
资料下载


×
一种应对倾斜数据流在线连接的方法
消耗积分:3 |
格式:rar |
大小:0.74 MB |
2017-12-18
分享资料个
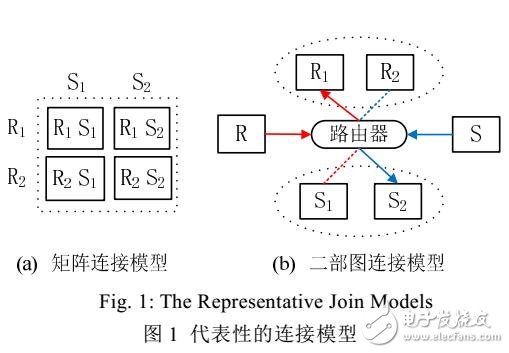
并行环境下的分布式连接处理要求制定划分策略以减少状态迁移和通信开销.相对于数据库管理系统而言,分布式数据流管理系统中的在线o连接操作需要更高的计算成本和内存资源.基于完全二部图的连接模型可支持分布式数据流的连接操作.因为连接操作的每个关系仅存放于二部图模型的一侧处理单元,无需复制数据,且处理单元相互独立,因此该模型具有内存高效、易伸缩和可扩展等特性.然而,由于数据流速的不稳定性和属性值分布的不均衡性,导致倾斜数据流的连接操作易出现集群负载不均衡的现象.针对倾斜数据流的连接操作,模型无法动态分配查询节点。并需要人工干预数据分组的参数设置.尤其是应对全部历史数据的连接查询。模型效率更低.基于上述问题,提出了管理倾斜数据流连接的框架,使用基于键值和元组混合的划分样式有效应对二部图模型的各侧倾斜数据.并设计了重新动态分配查询节点的策略和状态迁移算法,以支持全历史数据的连接查询和自适应的资源管理,针对合成数据和真实数据的实验表明,该方案可有效应对倾斜数据的连接操作并进一步提升分布式数据流管理系统的吞吐率。特别是降低云环境中的计算成本.

声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章






