
资料下载


使用TinyML来预测与气压系统(APS)故障
岳臻俊
分享资料个
描述
介绍
汽车行业是采用尖端技术的先驱之一,机器学习也不例外。借助 ML 解决方案,工程师现在可以构建神经网络来检测各种汽车缺陷和破损。在本文中,我想展示从业者如何轻松应用 TinyML 方法,在原始微型设备上创建和部署基于 AI 的解决方案,以预测与气压系统 (APS) 相关的卡车故障。
作为重型车辆的重要组成部分,APS 产生的加压空气用于卡车的各种功能,例如制动和换档,因此及时的故障检测可以减少停机时间和故障花费的总成本高达在一定程度上,还简化了对司机和员工的卡车检查过程,使其不易出错。
业务约束
- 延迟:获取数据后进行预测所花费的时间必须相当短,以避免不必要的维护时间和成本增加。
- 设备成本:拥有沉重的 GPU,昂贵的边缘设备会增加不必要的维护成本。相反,重点应该放在更好的传感器和具有更高准确性和低内存占用的定制 AutoML/TinyML 解决方案上。
- 错误分类的成本:错误分类的成本非常高,特别是如果错误地分类了正类数据点,因为它可能导致卡车完全故障并产生一些严重的成本。
使用的技术
- Neuton TinyML:Neuton 是一个基于专利神经网络框架的无代码平台。我为我的实验选择了这个解决方案,因为它可以免费使用并自动创建微型机器学习模型,甚至可以在 8 位 MCU 上部署。根据 Neuton 开发人员的说法,您可以在一次迭代中创建一个紧凑的模型,而无需压缩。
