
资料下载


MCU上的TinyML变速箱故障预测开源分享
陈燕
分享资料个
描述
是否有可能在一个简单的 4 美元 MCU 上制作一个人工智能驱动的系统来预测变速箱故障?如何自动构建不需要任何额外压缩的紧凑模型?非数据科学家能否成功实施此类项目?
我将在我的新项目中回答所有这些问题。
介绍和业务约束
在工业(例如,风力发电、汽车)中,变速箱通常在随机速度变化下运行。状态监测系统有望检测故障、断齿状态,并使用在不同速度曲线下收集的振动信号评估其严重程度。
现代汽车有数十万个细节和系统,需要预测故障、控制温度、压力等状态。因此,在汽车行业,创建和嵌入能够正常运行的 TinyML 模型至关重要在传感器上开辟了一系列技术优势,例如:
- 互联网独立
- 在数据传输上不浪费能源和金钱
- 高级隐私和安全性
在我的实验中,我想展示如何轻松创建这样的技术原型,以普及 TinyML 方法并将其令人难以置信的功能用于汽车行业。
使用的技术
- Neuton TinyML:Neuton,我选择了这个解决方案,因为它可以免费使用,并且可以自动创建微型机器学习模型,甚至可以部署在 8 位 MCU 上。根据 Neuton 开发人员的说法,您可以在一次迭代中创建一个紧凑的模型,而无需压缩。
- Raspberry Pi Pico:该芯片采用两个 ARM Cortex-M0 + 内核,133 兆赫,安装在芯片上时还与 256 KB 的 RAM 配对。该器件支持高达 16 MB 的片外闪存,具有一个 DMA 控制器,包括两个 UART 和两个 SPI,以及两个 I2C 和一个 USB 1.1 控制器。该器件接收16个PWM通道和30个GPIO针,其中4个适合模拟数据输入。并带有4 美元的净价格标签。
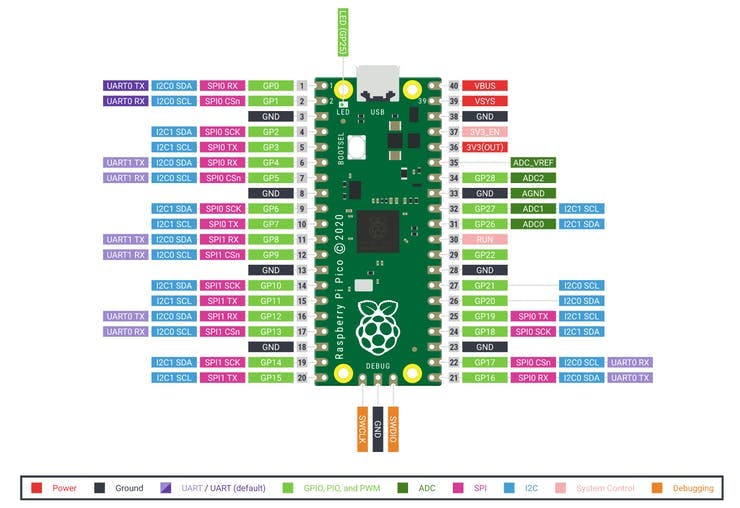
让我们构建它
本教程的目标是演示如何轻松构建紧凑的 ML 模型来解决多类分类任务,以检测齿轮箱中的断齿状况。
数据集描述
变速箱故障诊断数据集包括使用 SpectraQuest 的变速箱故障诊断模拟器记录的振动数据集。
