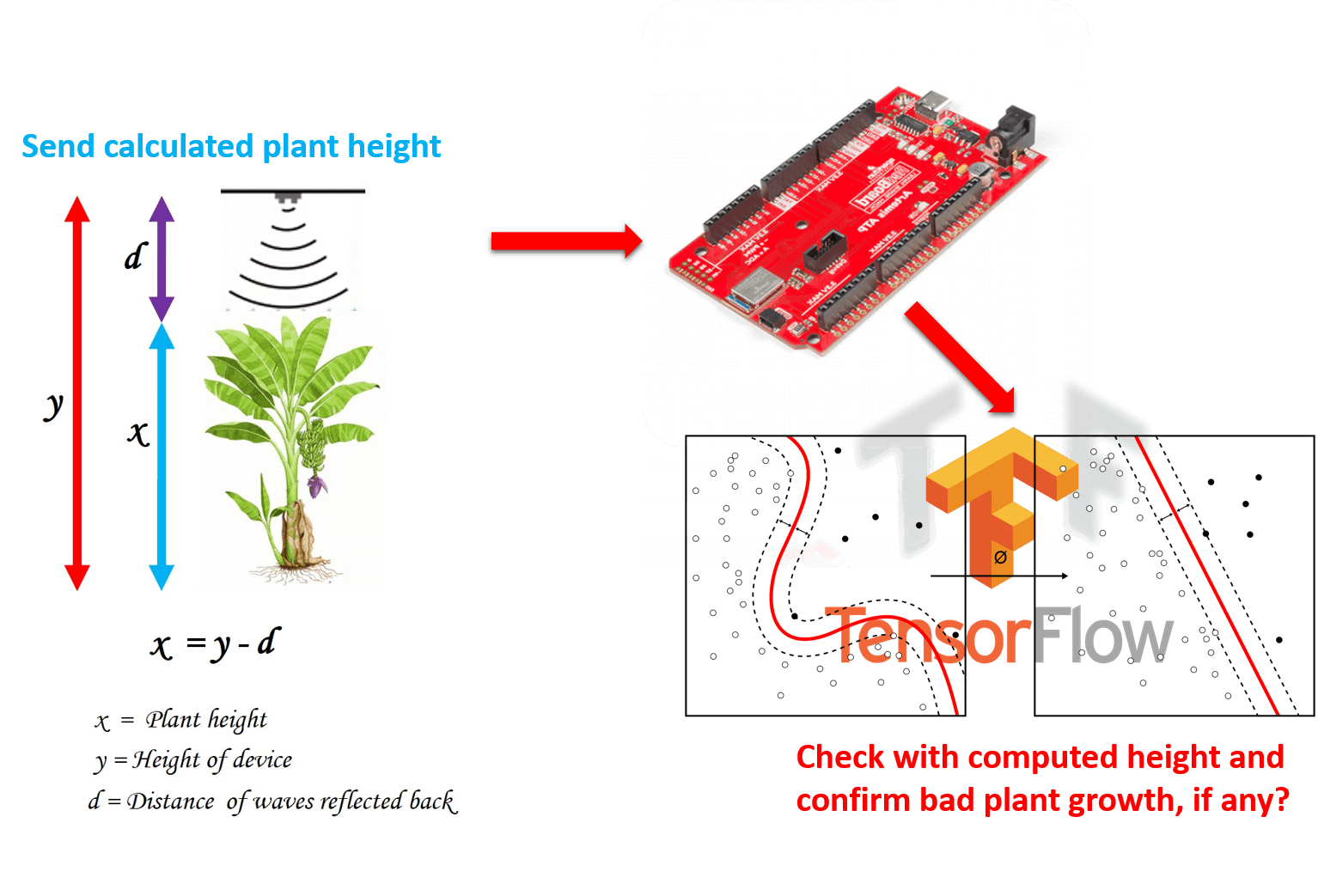
1) 株高:我使用我过去的项目来确定发芽后的水稻株高,但这还不够,因为只要印度没有 SigFox 连接,我就可以让我的设备保持开启状态,所以无论我得到什么读数,我都使用 Excel数学统计函数,回归技术来找到所有其他点并添加一些噪音。我真的很抱歉为 ML 提供了小数据集,但幸运的是它适合我的应用程序,如果有一天我将它变成一个商业产品,那么我会通过生成合成数据来扩展我的数据集。
2)火灾预测:我使用环境组合快速传感器收集正常读数以及火灾情况读数。对于火灾,我们需要 himidiy、温度、tVOC、CO2 读数。所以基本上我们正在使用回归技术制作分类模型来进行预测。我使用传感器的示例代码来获取所有读数。检测野火是非常重要的功能。
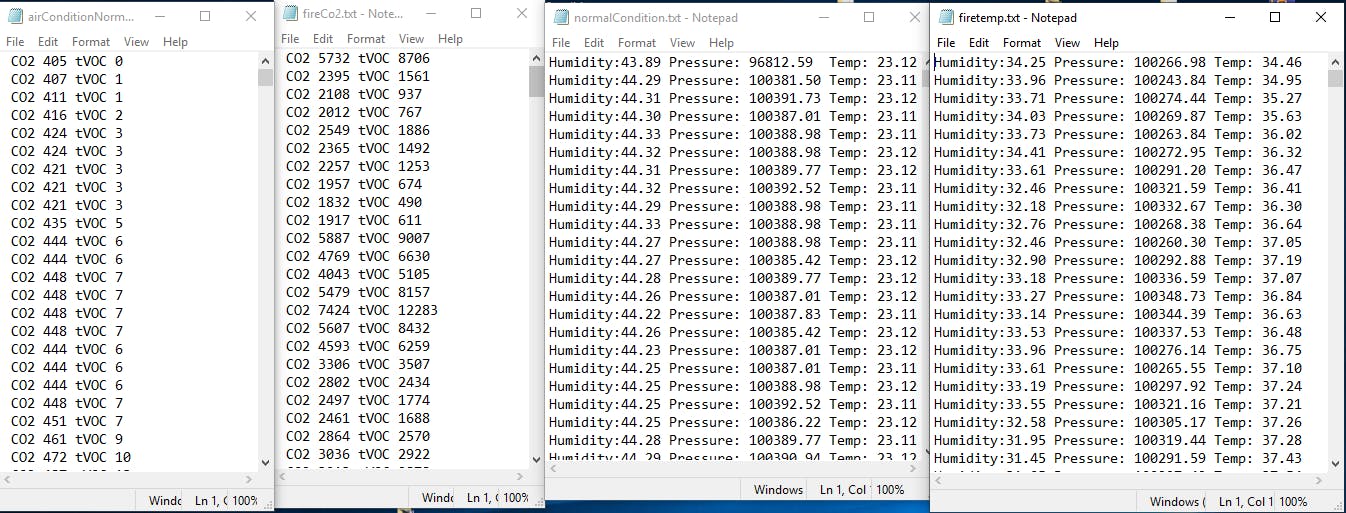
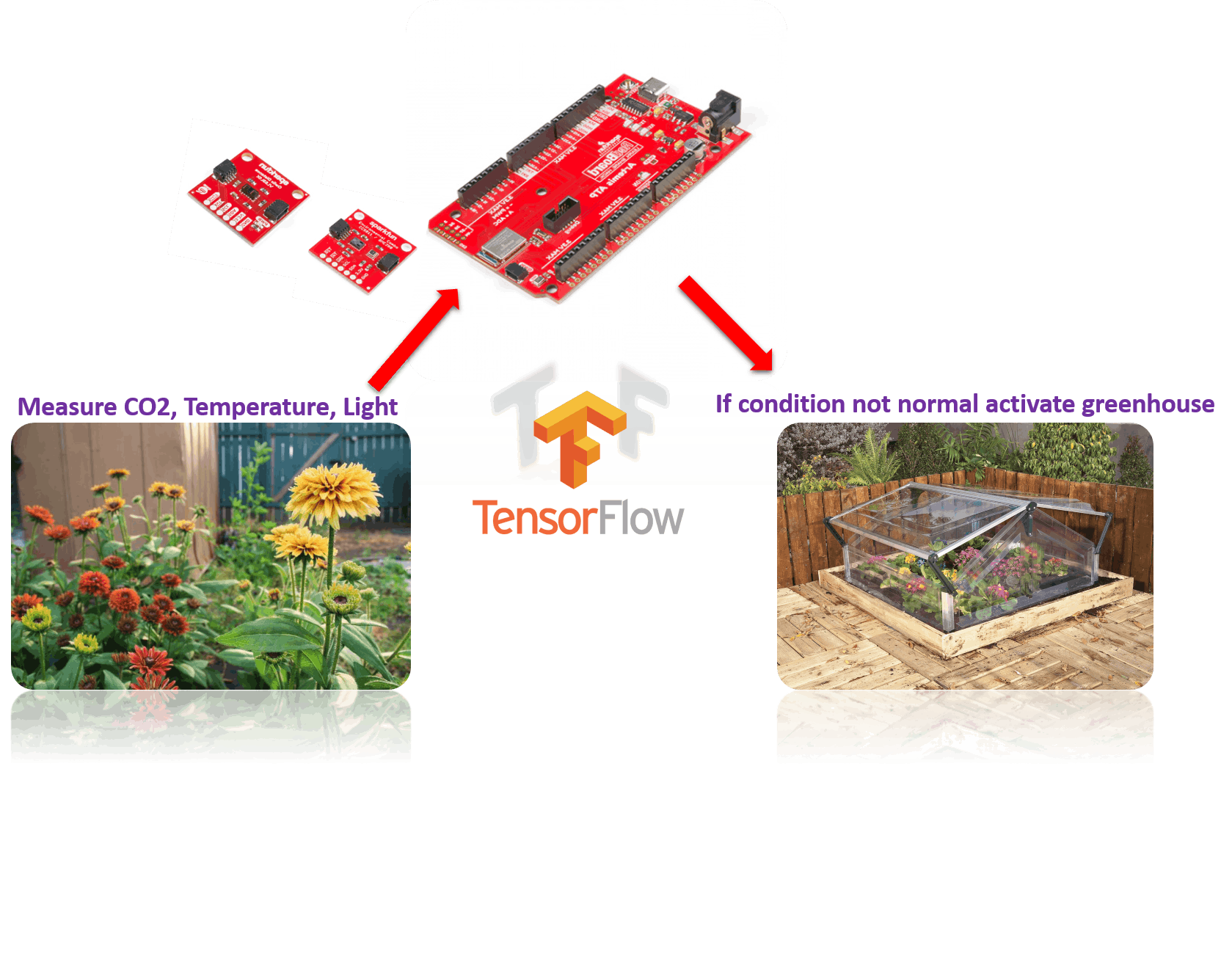
3) 温室适应:我使用 quiic VCNL4040 模块来检测环境光照水平和用于温度和 CO2 传感的环境组合传感器。根据数据,设备可以预测何时适应温室模式以拯救农作物。它可以进一步优化以保护作物免受冰雹或大雪的影响。