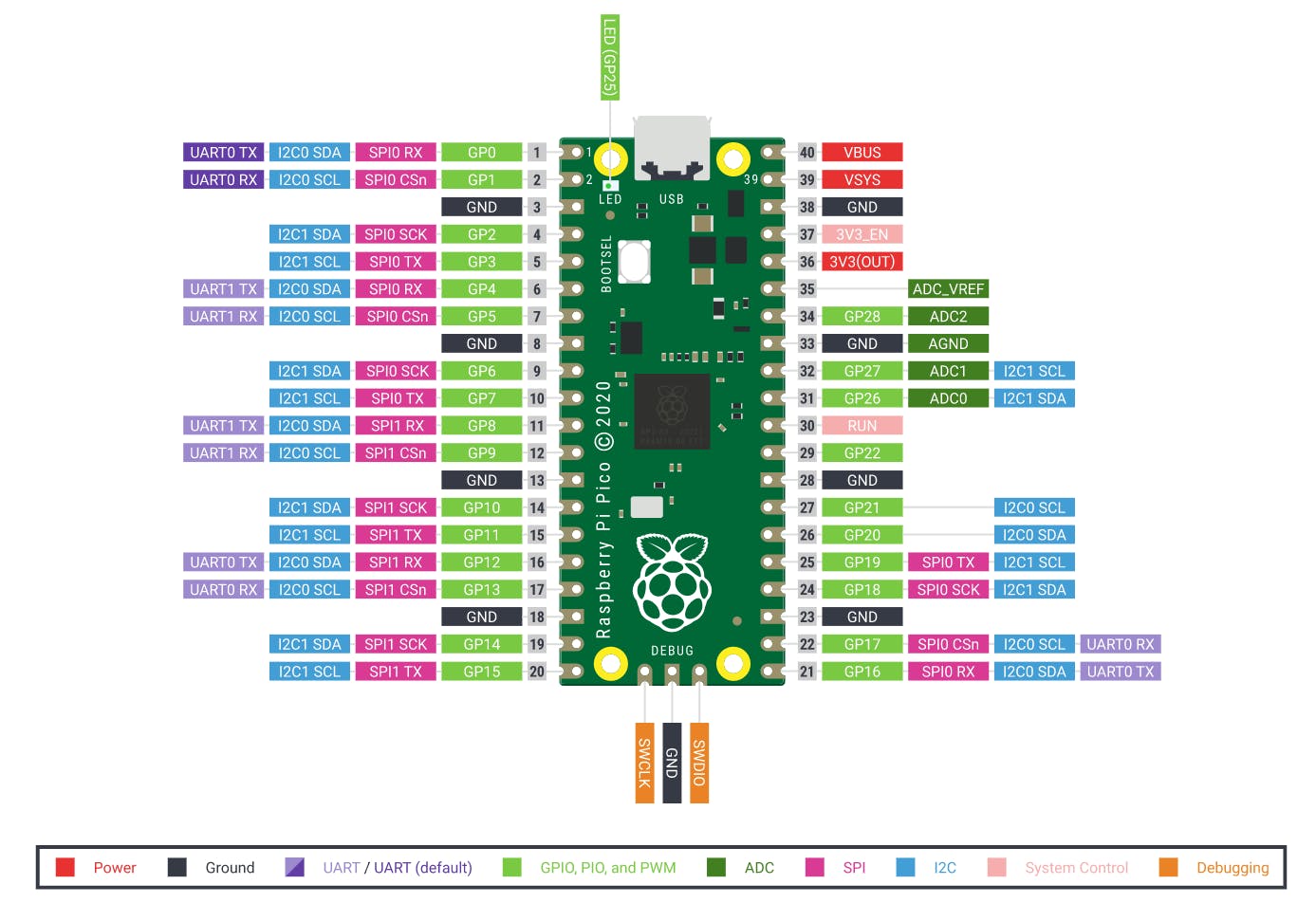
- Raspberry Pi Pico:该芯片采用两个 ARM Cortex-M0 + 内核,133 兆赫,安装在芯片上时还与 256 KB 的 RAM 配对。该器件支持高达 16 MB 的片外闪存,具有一个 DMA 控制器,包括两个 UART 和两个 SPI,以及两个 I2C 和一个 USB 1.1 控制器。该器件接收16个PWM通道和30个GPIO针,其中4个适合模拟数据输入。并带有 4 美元的净价格标签。
让我们构建它
本教程的目标是演示如何轻松构建紧凑的 ML 模型来解决二进制分类任务,其中正类意味着卡车中的问题是由于 APS 中的故障而负类意味着其他问题。
在我们的案例中,我们使用了使用斯堪尼亚卡车在日常使用中获取的读数(由斯堪尼亚自己收集和提供)制成的数据集。由于专有原因,所有功能的名称都是匿名的。此案例研究的数据集可在此处找到:https ://archive.ics.uci.edu/ml/datasets/APS+Failure+at+Scania+Trucks
该实验将在 4 美元的 MCU 上进行,没有云计算碳足迹 :)
数据集描述
数据集分为两部分,一个训练集和一个测试集。训练集包含60, 000 行,而测试集包含16, 000 行。数据集中有 171 列,其中之一是数据点的类标签,每个数据点有 170 个特征。