数据集已使用 4 个振动传感器记录在四个不同的方向上,并在从“0”到“90”% 的负载变化下。包括两种不同的情况:1) 健康状况2) 断牙状况
总共有 20 个文件,10 个用于健康的变速箱,10 个用于损坏的变速箱。每个文件对应于从 0% 到 90% 的给定负载,步长为 10%。
该实验将在 4 美元的 MCU 上进行,没有云计算碳足迹 :)
第 1 步:模型训练
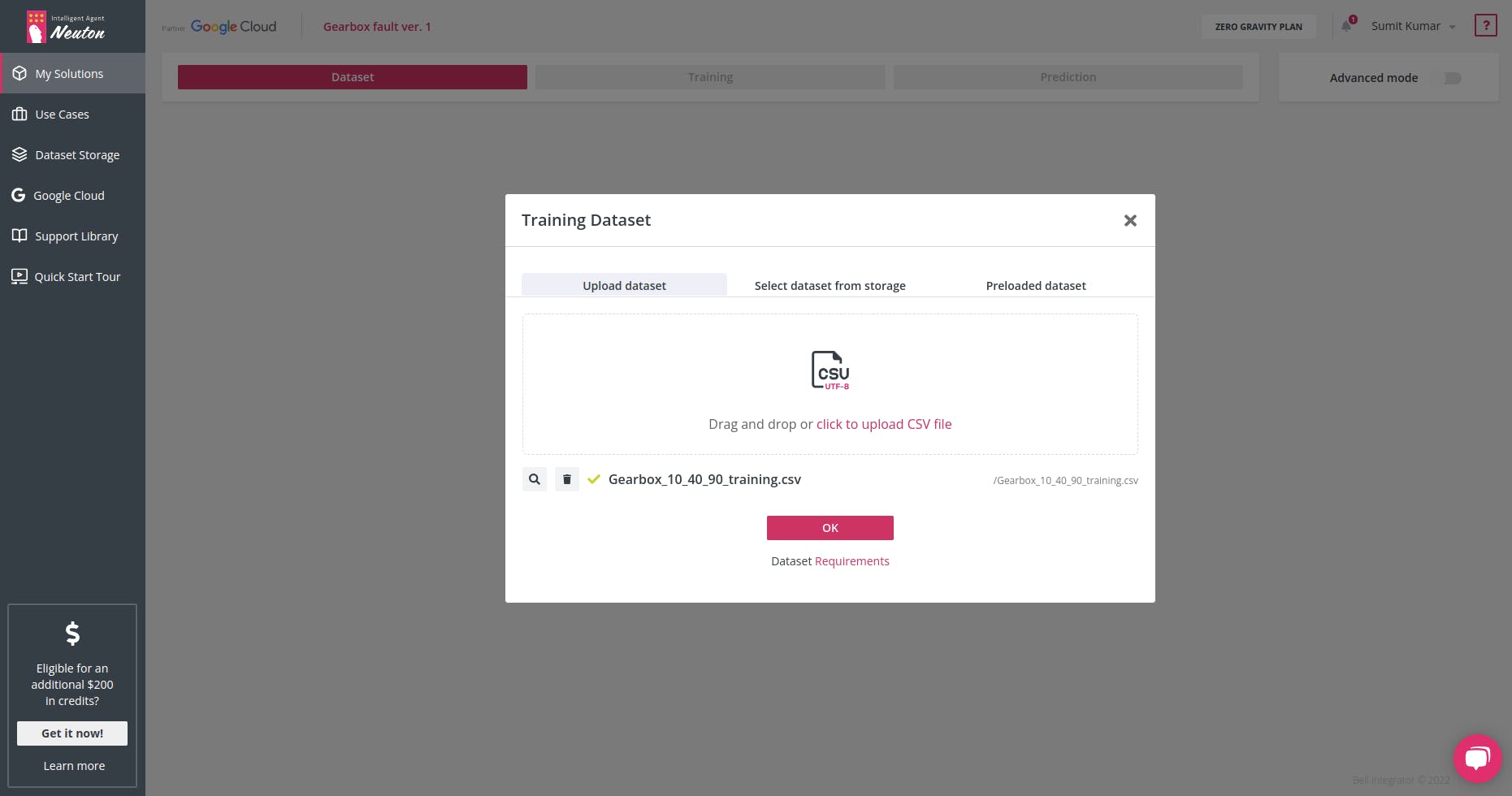
对于模型训练,我将使用免费平台 Neuton TinyML。创建解决方案后,继续上传数据集(请记住,当前支持的格式仅为 CSV)。
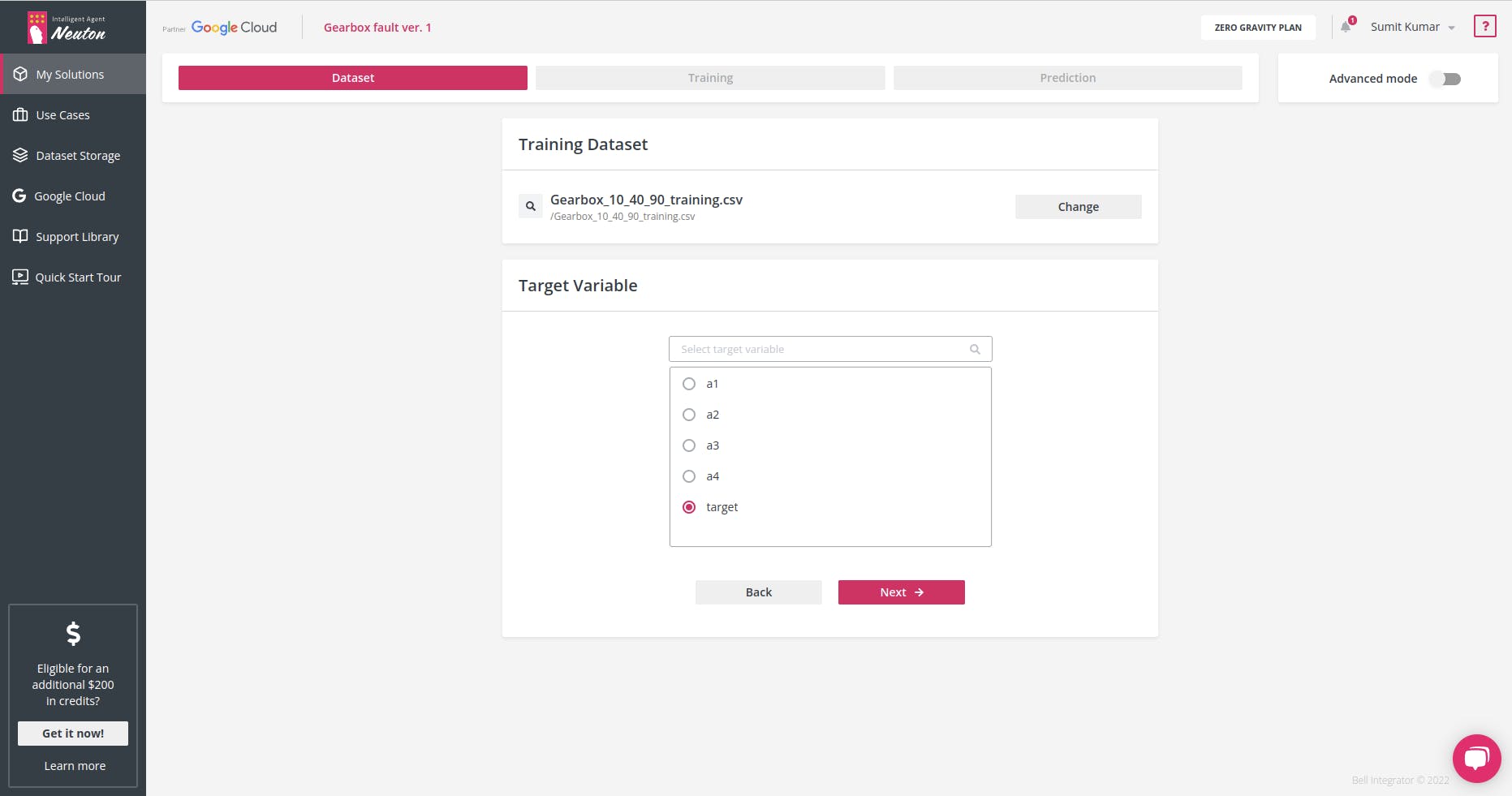
是时候为每个预测选择目标变量或所需的输出了。在这种情况下,我们将类作为输出变量:'target'
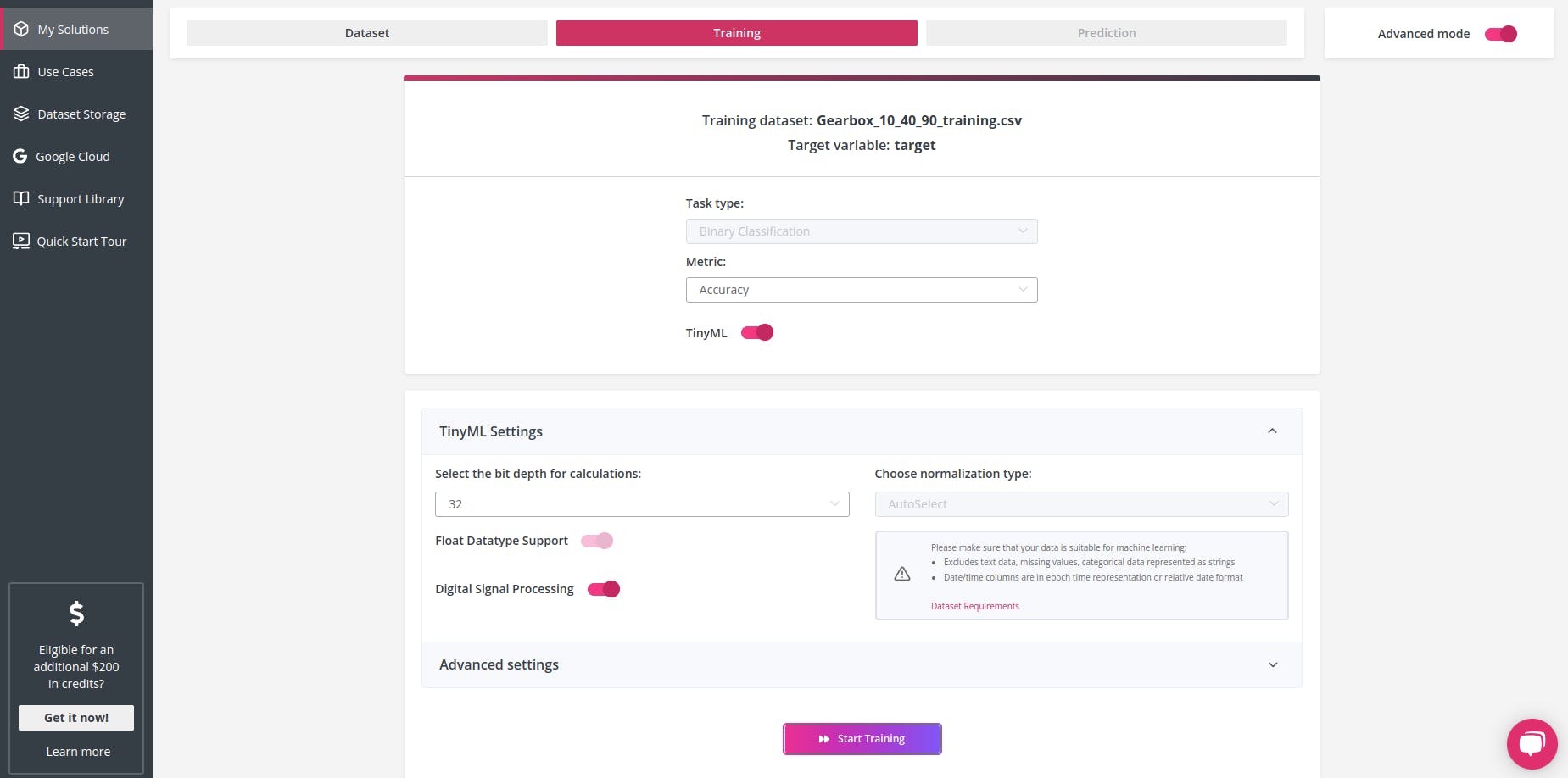
由于数据集是一个振动,我们需要在训练模型之前准备好数据。为此,我选择设置数字信号处理 (DSP)。
数字信号处理 (DSP)选项支持对来自陀螺仪、加速度计、磁力计、肌电图 (EMG) 等的数据进行自动预处理和特征提取。Neuton 将自动转换原始数据并提取其他特征,以创建用于信号分类的精确模型。
对于此模型,我们使用准确度作为指标(但您可以试验所有可用指标)。
在训练模型时,您可以查看数据处理完成后生成的探索性数据分析,查看以下视频:
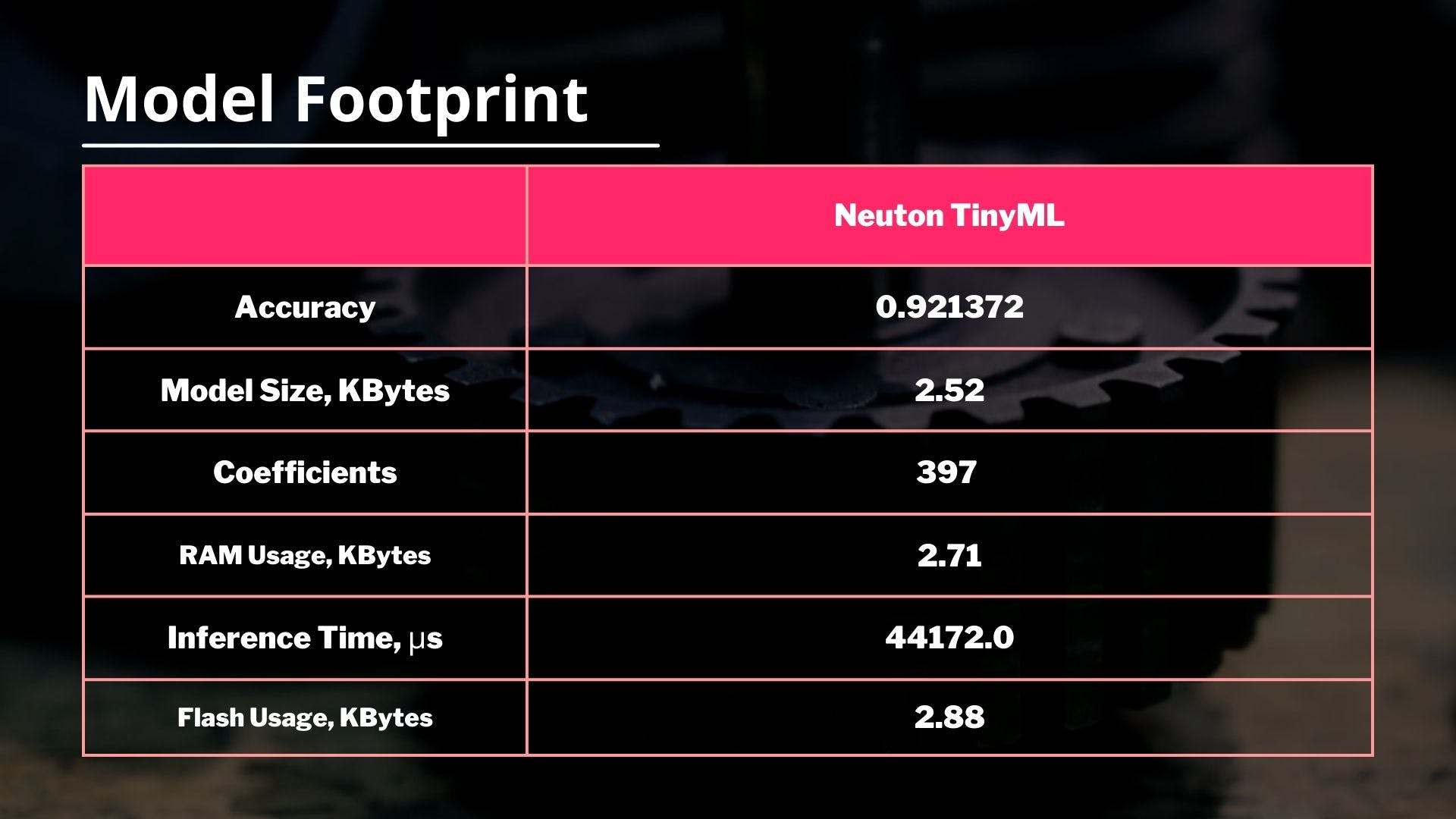
我的目标指标是:准确度 0.921372 ,训练后的模型具有以下特征:
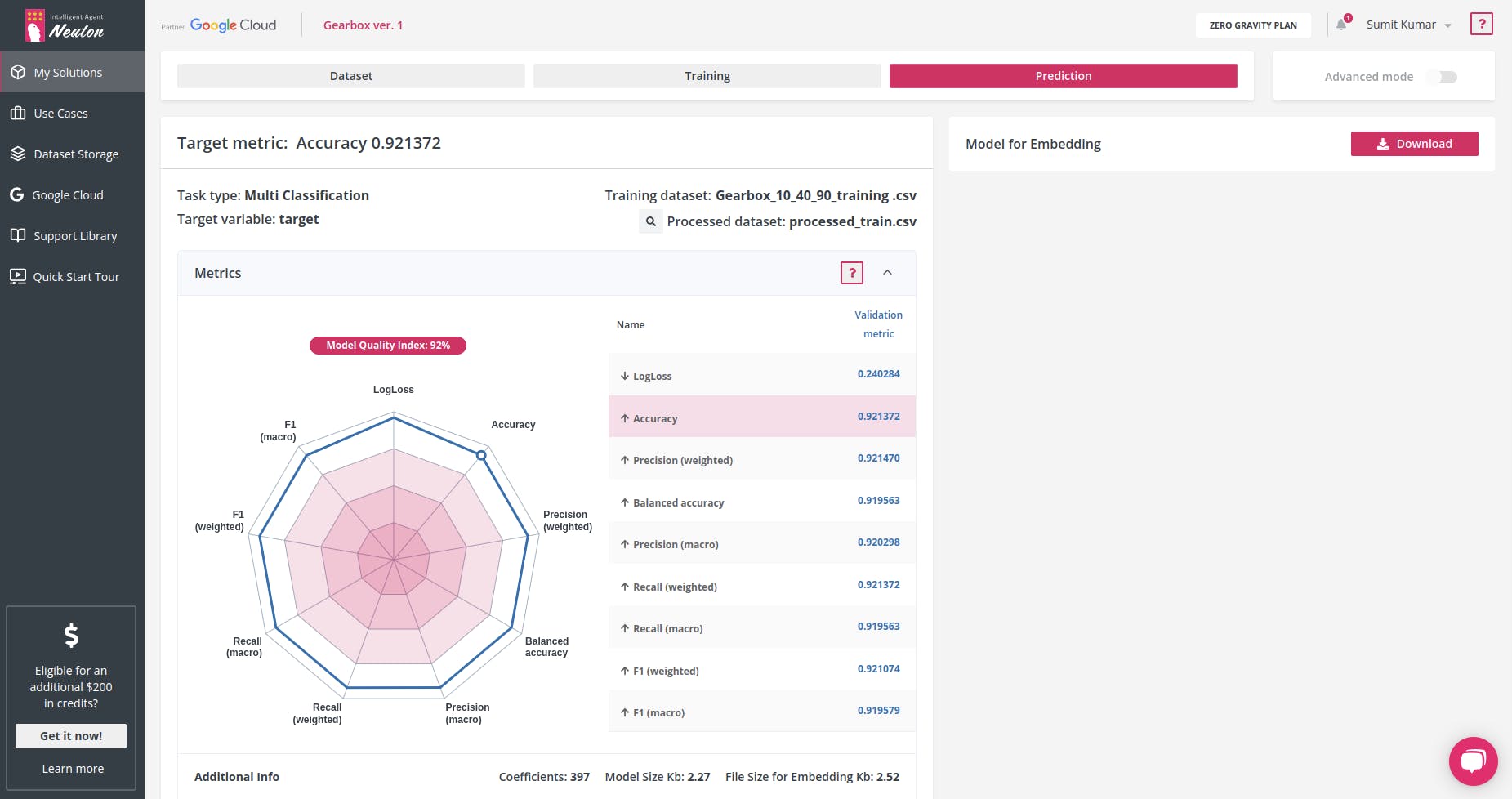
系数数 = 397,嵌入文件大小 = 2.52 Kb 。太酷了!这是一个非常小的模型!模型训练完成后,单击“预测”选项卡,然后单击“嵌入模型”旁边的“下载”按钮,下载我们将用于设备的模型库文件。