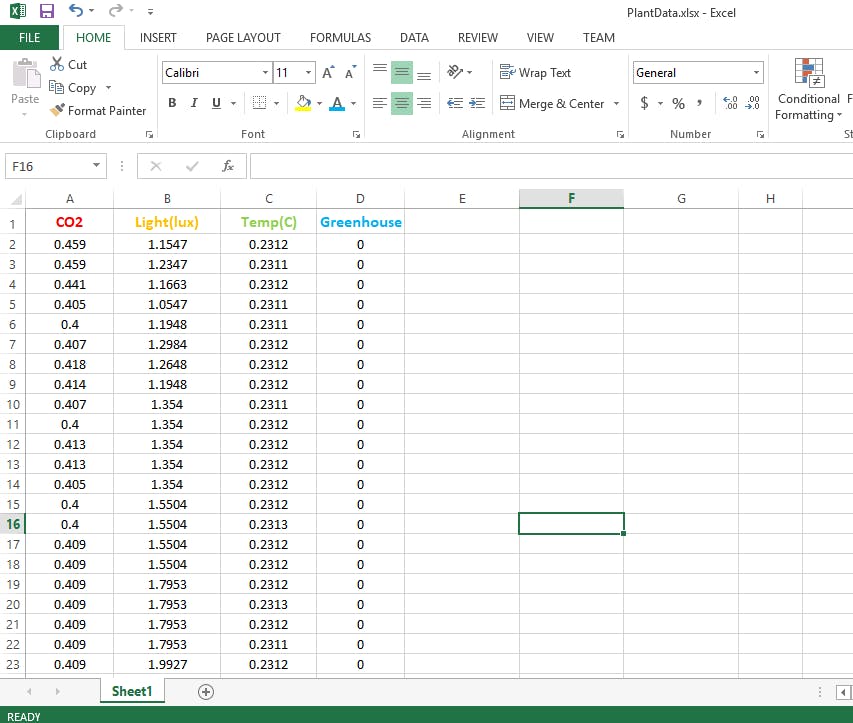
第 2 步:使用深度学习训练数据
永远不要在没有规范化的情况下进行任何训练,因为你永远不会看到你的模型提高它的准确性。下面是我训练过程的一些图像,任何人都可以知道训练过程中发生了什么。
培训#1:火灾预测
我使用了'adam'优化器和'binary_crossentropy'损失,它们比任何其他方法都工作得更好,你可以相应地使用任何方法。其他数据集也遵循相同的训练步骤。sigmoid也用作输出层的激活函数,因为 sigmoid 适用于非线性数据和二进制预测
培训#2:温室适应预测
神经网络的回归模型配置与火灾预测模型相同。输出预测将帮助用户根据相关传感器数据了解植物是否获得了足够的二氧化碳、光照、温暖,如果没有,则设备可以采取行动适应温室(我会告诉我们何时编码设备)。
培训#3:植物生长追踪
这里使用rmsprop代替adam优化器,并使用mse作为损失函数。在此,我训练了底层神经网络以识别与天相关的生长模式,因此我将使用它根据天数从模型中计算植物高度,并检查我的传感器读数是否值差异很大,这意味着植物那个季节长得不好。