第 1 步:创建新解决方案并在 Neuton TinyML 平台上上传数据集
登录到 Neuton 帐户后,您应该有一个解决方案主页,单击添加新解决方案按钮。
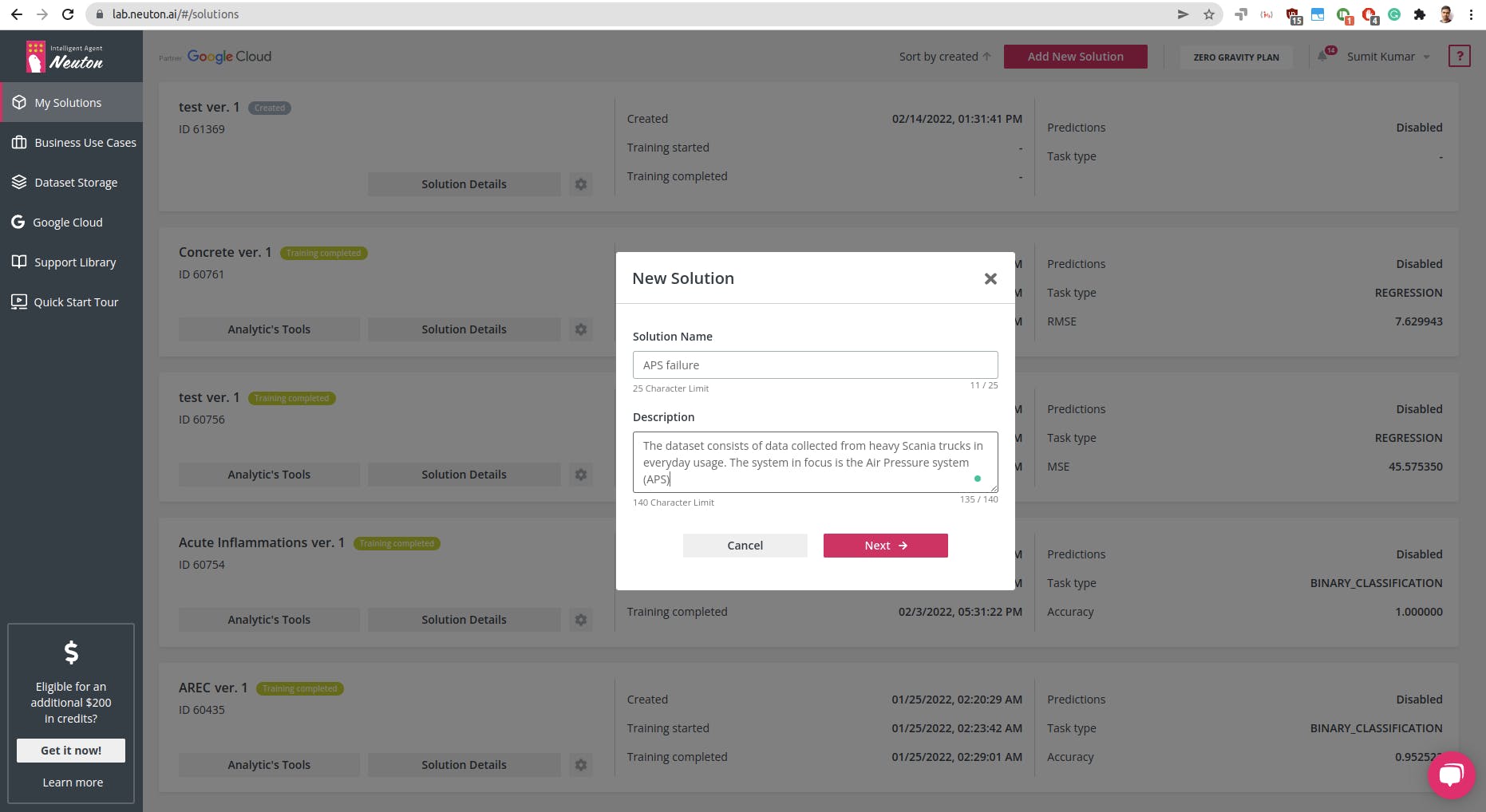
创建解决方案后,如上所示,继续上传数据集(请记住,当前支持的格式仅为 CSV)。
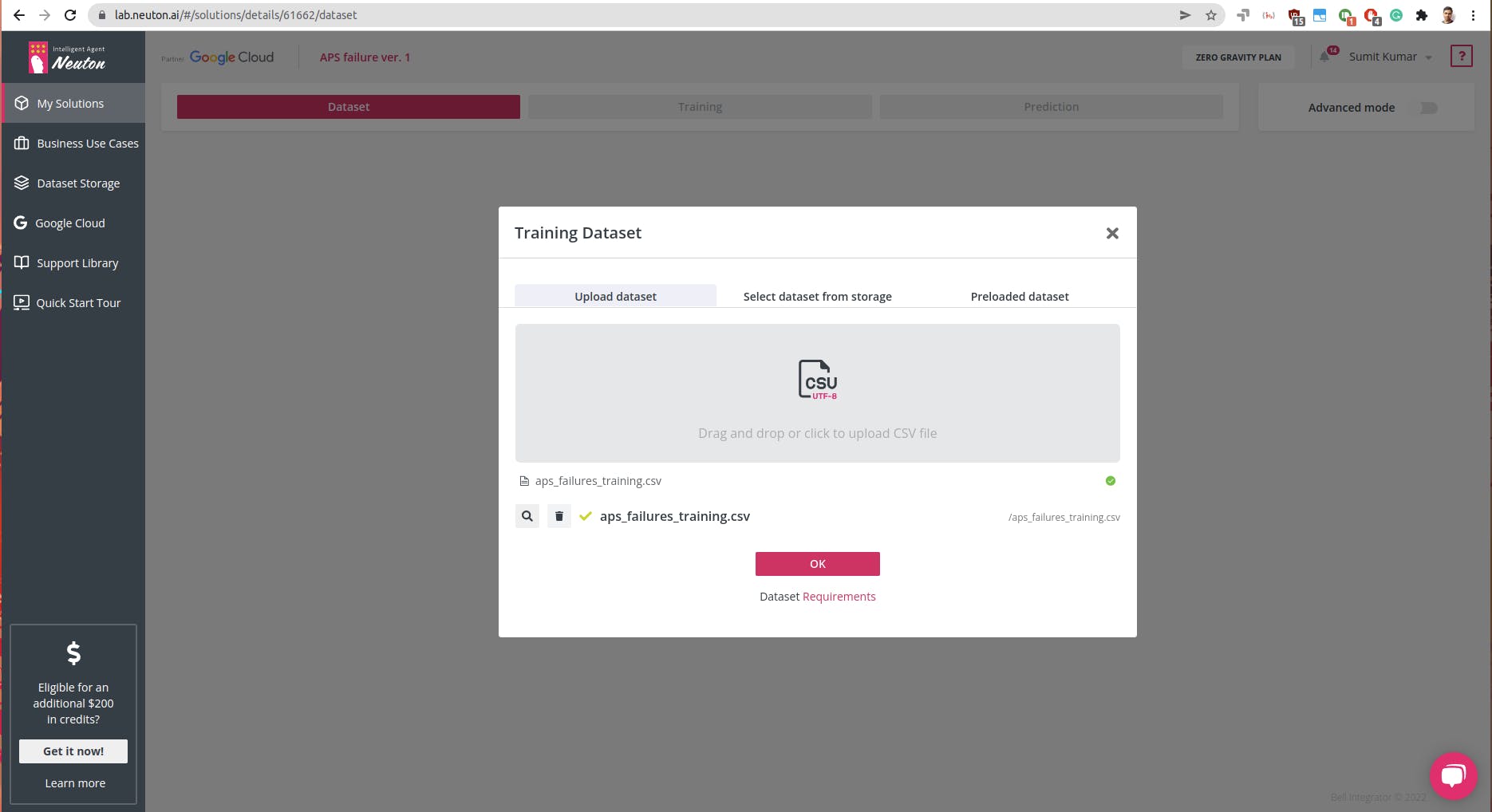
为每个预测选择目标变量或所需的输出。在这种情况下,我们将类作为输出变量:0 表示“负”,1 表示“正”
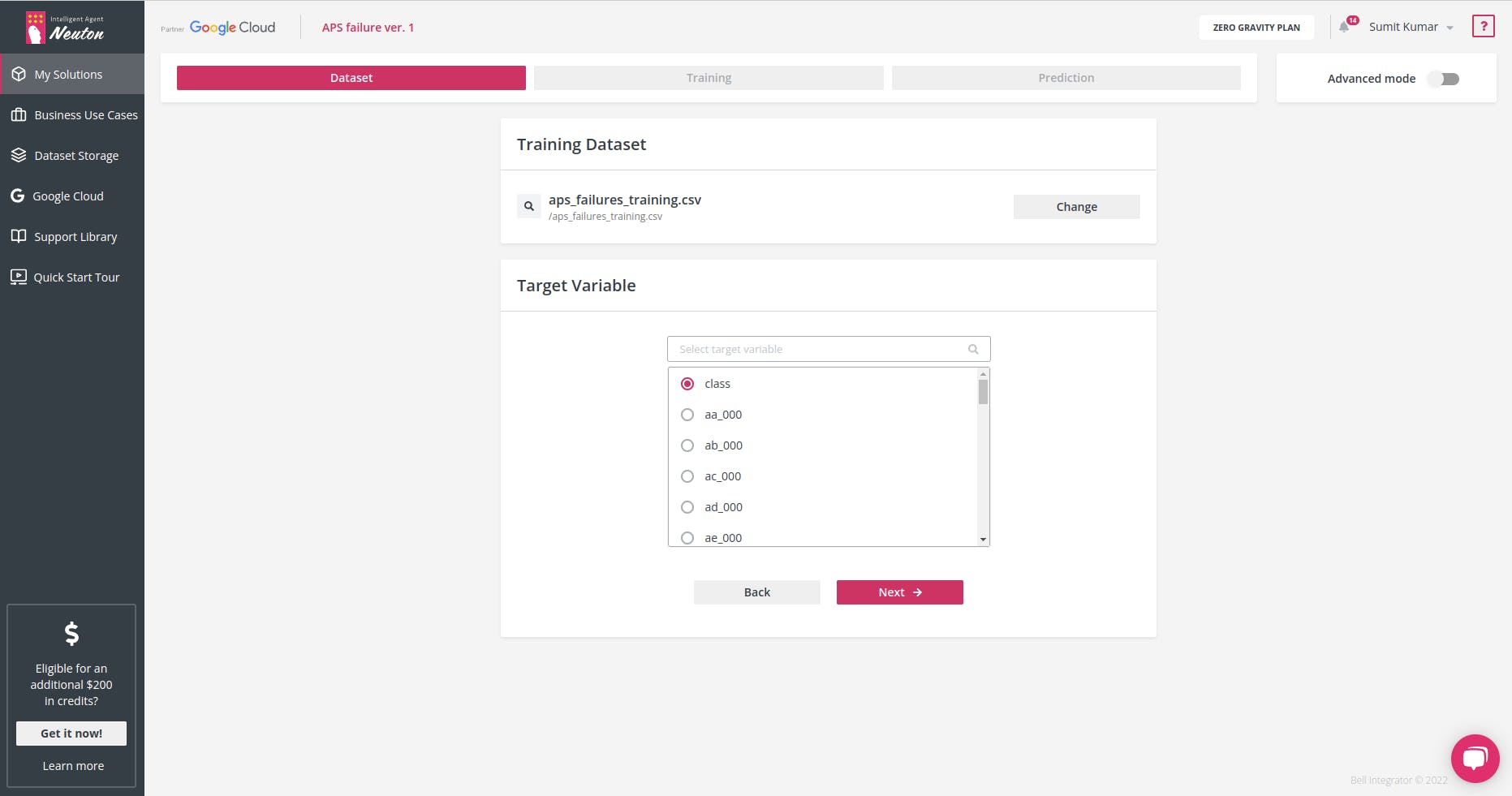
第 2 步:模型训练和参数
由于我们要将模型嵌入到微型 MCU 中,因此我们需要相应地设置参数。Raspberry Pico 可以运行 32 位操作并将 归一化类型设置为Unique Scale for Each Feature
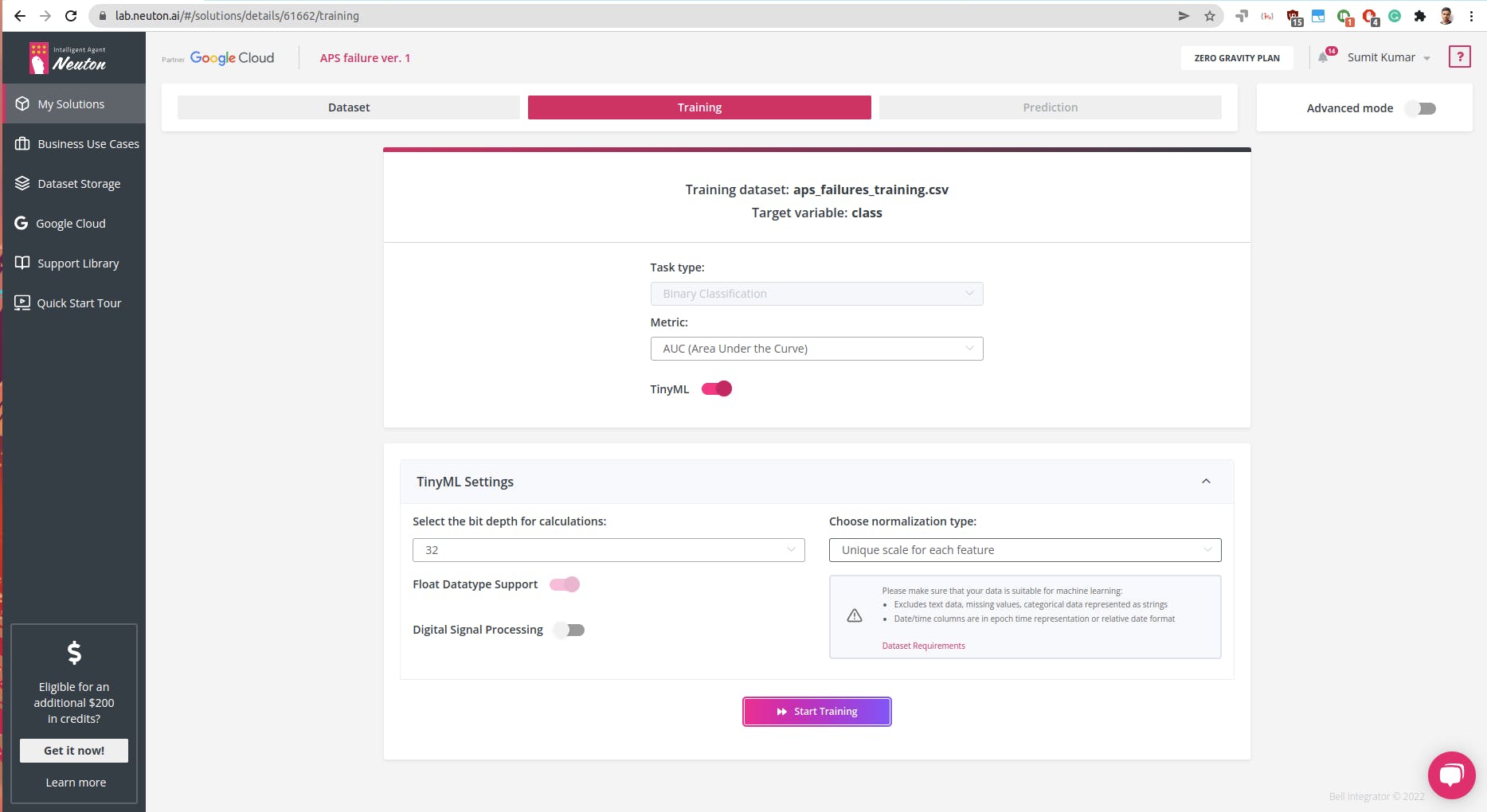
点击开始训练,由于数据集很大,训练可能需要更长的时间,对我来说,大约需要 6 个小时。同时,您可以查看数据处理完成后生成的探索性数据分析,请查看以下视频:
- 在训练期间,您可以通过观察模型状态(“一致”或“不一致”)和目标指标值来监控实时模型性能。