第 2 步:嵌入 Raspberry Pico
下载模型文件后,就可以添加我们的自定义函数和操作了。我正在使用 Arduino IDE 对 Raspberry Pico 进行编程。
为 Raspberry Pico 设置 Arduino IDE:
我在本教程中使用了 Ubuntu,但相同的说明应该适用于其他基于 Debian 的发行版,例如 Raspberry Pi OS。
1. 打开终端,使用 wget 下载官方 Pico 设置脚本。
2.在同一终端修改下载的文件,使其可执行。
$ chmod +x pico_setup.sh
3.运行 pico_setup.sh开始安装过程。如果出现提示,请输入您的 sudo 密码。
$ ./pico_setup.sh
4.下载 Arduino IDE并将其安装在您的机器上。
5. 打开终端并将您的用户添加到“拨出”组,然后注销或重新启动计算机以使更改生效。
$ sudo usermod -a -G dialout “$USER”
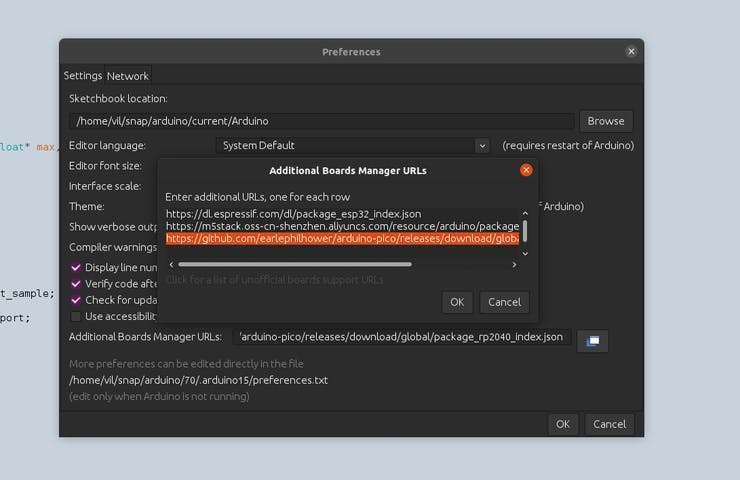
6.打开 Arduino 应用程序并转到 File >> Preferences 。在附加板的管理器中添加此行并单击 OK 。
https://github.com/earlephilhower/arduino-pico/releases/download/global/package_rp2040_index.json
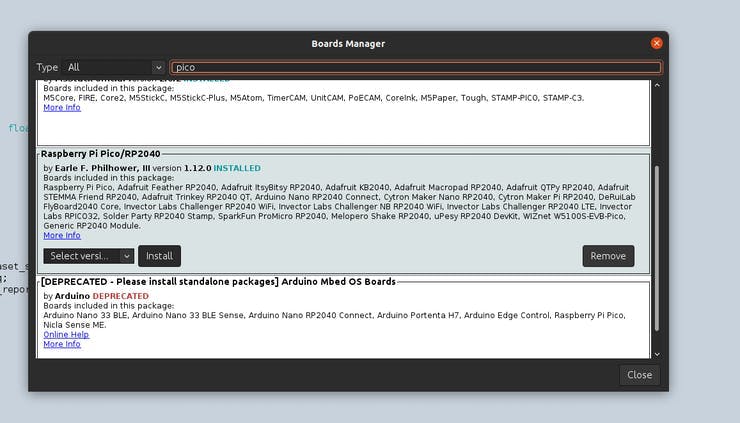
7.转到工具>>板>>板管理器。在搜索框中输入“pico”,然后安装 Raspberry Pi Pico / RP2040 板。这将触发另一个大下载,大小约为 300MB。
注意:由于我们要对测试数据集进行分类,因此我们将使用 Neuton 提供的 CSV 实用程序对通过 USB 发送到 MCU 的数据进行推理。
这是我们的项目目录,
user@desktop:~/Documents/Gearbox$ tree