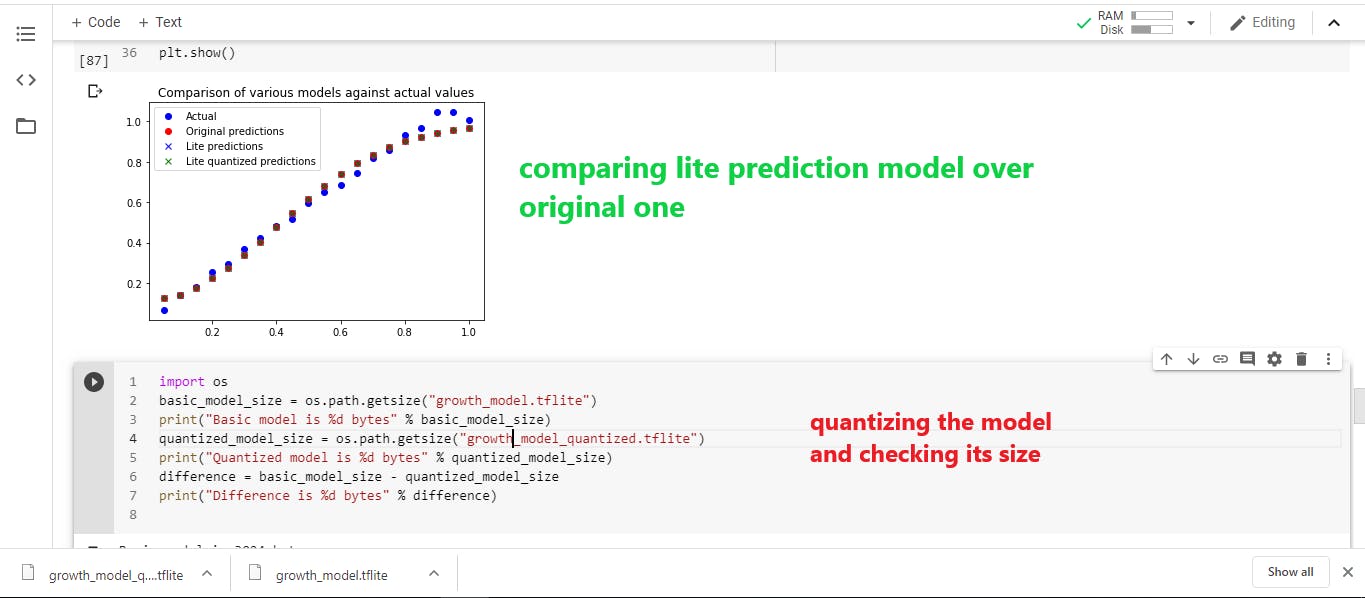
由于我们已经完成了所有的培训步骤,我们将着手对设备进行编程。
准备好我们的代码:
在这里,我将描述我们所有项目实现共有的所有头文件,
#include "xyz_model_data.h"
我们使用 xxd 训练、转换并转换为 C++ 的模型
#include "tensorflow/lite/experimental/micro/kernels/all_ops_resolver.h"
一个允许解释器加载我们模型使用的操作的类
#include "tensorflow/lite/experimental/micro/micro_error_reporter.h"
一个可以记录错误和输出以帮助调试的类
#include "tensorflow/experimental/lite/micro/micro_interpreter.h"
TensorFlow Lite for Microcontrollers 解释器,它将运行我们的模型
#include "tensorflow/lite/schema/schema_generated.h"
定义 TensorFlow Lite FlatBuffer 数据结构的模式,用于理解 sine_model_data.h 中的模型数据
#include "tensorflow/lite/version.h"
模式的当前版本号,因此我们可以检查模型是否使用兼容版本定义。
//You need to install Arduino_Tensorflow_Lite library before proceeding.
#include
在 void setup() 函数之前定义了一个命名空间,命名空间用于解决不同包之间的名称冲突。您还需要为张量和其他相关操作分配内存。
namespace
{
tflite::ErrorReporter* error_reporter = nullptr;
const tflite::Model* model = nullptr;
tflite::MicroInterpreter* interpreter = nullptr;
TfLiteTensor* input = nullptr;
TfLiteTensor* output = nullptr;
// Create an area of memory to use for input, output, and intermediate arrays.