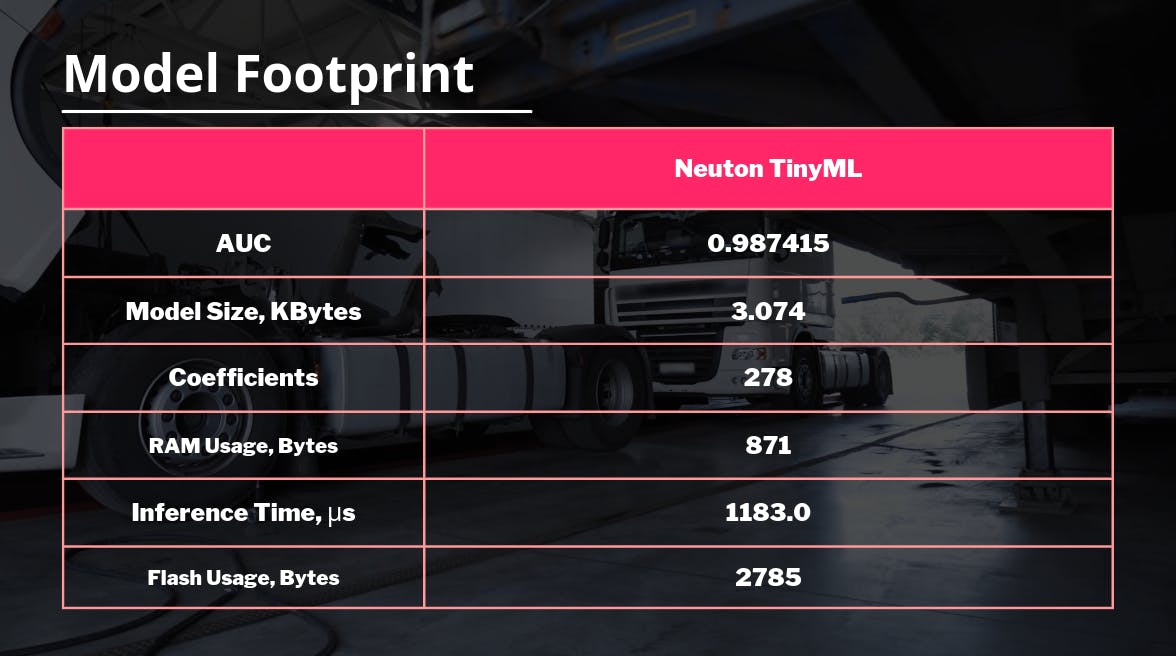
我的目标指标是:AUC 0.987415 ,训练后的模型具有以下特征:
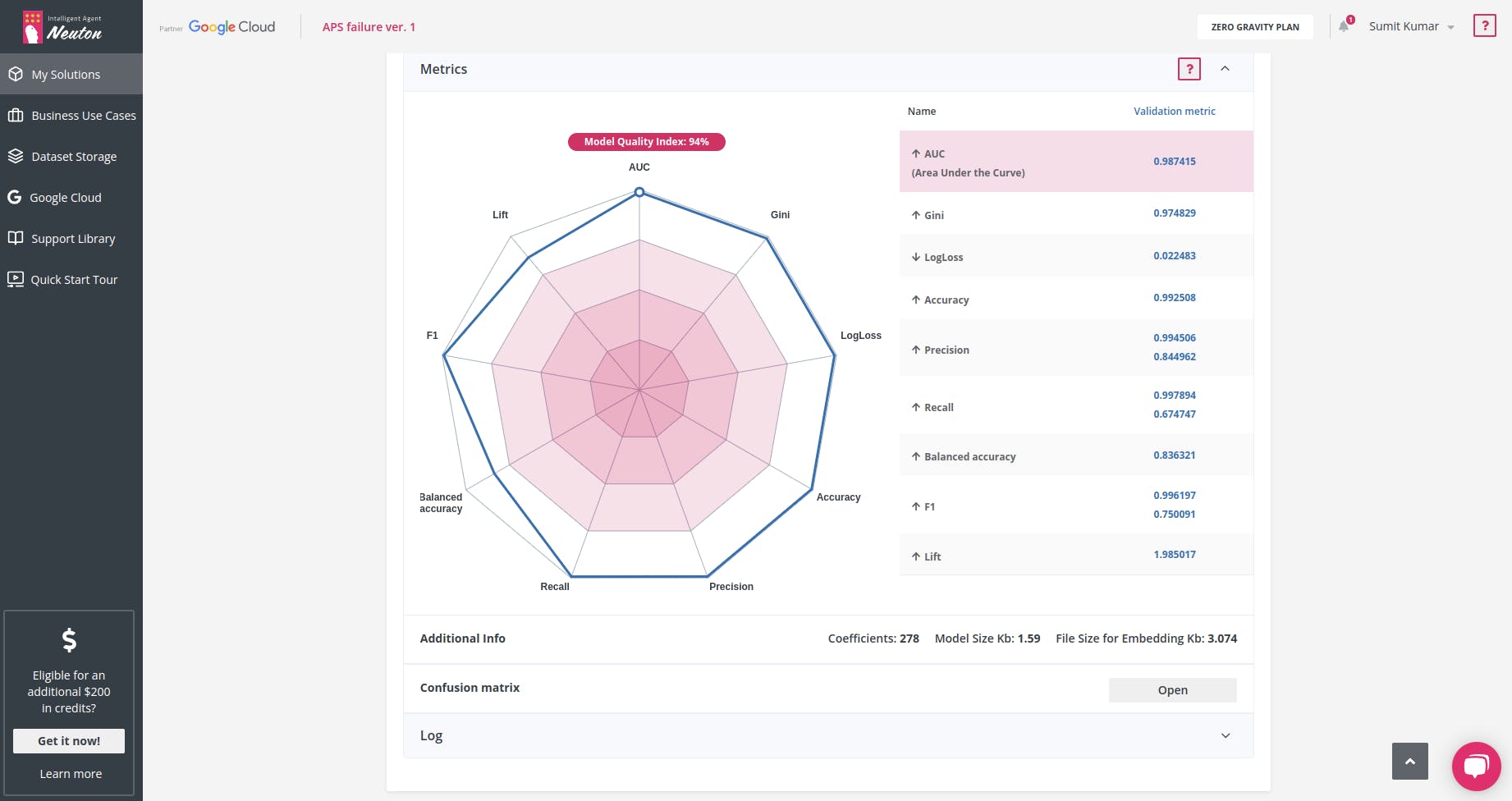
系数数 = 278,嵌入文件大小 = 3.074 Kb 。太酷了!
第 3 步:在 Raspberry Pico 上进行预测和嵌入
在 Neuton ai 平台上,单击Prediction选项卡,然后单击Model for Embedding旁边的Download按钮,这将是我们将用于我们的设备的模型库文件。
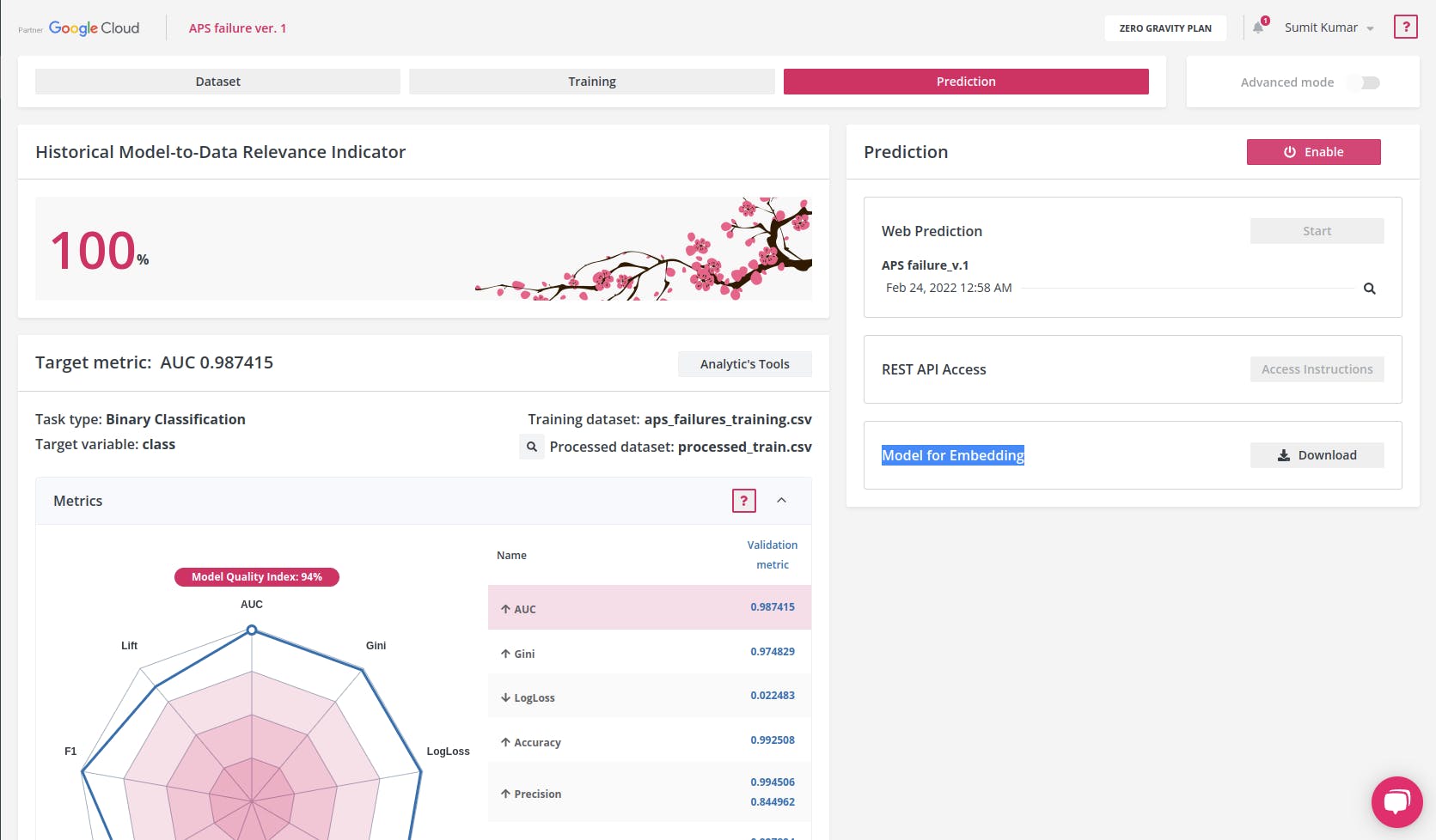
下载模型文件后,就可以添加我们的自定义函数和操作了。我正在使用 Arduino IDE 对 Raspberry Pico 进行编程
为 Raspberry Pico 设置 Arduino IDE:
我在本教程中使用了 Ubuntu,但相同的说明应该适用于其他基于 Debian 的发行版,例如 Raspberry Pi OS。
1. 打开终端,使用 wget 下载官方 Pico 设置脚本。
$ wget https://raw.githubusercontent.com/raspberrypi/pico-setup/master/pico_setup.sh
2.在同一终端修改下载的文件,使其可执行。
$ chmod +x pico_setup.sh
3.运行 pico_setup.sh开始安装过程。如果出现提示,请输入您的 sudo 密码。
$ ./pico_setup.sh
4.下载 Arduino IDE并将其安装在您的机器上。
5. 打开终端并将您的用户添加到“拨出”组。该组可以与 Arduino 等设备进行通信。使用“$USER”将自动使用您的用户名。
$ sudo usermod -a -G dialout “$USER”
6.注销或重新启动计算机以使更改生效。
7.打开 Arduino 应用程序并转到 File >> Preferences 。
8. 在附加板的管理器中添加此行并单击 OK 。
https://github.com/earlephilhower/arduino-pico/releases/download/global/package_rp2040_index.json
9.转到工具>>板>>板管理器。
10.在搜索框中输入“pico”,然后安装树莓派 Pico/RP2040 板。这将触发另一个大下载,大小约为 300MB。
注意:由于我们要对测试数据集进行分类,我们将使用 Neuton 提供的 CSV 实用程序对通过 USB 发送到 MCU 的数据进行推理。
这是我们的项目目录,
user@desktop:~/Desktop/APS_Failure_detection$ tree
.