.
├── application.c
├── application.h
├── checksum.c
├── checksum.h
├── Gearbox.ino
├── model
│ └── model.h
├── neuton.c
├── neuton.h
├── parser.c
├── parser.h
├── protocol.h
├── StatFunctions.c
├── StatFunctions.h
3 directories, 14 files
1 directory, 13 files
校验和、解析器程序文件用于使用 CSV 串行实用工具生成握手并将列数据发送到 Raspberry Pico 进行推理。
了解Gearbox.ino文件中的代码部分,我们设置了不同的回调来监控 CPU、时间和推理时使用的内存使用情况。
void setup() {
Serial.begin(230400);
while (!Serial);
pinMode(LED_RED, OUTPUT);
pinMode(LED_BLUE, OUTPUT);
pinMode(LED_GREEN, OUTPUT);
digitalWrite(LED_RED, LOW);
digitalWrite(LED_BLUE, LOW);
digitalWrite(LED_GREEN, LOW);
callbacks.send_data = send_data;
callbacks.on_dataset_sample = on_dataset_sample;
callbacks.get_cpu_freq = get_cpu_freq;
callbacks.get_time_report = get_time_report;
init_failed = app_init(&callbacks);
}
真正的魔法发生在这里callbacks.on_dataset_sample=on_dataset_sample