// Finding the minimum value for your model may require some trial and error.
constexpr int kTensorArenaSize = 6 * 1024;
uint8_t tensor_arena[kTensorArenaSize];
} // namespace
您可以从 Arduino IDE 示例部分中的 Arduino Tensorflow Lite 示例开始,只需将转换后的 lite 模型数据传输到 model_data.h 文件,然后根据预测模型的输出采取任何行动。
编程、模型测试和连接 Sparkfun Artemis 设备:

测试#1:音频分析-
检查我们的语音模型并在 OLED 屏幕上显示结果。如果您对整个项目的编程没有信心,您可以选择示例项目并将其作为基础修改它,您将很容易学会以这种方式进行调试。图片没有详细显示,因此我已经上传了代码,但您仍然需要根据您的项目对其进行调整。您还可以轻松修改它,根据检测到的声音(如蚊子)将结果发送到移动设备或基站,这样人们就可以轻松查看当地此类昆虫最常见的地方并防止其繁殖或制造自动化无人机导航系统在农场区域喷洒特定的杀虫剂、杀虫剂或通知机构有关非法采伐的全面精确控制。在下面查看我们的测试结果图像。
我们已经完成了我们项目的音频分析模型的训练和编程,现在我将继续编程其他基于价值的输出模型。
测试#2:火灾预测-
我们将数据模型加载到板上,然后对我们的传感器值进行实时预测,根据预测,我们将在 OLED 屏幕上显示通知,从而消除农场大面积火灾的可能性。这真的花了我大部分时间,因为无论我多么努力,我的董事会每次都会给我编译错误。但是感谢 Hackster 社区,他们帮助我成功上传了代码。

测试#3:温室预测
这里我们将利用环境光、温度和CO2浓度检测传感器来预测是否有足够的光、温度和CO2可供植物生长,如果条件不正常,我们将引导伺服电机启动并通过带来保护植物来保护植物。像温室设置一样在农场上层。
测试#4:植物高度测定
我们已经训练我们的模型通过回归来确定植物高度,但是回归有一个缺点,缺点是它只能确定一个线性方向的值,因此如果让它永远运行它会在某天返回植物高度(以公里为单位),如果没有上限已设置。所以我们要做的是,我们会检测对应天的植物高度,并用我们的模型检查对应天的高度,检查模型预测的高度是否与我们测量的植物高度相差很大,差异很大意味着有一些营养不足。
我附上了所有注释很好且可读性强的代码,供您实现自己的算法,不要浪费时间考虑代码,花时间使您的训练数据集尽可能好。
我没有 3D 打印机,所以我只是拿了一个塑料盒来构建我的模型,在提交想法的过程中,我们还需要指定我们的项目的外观,所以这里是安装(不是花园,因为我没有一)但我尽我最大的努力在我的最后做尽可能多的创新和创造力。对不起,伙计们,我找不到这个硬件的fritzing 部件,但接线相当简单,因为我使用了非常常见的传感器,quiic 传感器是即插即用的,所有图像都足够清晰,可以详细说明我的传感器的引脚。

您可以将您的设备设置为您想要的任何模式以及您想要的任何位置。我还想为我的植物实施水分适应,我稍后也会完成。
可持续发展目标 3:良好的健康和福祉
使用我们的设备,我们试图让当地了解所有存在或繁殖的携带疾病的媒介,而且我们能够在听到任何害虫发出的声音时立即拯救作物,因此它节省了农民的大量精力并让他们喷洒化学品只在需要时,吃得健康。
SDG 13 和 SDG 15:气候行动和陆地生物
联合国目标:到 2020 年,促进对所有类型森林实施可持续管理,停止砍伐森林,恢复退化的森林,并在全球大幅增加植树造林和重新造林。从所有来源和各级调动大量资源,为可持续森林管理提供资金,并提供充足的资源. 鼓励发展中国家推进此类管理,包括保护和重新造林。通过我们的项目,我们能够识别非法砍伐树木并将信息传达给林业部门采取行动。因此,我们很快就准备好停止森林砍伐,我还想到了另一个包括检测枪声并让政府了解特定地区的偷猎者并对他们采取严厉行动的措施。
任何人都可以向我推荐任何可以轻松实现并对社区有所帮助的新功能。直接在代码部分添加大量代码文件不是很舒服,所以我添加了github链接。感谢您仔细阅读我的想法和实现。

声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章