├── application.c
├── application.h
├── APS_Failure_detection.ino
├── checksum.c
├── checksum.h
├── model
│ └── model.h
├── neuton.c
├── neuton.h
├── parser.c
├── parser.h
├── protocol.h
├── StatFunctions.c
└── StatFunctions.h
1 directory, 13 files
校验和、解析器程序文件用于使用 CSV 串行实用工具生成握手并将列数据发送到 Raspberry Pico 进行推理。
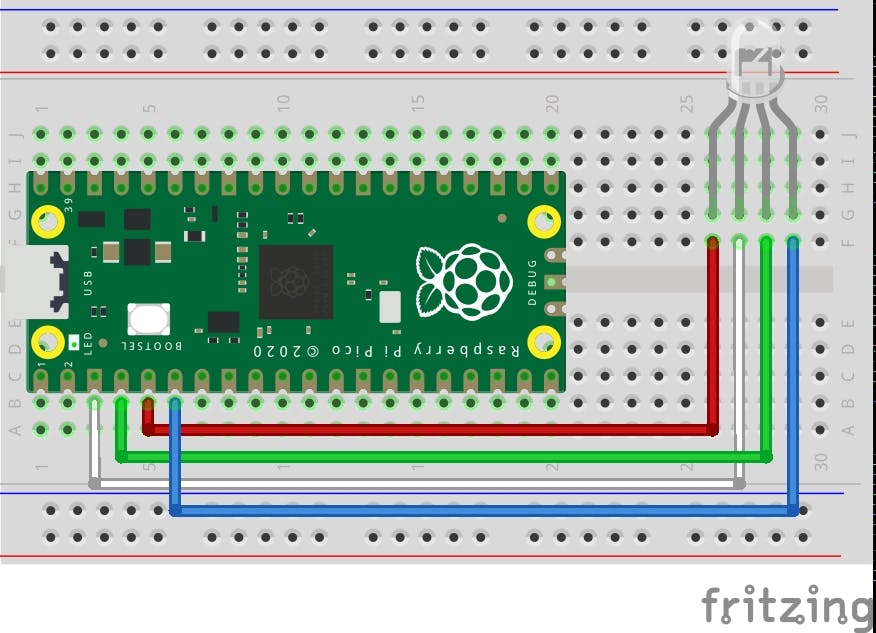
[秘密提示:如果您训练类似的二进制分类模型,只需替换model.h文件并相应修改 * .ino文件即可通过 USB 串行在 CSV 数据集上运行运行推理] 请参见下面的引脚连接
了解APS_Failure_detection.ino文件中的代码部分,我们设置了不同的回调来监控推理时使用的 CPU、时间和内存使用情况。
void setup() {
Serial.begin(230400);
while (!Serial);
pinMode(LED_RED, OUTPUT);
pinMode(LED_BLUE, OUTPUT);
pinMode(LED_GREEN, OUTPUT);
digitalWrite(LED_RED, LOW);
digitalWrite(LED_BLUE, LOW);
digitalWrite(LED_GREEN, LOW);
callbacks.send_data = send_data;
callbacks.on_dataset_sample = on_dataset_sample;
callbacks.get_cpu_freq = get_cpu_freq;
callbacks.get_time_report = get_time_report;
init_failed = app_init(&callbacks);
}
真正的魔法发生在这里callbacks.on_dataset_sample=on_dataset_sample
static float* on_dataset_sample(float* inputs)
{
if (neuton_model_set_inputs(inputs) == 0)
{
uint16_t index;
float* outputs;
uint64_t start = micros();
if (neuton_model_run_inference(&index, &outputs) == 0)
{
uint64_t stop = micros();
uint64_t inference_time = stop - start;
if (inference_time > max_time)
max_time = inference_time;
if (inference_time < min_time)
min_time = inference_time;
static uint64_t nInferences = 0;
if (nInferences++ == 0)
{
avg_time = inference_time;
}
else
{
avg_time = (avg_time * nInferences + inference_time) / (nInferences + 1);
}
// add your functions to respond to events based upon detection
switch (index)
{
case 0:
//Serial.println("0: No Failure");
digitalWrite(LED_GREEN, HIGH);
break;
case 1:
//Serial.println("1: APS Failure Detected");
digitalWrite(LED_RED, HIGH);
break;
case 2:
//Serial.println("2: Unknown");
digitalWrite(LED_BLUE, HIGH);
break;
default:
break;
}
return outputs;
}
}
return NULL;
}
一旦输入变量准备就绪,就会调用 neuton_model_run_inference(&index, &outputs)来运行推理并返回输出。
安装 CSV 数据集上传实用程序(目前仅适用于 Linux 和 macOS)
- 安装依赖,
# For Ubuntu
$ sudo apt install libuv1-dev gengetopt
# For macOS
$ brew install libuv gengetopt
- 克隆这个 repo,
$ git clone https://github.com/Neuton-tinyML/dataset-uploader.git
$ cd dataset-uploader
- 运行 make 构建二进制文件,
$ make
完成后,您可以尝试运行帮助命令,它应该类似于下图所示
user@desktop:~/dataset-uploader$ ./uploader -h
Usage: uploader [OPTION]...