static float* on_dataset_sample(float* inputs)
{
if (neuton_model_set_inputs(inputs) == 0)
{
uint16_t index;
float* outputs;
uint64_t start = micros();
if (neuton_model_run_inference(&index, &outputs) == 0)
{
uint64_t stop = micros();
uint64_t inference_time = stop - start;
if (inference_time > max_time)
max_time = inference_time;
if (inference_time < min_time)
min_time = inference_time;
static uint64_t nInferences = 0;
if (nInferences++ == 0)
{
avg_time = inference_time;
}
else
{
avg_time = (avg_time * nInferences + inference_time) / (nInferences + 1);
}
digitalWrite(LED_RED, LOW);
digitalWrite(LED_BLUE, LOW);
digitalWrite(LED_GREEN, LOW);
switch (index)
{
/**
Green Light means Gearbox Broken (10% load), Blue Light means Gearbox Broken (40% load), and Red Light means Gearbox Broken (90% load) based upon the CSV test dataset received via Serial.
**/
case 0:
//Serial.println("0: Healthy 10% load");
break;
case 1:
//Serial.println("1: Broken 10% load");
digitalWrite(LED_GREEN, HIGH);
break;
case 2:
//Serial.println("2: Healthy 40% load");
break;
case 3:
//Serial.println("3: Broken 40% load");
digitalWrite(LED_BLUE, HIGH);
break;
case 4:
//Serial.println("4: Healthy 90% load");
break;
case 5:
//Serial.println("5: Broken 90% load");
digitalWrite(LED_RED, HIGH);
break;
default:
break;
}
return outputs;
}
}
return NULL;
}
一旦输入变量准备就绪,就会调用 neuton_model_run_inference(&index, &outputs)来运行推理并返回输出。
安装 CSV 数据集上传实用程序(目前仅适用于 Linux 和 macOS)
- 安装依赖,
# For Ubuntu
$ sudo apt install libuv1-dev gengetopt
# For macOS
$ brew install libuv gengetopt
- 克隆这个 repo,
$ git clone https://github.com/Neuton-tinyML/dataset-uploader.git
$ cd dataset-uploader
- 运行 make 构建二进制文件,
$ make
完成后,您可以尝试运行帮助命令,它应该类似于下图所示
user@desktop:~/dataset-uploader$ ./uploader -h
Usage: uploader [OPTION]...
