
资料下载


使用Xilinx KV260对智能家居设备进行手势控制
向日葵的花季
分享资料个
描述
介绍
今天的家庭拥有越来越多的智能设备,从电视到灯,再到百叶窗等等。如果我们要处理我们已经生成的这些数据,并用它来控制物联网设备会怎样?
幸运的是,借助强大的新型边缘计算设备,例如 Xilinx 的 Kria KV260,此类应用变得越来越可行。
感谢 Xilinx 在 Xilinx 自适应计算挑战赛中提供 KV260 入门套件。
大纲
在本教程中,我们将了解如何使用 Vitis-AI 1.4 工具量化和编译预训练的 PyTorch 模型以在 Xilinx Kria KV260 SOM 上运行。然后我们将看看如何使用 Ubuntu 设置我们的 KV260,并安装 PYNQ DPU Overlay。这将允许我们使用 Python 代码在 KV260 上运行我们编译的模型。
最后,我将使用该模型检测来自 USB 网络摄像头的一些手势,然后根据模型的输出,通过我的本地 WiFi 网络向我的 FireTV 棒发送一些命令,以允许我使用手势导航菜单.
此项目的所有代码以及其他提示、技巧和故障排除都可以在此项目的GitHub 页面上找到。
本教程假设您熟悉以下概念:
- Python、PyTorch、虚拟环境/Conda
- 基本机器学习概念和术语
- 适用于 Linux 2 (WSL2) 的 Ubuntu / Linux / Windows 子系统
- SSH(X11 转发,可选)
- 码头工人(最小)
量化和编译我们的预训练模型
对于本教程,我们将假设我们已经有一个预训练的 PyTorch 模型,其权重保存到 .pt /.pth 文件中。
注意:我们将使用运行旧版本 PyTorch 的 Vitis-AI 1.4。您需要确保您的模型与 torch==1.4.0 兼容,如果您使用更新版本的 PyTorch 训练模型,这可能需要使用 _use_new_zipfile_serialization=False保存您的.pt文件
如果您想从头开始构建和训练模型,这里有大量教程,以及免费的计算资源,例如 Google Colab,允许免费(有限)使用 GPU 进行训练和实验。
注意:本教程侧重于将 PyTorch 模型转换为 xmodel,但我们在此处安装的 docker 工具也具有将 TensorFlow 和 Caffe 模型转换为 xmodel 的功能。请参阅赛灵思文档。一旦模型被量化并编译为 KV260 的 xmodel,本教程后面的部分就可以按原样使用,不管我们的浮点模型最初是用什么格式构建的。
我将使用一个自定义模型,该模型是我在电视前的数据集上训练的,执行我想使用的不同手势。
该模型能够预测六种不同的手势:上、下、左、右、手掌和拳头。我们将使用这些手势在我的电视上导航菜单。
该模型处理形状为 [1, 63] 的输入向量,该向量对应于 21 个手部关键点的 x、y、z 坐标的扁平数组,我们在预处理步骤中使用MediaPipe提取该数组(稍后会详细介绍)。模型输出一个 [1, 6] 向量,我们可以取它的 softmax 来确定每个类的概率,取最大条目作为我们的预测输出。
GitHub 页面上提供了预训练模型(.pt和 KV260 编译版本)供您试用。请记住,您的里程可能会因其有效性而有所不同,因为它专门针对我的硬件设置和环境进行了培训。
1. 安装Xilinx Vitis-AI 工具
对于这一步,我们将从赛灵思下载一个 docker 镜像,并在其中运行几个命令。您需要一台装有 Linux 或能够运行 Linux VM 的计算机。在此示例中,我将使用带有 WSL2 Ubuntu 20.04 的 Windows 10。
1.安装Docker