Tool for upload CSV file MCU
-h, --help Print help and exit
-V, --version Print version and exit
-i, --interface=STRING interface (possible values="udp", "serial"
default=`serial')
-d, --dataset=STRING Dataset file (default=`./dataset.csv')
-l, --listen-port=INT Listen port (default=`50000')
-p, --send-port=INT Send port (default=`50005')
-s, --serial-port=STRING Serial port device (default=`/dev/ttyACM0')
-b, --baud-rate=INT Baud rate (possible values="9600", "115200",
"230400" default=`230400')
--pause=INT Pause before start (default=`0')
第 4 步:在 Raspberry Pico 上运行推理
在树莓派上上传程序,
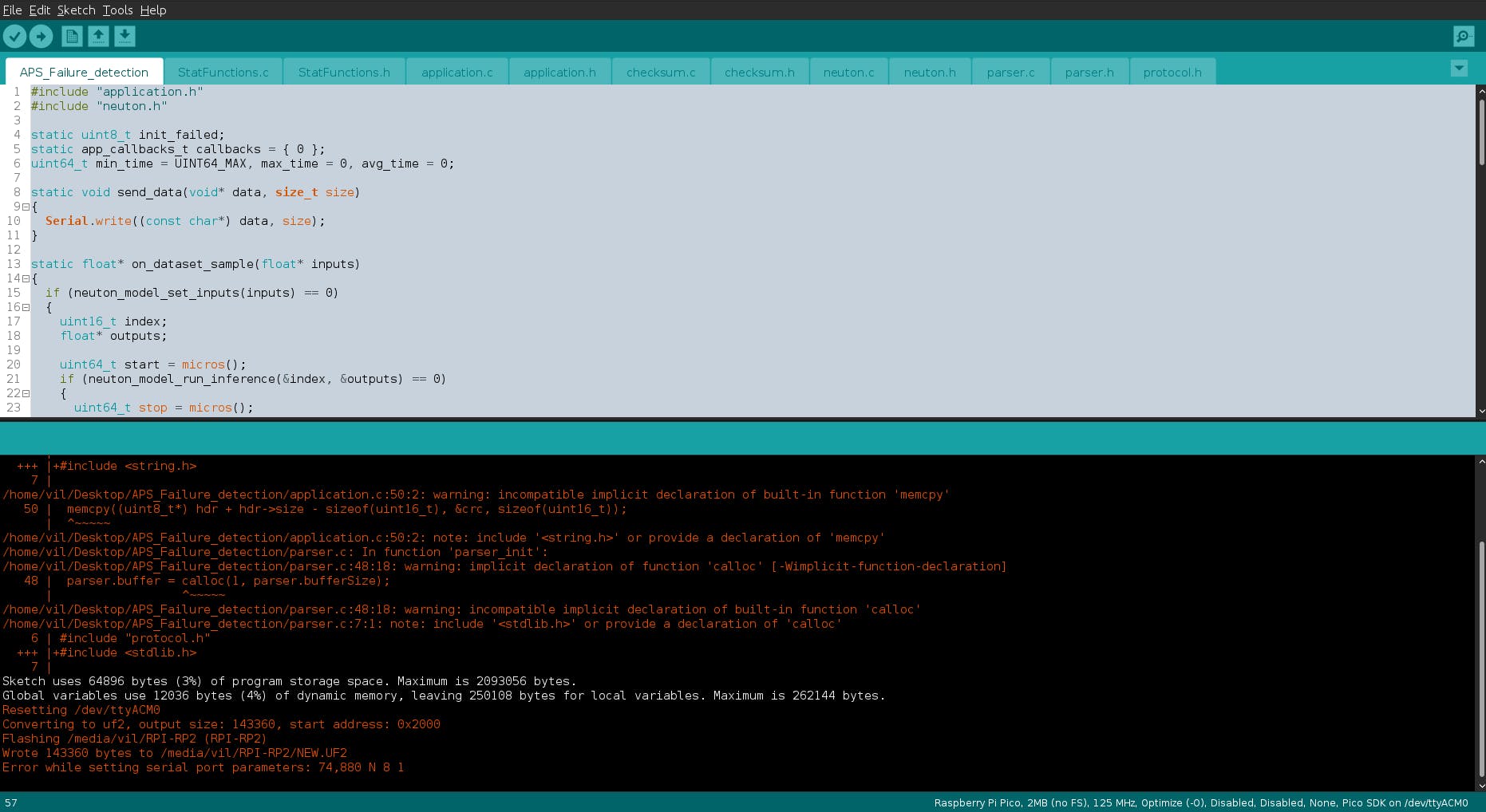
上传并运行后,打开一个新终端并运行以下命令:
$ ./uploader -s /dev/ttyACM0 -b 230400 -d /home/vil/Desktop/aps_failures_test.csv
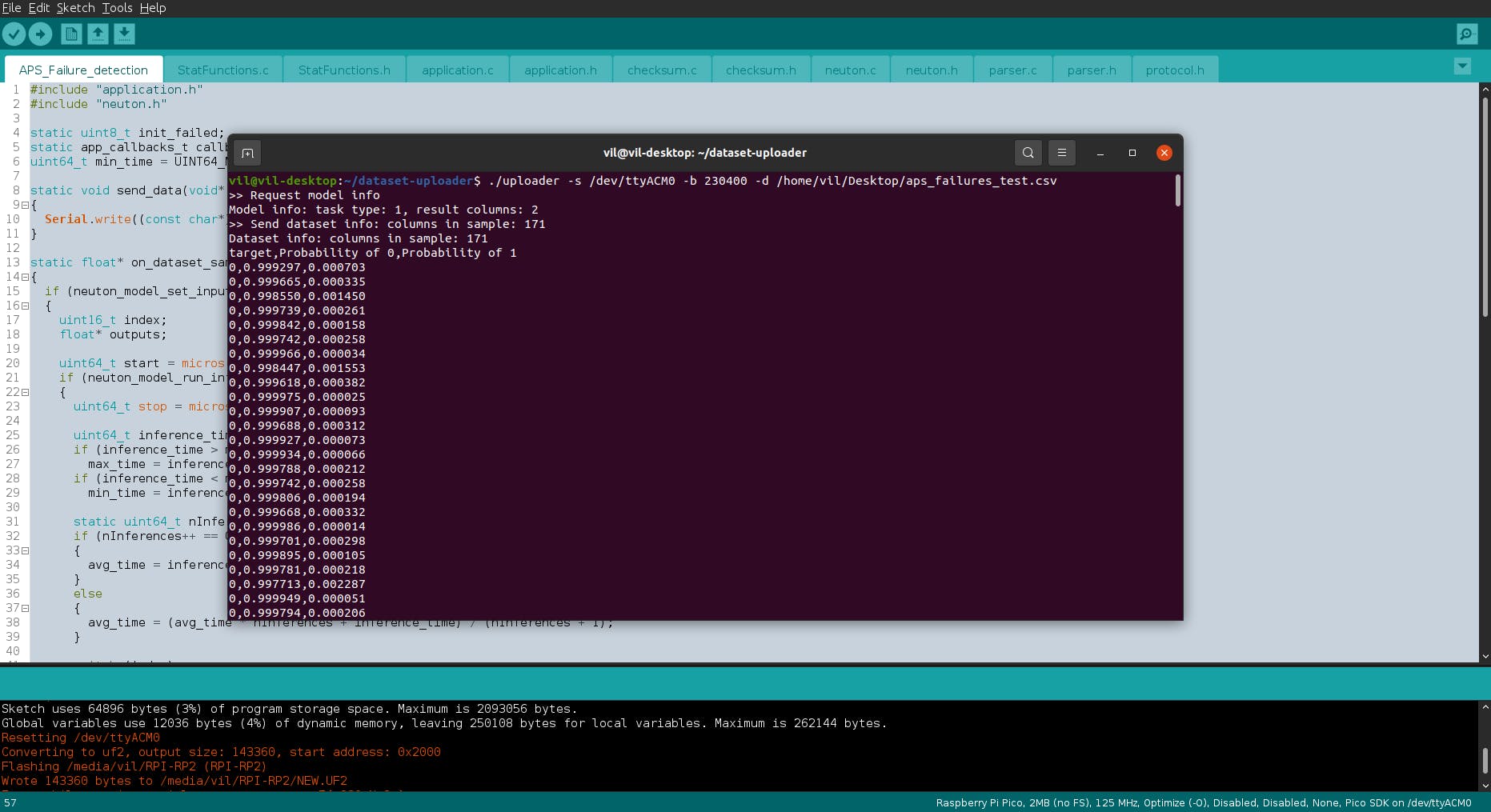