Tool for upload CSV file MCU
-h, --help Print help and exit
-V, --version Print version and exit
-i, --interface=STRING interface (possible values="udp", "serial"
default=`serial')
-d, --dataset=STRING Dataset file (default=`./dataset.csv')
-l, --listen-port=INT Listen port (default=`50000')
-p, --send-port=INT Send port (default=`50005')
-s, --serial-port=STRING Serial port device (default=`/dev/ttyACM0')
-b, --baud-rate=INT Baud rate (possible values="9600", "115200",
"230400" default=`230400')
--pause=INT Pause before start (default=`0')
第 3 步:在 Raspberry Pico 上运行推理
在树莓派上上传程序,
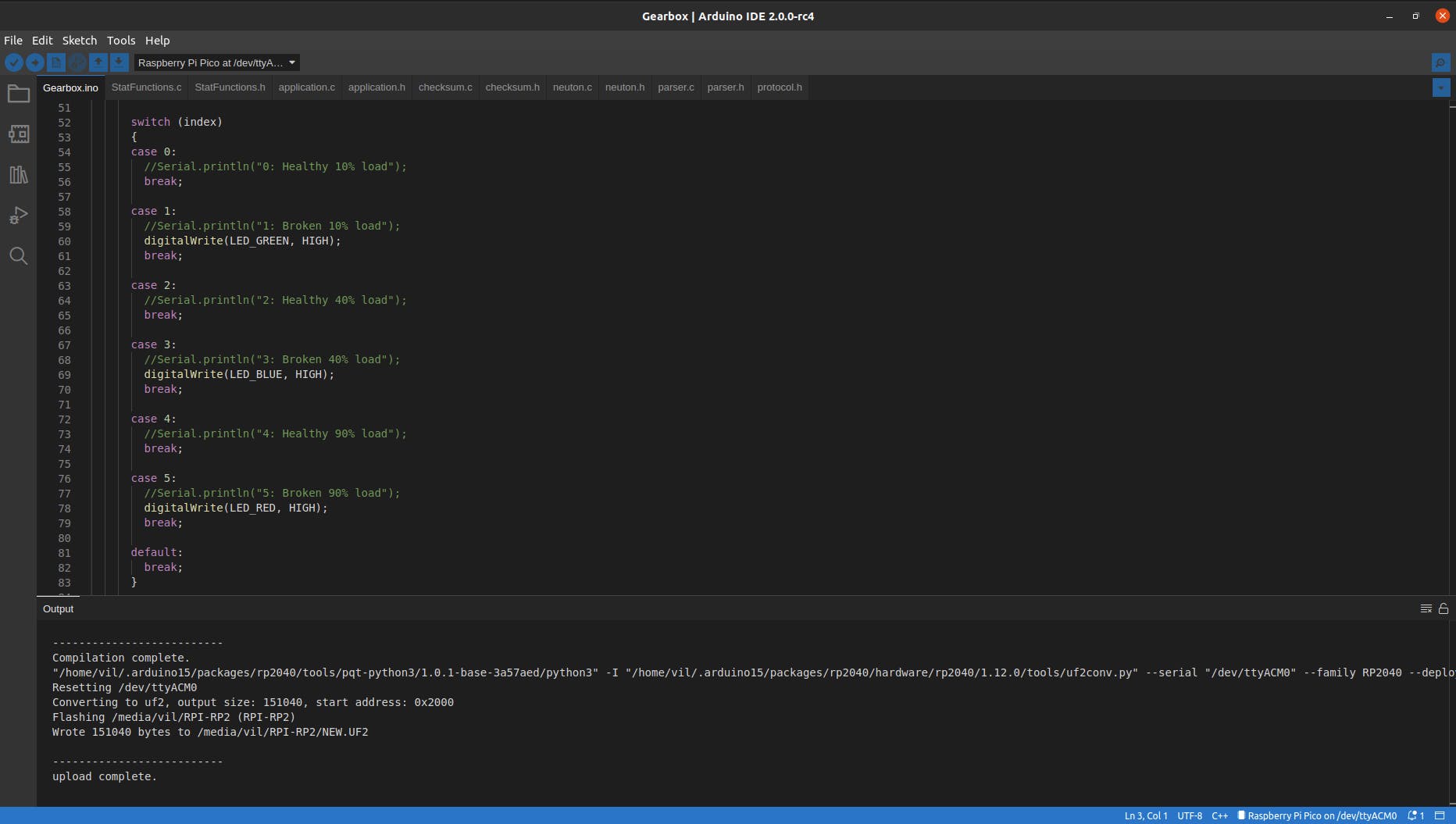
上传并运行后,打开一个新终端并运行以下命令:
$ ./uploader -s /dev/ttyACM0 -b 230400 -d /home/vil/Desktop/Gearbox_10_40_90_test.csv