- 在 Windows 上,确保接受 Docker 使用 WSL2 运行的权限
2. 打开 Linux 终端并克隆https://github.com/Xilinx/Vitis-AI存储库。
3. 拉取正确版本的 Vitis-AI docker 镜像。对于这个项目,我们需要 Vitis-AI 1.4。请注意,Docker 映像有GPU 版本和CPU 版本。如果您的系统中没有 cuda GPU,则必须使用 CPU 版本。
# pick the correct version
docker pull xilinx/vitis-ai-cpu:1.4.1.978 # CPU version
docker pull xilinx/vitis-ai:1.4.1.978 # GPU version
4. 导航到我们之前克隆的 repo,并docker_run.sh使用您要运行的 docker 的标签调用脚本。前任:
peter@PeterDesktop:/mnt/d/Vitis-AI$ ./docker_run.sh xilinx/vitis-ai-cpu:1.4.1.978
-
注意:如果 bash 脚本出错,您可能需要更改行尾
docker_run.sh以兼容 Unix(在 notepad++ 中打开并将左下角的选项更改为 LF 并保存)
有关更多详细信息,请参阅Xilinx 安装文档。
接受提示,你应该会看到一个漂亮的小 Vitis-AI 文字艺术。
==========================================
__ ___ _ _ _____
\ \ / (_) | (_) /\ |_ _|
\ \ / / _| |_ _ ___ ______ / \ | |
\ \/ / | | __| / __|______/ /\ \ | |
\ / | | |_| \__ \ / ____ \ _| |_
\/ |_|\__|_|___/ /_/ \_\_____|
==========================================
Docker Image Version: 1.4.1.978
Vitis AI Git Hash: 9f3d6db
Build Date: 2021-10-08
2.量化模型
KV260 旨在内部使用整数来完成所有神经网络计算。这与 GPU 的工作方式不同,后者使用浮点值。要将我们的模型和权重转换为在 FPGA 上工作,我们需要执行一个称为量化的步骤。
我们将使用量化模型的工具组织在 conda 虚拟环境中。要激活它,我们运行:
conda activate vitis-ai-pytorch
请注意,此 conda env 运行 PyTorch==1.4.0。可能不支持来自更新版本的 PyTorch 的 Pytorch 模型中的某些操作。
量化将由使用赛灵思 pytorch_nndct.apisPython 库的 Python 脚本完成。我使用的脚本来自链接的model_data/quantize.pyGitHub Repo。它应该很容易适应model_data/quantize.py您自己的模型和数据集。
要运行这个脚本,我们需要三件事:
- 预训练网络的权重(a.pt 文件)
- 模型的 float / PyTorch 定义(继承自 torch.nn.Module 的类)
- 一个小的测试数据集(200-1000张图像,用于检查量化模型的准确性。量化过程可能会显着降低模型的性能对于某些模型。这实际上是可选的。如果我们想跳过这一步,我们可以在导出之前使用随机输入转发一次量化模型。
