
资料下载


×
基于文本的细粒度美妆图谱视觉推理问题
消耗积分:0 |
格式:rar |
大小:2.10 MB |
2021-04-23
分享资料个
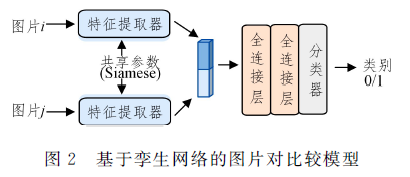
文中研究了化妆领域中基于文本的细粒度视觉推理问题,具体探究了一个新颖的多模态任务,即根据有序的化妆步骤描述,对化妆过程中打乱顺序的人脸图片进行排序。针对这个新颖的任务,通过数据的处理和分析,提岀了两个排序模型:第个排序模型从单模态的角度岀发,只利用图片的信息进行排序;第二个模型从多模态的角度岀发,通过建立文本描述和图片之间的联系来指导图片排序。在 You MakeupⅤ Qachallenge数据集上进行了详实的实验以及分析,实验结果表明,所提出的两个模型在不同的图片对数据上具有互补性,在美妆图片排序任务上具有良妤的表现,在测试集上的选择准确率分别达到了70%和58.93%。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章