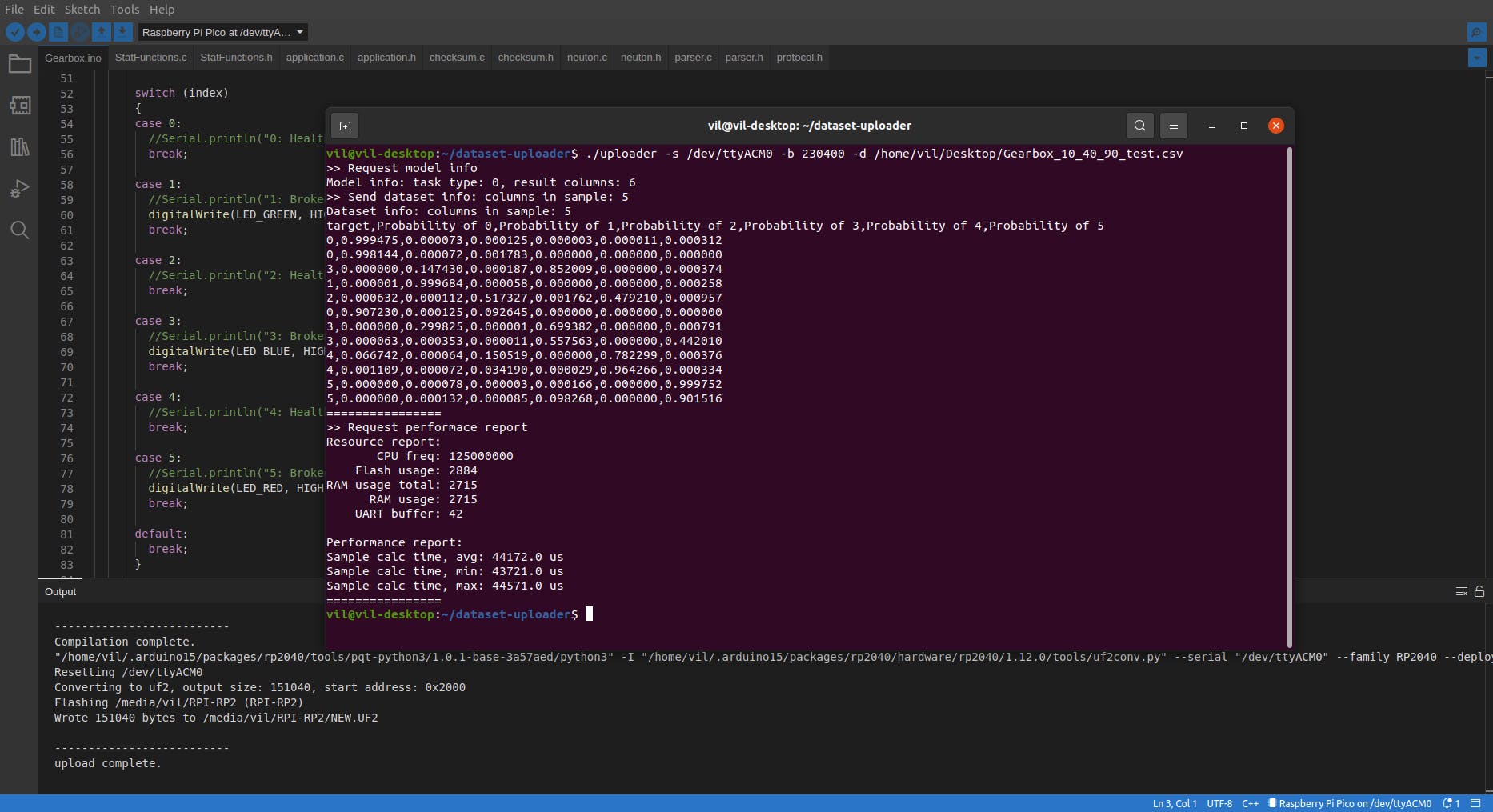
推理已开始运行,一旦完成整个 CSV 数据集,它将打印完整的摘要。
>> Request performace report
Resource report:
CPU freq: 125000000
Flash usage: 2884
RAM usage total: 2715
RAM usage: 2715
UART buffer: 42
Performance report:
Sample calc time, avg: 44172.0 us
Sample calc time, min: 43721.0 us
Sample calc time, max: 44571.0 us
我也尝试使用 TensorFlow 和 TensorFlow Lite 构建相同的模型。我使用 Neuton TinyML 构建的模型在准确性方面比使用TF Lite构建的模型要好4.3 % ,而在模型大小方面要小 15.3 倍。说到系数个数,TensorFlow的模型有9个,330个系数,而Neuton的模型只有397个系数(比TF小23.5倍!)。
生成的模型足迹和推理时间如下:
结论
本教程生动地展示了 TinyML 技术可以为汽车行业带来的巨大影响。您可以拥有几乎为零的数据科学知识,但仍然可以快速构建超紧凑的 ML 模型以有效解决实际挑战。最棒的是,这一切都可以通过使用完全免费的解决方案和超级便宜的 MCU 来实现!
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章