要访问这些文件,我们需要将它们(quantize.py文件、模型权重、模型定义和测试集)放在 docker 可见的目录中。在这种情况下,我们将使用Vitis-AI/data我们之前克隆的 repo 中的目录,该目录通过我们用来启动它的 bash 脚本设置为对 docker 可见。
然后从运行 docker 的终端,我们可以调用 python 脚本:
(vitis-ai-pytorch) Vitis-AI /workspace/data > python quantize.py
运行此脚本后,我们应该会在data 名为 的目录中看到一个新文件夹quantize_result,其中包含一个_int.xmodel文件。如果是这种情况,我们准备进入下一步。如果发生问题,请参阅故障排除部分。
补充阅读:Xilinx PyTorch 量化文档
3.编译模型
现在我们的模型已经量化为 Xilinx 中间表示 (XIR).xmodel 文件,我们需要针对我们要使用的特定硬件对其进行编译:KV260。
从 docker conda env 内部,我们将运行vai_c_xir编译器工具,它需要以下结构:
vai_c_xir -x /PATH/TO/quantized.xmodel -a /PATH/TO/arch.json -o /OUTPUTPATH -n NETNAME
-
-x :量化模型的路径,如果您按照前面的说明进行操作,则应该是该路径。
data/quantize_result/_int.xmodel -
-a:目标架构 json。对于 KV260,这将是:
/opt/vitis_ai/compiler/arch/DPUCZDX8G/KV260/arch.json -
-o:要输出模型的目录。建议:
. -
-n:您希望编译模型具有的文件名。前任:
mymodel_kv260
警告:注意它所说的输出行DPU subgraph number X。这一定是1。否则,我们在KV260上尝试运行编译好的模型时,就会出现问题。如果这不是 1,请参阅故障排除部分。
如果运行成功,您应该会看到名为 mymodel_kv260.xmodel
这是编译好的模型。将其复制到 KV260 的可访问位置。我们将在以下部分中使用 Python 脚本加载和运行它。
故障排除
如果您尝试量化、编译和运行自己的模型,那么这个量化/编译部分可能是您遇到最多问题的地方。查看GitHub 存储库中的故障排除指南以获得一些帮助。
使用 Ubuntu、PYNQ 和 Mediapipe 设置 KV260
对于这一步,我们将按照PYNQ Kria GitHub repo上提供的说明开始。简而言之,步骤是:
1. 用 Ubuntu 镜像刷写 microSD 卡。
2. SSH进入KV260
3. 克隆 PYNQ Kria 存储库。
4. 运行提供的安装脚本。
PYNQ 安装将创建一个名为 pynq-venv 的虚拟环境,其中包含所有 Vitis-AI 1.4 工具(VART、XIR、DPU Overlay),用于通过方便的 Python API 运行已编译的 xmodel。
最后,我们还要做一件事:将 Mediapipe 安装到 pynq-venv。
Mediapipe 没有安装 aarch64 pip,因此我们必须自己在 KV260 上编译轮子(说明),或者您可以使用我在该项目的 GitHub 存储库中提供的轮子。
要安装 wheel 文件,首先我们必须以 root 身份激活 pynq-venv,然后运行 pip install:
sudo -i
source /etc/profile.d/pynq_venv.sh
pip install path/to/mediapose/wheel
使用 PYNQ DPU Overlay 运行我们编译的模型