推理已开始运行,一旦完成整个 CSV 数据集,它将打印完整的摘要。
>> Request performace report
Resource report:
CPU freq: 125000000
Flash usage: 2785
RAM usage total: 821
RAM usage: 821
UART buffer: 694
Performance report:
Sample calc time, avg: 1183.0 us
Sample calc time, min: 1182.0 us
Sample calc time, max: 1346.0 us
我还在 Neuton TinyML 平台上与 Web Prediction 进行了比较,结果相似。另外,我尝试使用 TensorFlow 和 TensorFlow Lite 构建相同的模型。我用 Neuton TinyML 构建的模型在AUC方面比用TF Lite构建的模型要好14.3% ,在模型大小方面要小 9.7 倍。说到系数的数量,TensorFlow的模型有7个,060个系数,而Neuton的模型只有278个系数(小了25.4倍!)。
因此,得到的模型足迹和推理时间如下:
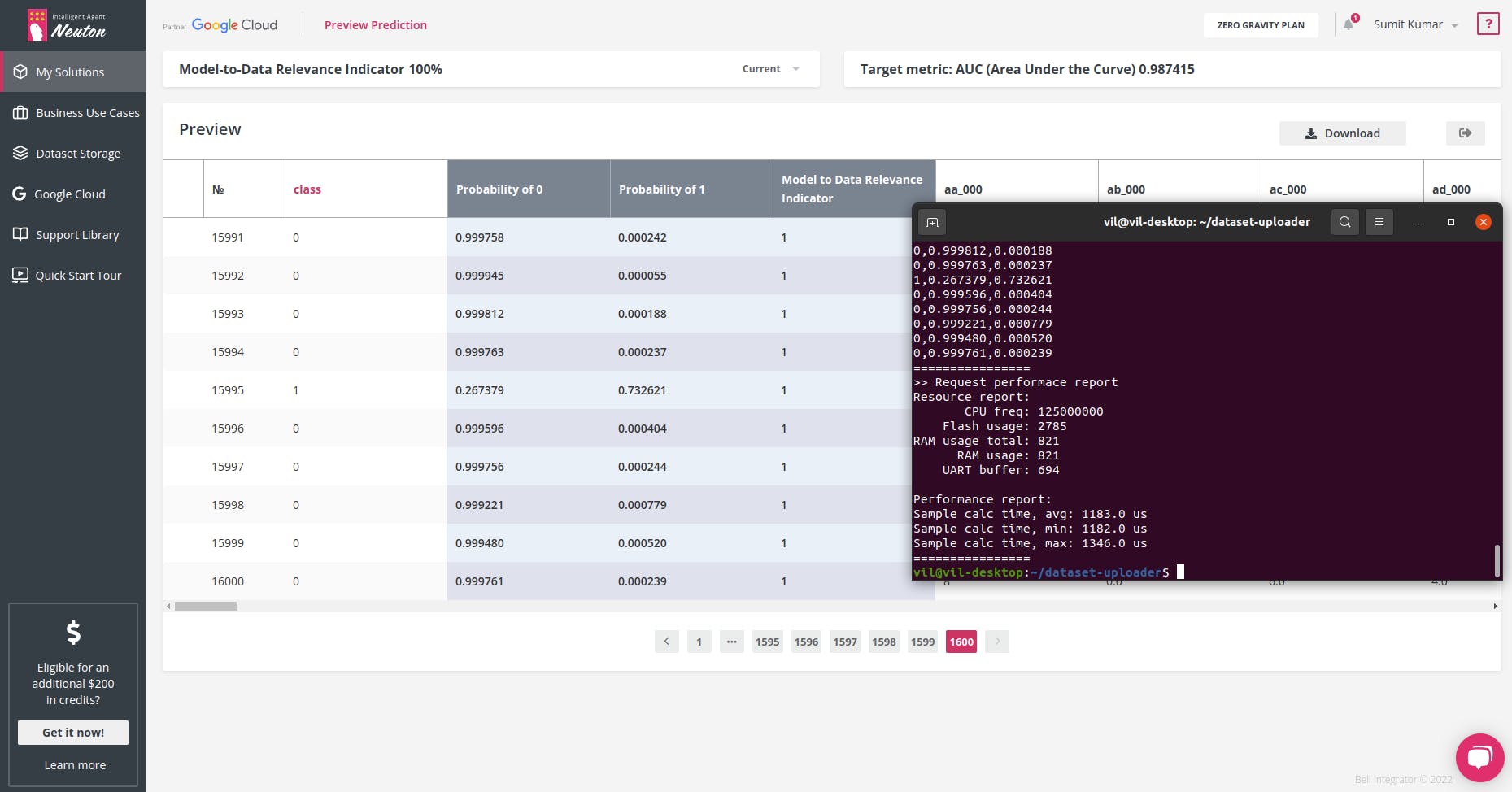
Raspberry Pico 能够执行使用云上的高性能机器处理的任务,这不是很神奇吗?
结论
本教程生动地证明了您无需成为数据科学家即可快速构建超紧凑的 ML 模型以主动解决实际挑战。而且,最重要的是,使用tinyML实现这样的解决方案,节省了大量的金钱和资源,不需要高昂的成本和努力,只需要一个免费的无代码工具和一个超级便宜的MCU!
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章





