
资料下载


如何实现非平稳噪声环境下的语音增强
高瑾妍
分享资料个
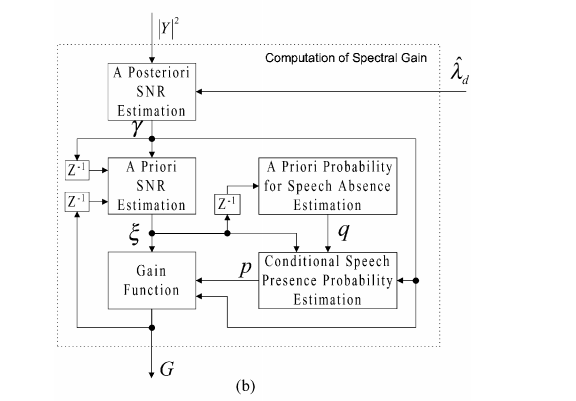
本文提出了一种最优修正对数谱幅度(OM-LSA)语音估计器和一种用于鲁棒语音增强的最小控制递归平均(MCRA)噪声估计方法。将频谱增益函数作为与语音存在不确定性相关的假设增益的加权几何平均值,将其最小化。噪声估计是通过平均过去的频谱功率值,使用一个平滑参数,这是由语音存在概率在子带调整。我们引入了两个不同的语音存在概率函数,一个用于估计语音,另一个用于控制噪声频谱的自适应。前者基于先验信噪比的时频分布。后者由特定时间窗内噪声信号的局部能量与其最小能量之比决定。不同环境条件下的主客观评价结果表明,OM-LSA和MCRA估计器的优越性。在保留微弱语音成分的同时,避免了音乐残余噪声现象,取得了良好的噪声抑制效果。?2001爱思唯尔科学公司版权所有。
一个实用的语音增强系统一般由两个主要部分组成:噪声功率谱估计和语音估计。当只提供一个传声器源时,噪声估计是基于缓慢噪声环境的假设。特别是,在言语活动中,噪声频谱几乎保持平稳。语音估计是基于假设的统计模型、失真度量和估计的噪声。
估计噪声功率谱的一种常用方法是在不包含语音的部分上对噪声信号进行平均。一种快速判决语音停顿检测方法要么逐帧实现,要么使用后验信噪比(SNR)对单个子带进行独立估计。然而,对于弱语音成分和低输入信噪比,检测可靠性很高。另外,信号中可能存在的非语音部分的数量可能不确定,这就限制了噪声估计器在非平稳环境下的跟踪能力。或者,噪声可以通过功率谱域的直方图来估计,不幸的是,这种方法的计算成本很高。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章