为了运行我们编译的模型,并处理输出以控制我的 FireTV 棒,我编写了一个名为app_kv260.py.
我们将在上一节中准备好的文件中运行这个脚本。pynq-venv要激活 venv 并运行 python 脚本,我们将使用以下命令。
sudo -i
source /etc/profile.d/pynq_venv.sh
xauth merge /home/ubuntu/.Xauthority # optional enable X11 forwarding (ignore warning)
python
我还包括了一个启用 X11 转发的行,这将允许我们在我们用来通过 SSH 连接到 Kria 的计算机上看到来自 OpenCV 的显示。
这些是使用我们的模型设置 DPU 和运行推理的关键线。
# Set up DPU
overlay = DpuOverlay("dpu.bit")
# Path to your compiled x model
path = '/home/ubuntu/my_model.xmodel'
# gives an assertion error if DPU subgraph number > 1
overlay.load_model(path)
dpu = overlay.runner
# Set up space in memory for input and output of DPU
inputTensors = dpu.get_input_tensors()
outputTensors = dpu.get_output_tensors()
shapeIn = tuple(inputTensors[0].dims)
shapeOut = tuple(outputTensors[0].dims)
input_data = [np.empty(shapeIn, dtype=np.float32, order="C")]
output_data = [np.empty(shapeOut, dtype=np.float32, order="C")]
# Load in input data, and run inference
x = get_input_data() # generic function to get input data
input_data[0] = x
job_id = dpu.execute_async(input_data, output_data)
dpu.wait(job_id)
y = output_data[0]
process_output(y) # generic output function to process output
这是可视化器输出的示例,表明它能够正确分类一些手势。
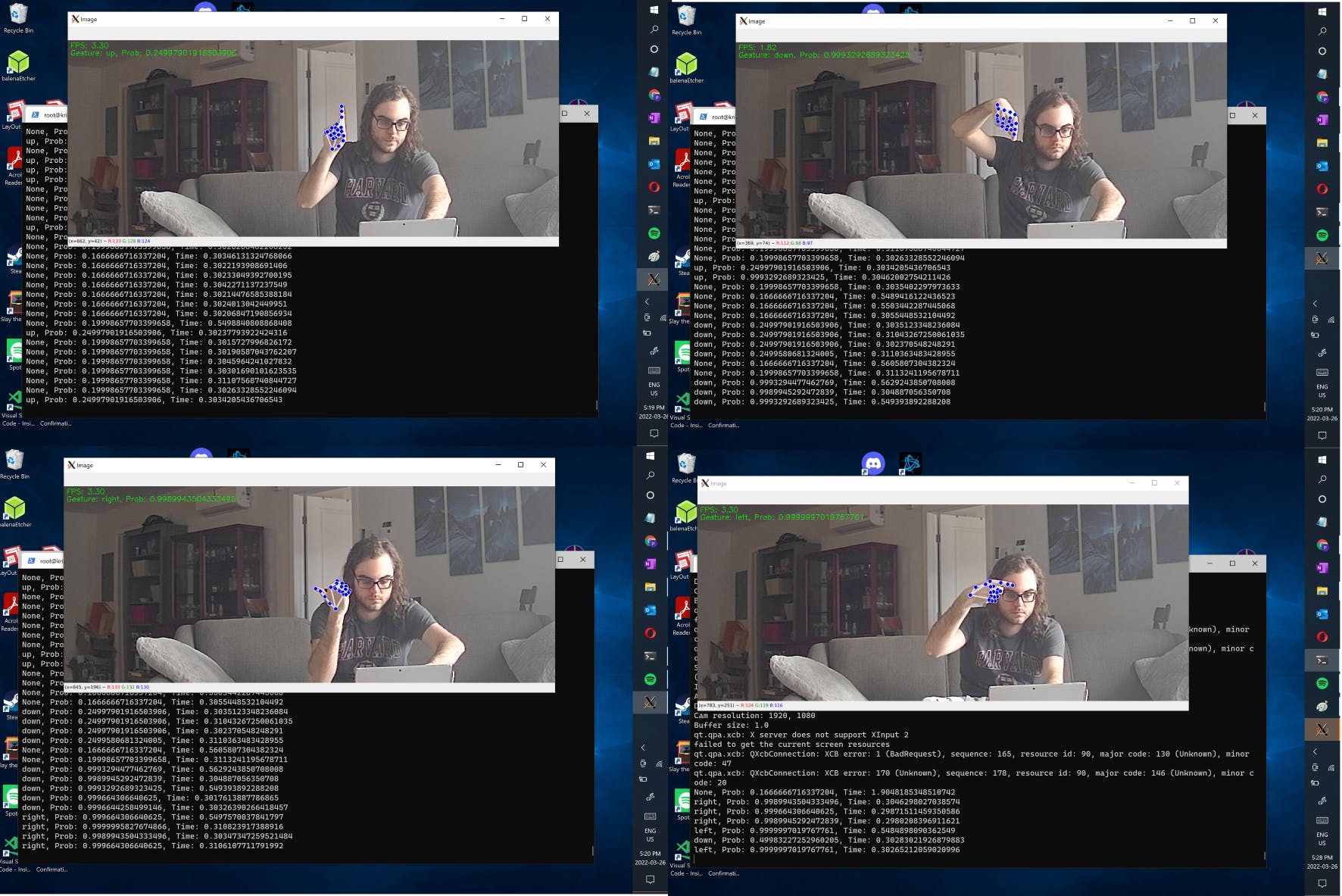
该应用程序以大约 3 FPS 的速度运行,这足以与菜单 UI 进行实时交互。这实际上是我最初的计划,但我无法找到一个可使用 Vitis-AI 软件量化的预训练模型(例如,我无法使用 OpenPose和 Vitis 玩得很好)。更具挑战性,但这将允许更自然的手势,如上下滑动、“点击”轻敲动作或转动想象中的音量旋钮,以控制不同的功能。
结论
KV260 是一款出色的硬件,用于执行计算机视觉任务的推理。开始有点棘手,但希望这个项目能给你一些指导!我期待 Xilinx 即将对 Vitis-AI 工作流程进行改进,并希望未来能有更多以爱好者为中心的硬件。
故障排除
请查看GitHub 存储库中的故障排除部分。(这个页面有点长)
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章






