
资料下载


使用Xilinx Kria KV260进行AI火灾探测
麻酱
分享资料个
描述
介绍
问题:消防队面临着人手不足、队伍有效战斗力下降等诸多挑战。最近,挑战包括城市人口增加、更复杂的人口稠密建筑物和与大流行相关的措施。因此,为了增强消防人员对火灾事件的快速响应,建议安装一个视频分析系统,以便及早发现火灾爆发。
目标:我的解决方案包括建立一个分布式计算机视觉系统,以提供对建筑物火灾的早期检测。系统的分布式和模块化特性允许轻松部署,而无需设置更多基础设施。在不增加人力规模的情况下,有助于增强船员的消防能力。这可以通过使用 Xilinx Kria KV260 实现边缘 AI 加速图像处理功能来实现。部署时,国务院当局可以利用社区现有的监控摄像头获取视频。这种模块化方法是提供快速部署的关键技术,因为摄像机已经安装到位。
开发流程总结
使用的硬件是 Xilinx Kria KV260,用于加速计算机视觉处理和以太网连接的相机套件。嵌入式软件应使用 Vitis AI。在我的 PC 上,将使用现有的火灾探测数据集训练自定义 Yolo-V4 模型。之后,使用 Xilinx YoloV4 流程对 DPU 实例的模型进行量化、修剪和编译。最后,它部署在 Kria KV260 上。

PC:设置 SD 卡映像
首先,我们需要为 Kria KV260 Vision AI Starter Kit 准备 SD 卡。
包装盒中提供了 16GB 的 SD 卡,但我建议至少使用 32GB,因为设置可能会超过 16GB 的空间。
我们将使用 Ubuntu 20.04.3 LTS 下载。从网站下载图像并将其保存在您的计算机上。

在您的 PC 上,下载 Balena Etcher 以将其写入您的 SD 卡。
或者,您可以使用命令行(警告:确保写入正确的驱动器,/dev/sdb必须是您的 SD 卡)
-
xzcat ~/Downloads/iot-kria-classic-desktop-2004-x03-20211110-98.img.xz | sudo dd of=/dev/sdb bs=32M
完成后,您的 SD 卡已准备就绪,您可以将其插入 Kria。
Kria:设置赛灵思 Ubuntu
将 USB 键盘、USB 鼠标、USB 摄像头、HDMI/DisplayPort 和以太网连接到 Kria。

连接电源以打开 Kria,您将看到 Ubuntu 登录屏幕。
默认登录凭据是:用户名:ubuntu密码:ubuntu
启动时,界面可能非常慢,所以我运行了这些命令来禁用动画调整以加快速度。
gsettings set org.gnome.desktop.interface enable-animations false
gsettings set org.gnome.shell.extensions.dash-to-dock animate-show-apps false
接下来,通过执行系统更新并调用此命令将系统更新到最新版本
sudo apt upgrade
请注意,有必要进行更新,因为早期版本的 Vitis-AI 不支持 Python,如本论坛帖子中所述。
安装用于系统管理的 xlnx-config snap 并进行配置(更多信息见 Xilinx wiki ):
sudo snap install xlnx-config --classic
xlnx-config.sysinit
现在检查设备配置是否正常工作。
sudo xlnx-config --xmutil boardid -b som
使用示例安装 Smart Vision 应用程序和 Vitis AI 库。(智能视觉应用程序包含我们将重用的 DPU 的比特流,库样本也将用于稍后测试我们训练的模型)
sudo xlnx-config --snap --install xlnx-nlp-smartvision
sudo snap install xlnx-vai-lib-samples
检查已安装的示例和应用程序
xlnx-vai-lib-samples.info
sudo xlnx-config --xmutil listapps
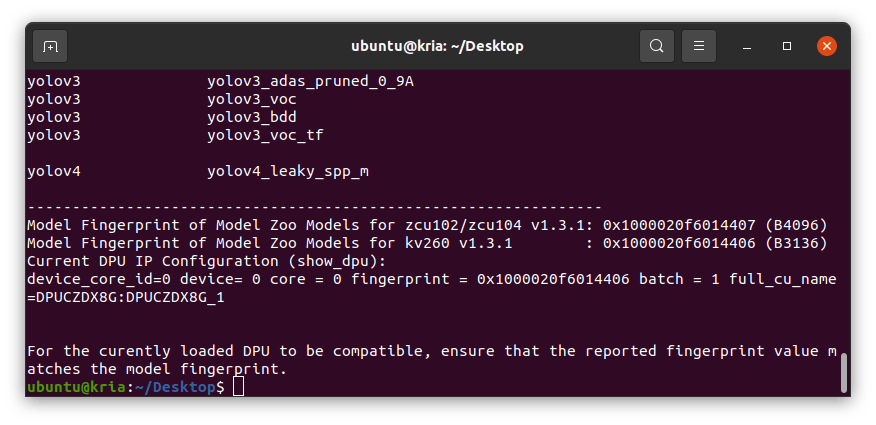
运行上述命令后,您还会注意到 Model Zoo 样本所需的 DPU 指纹。
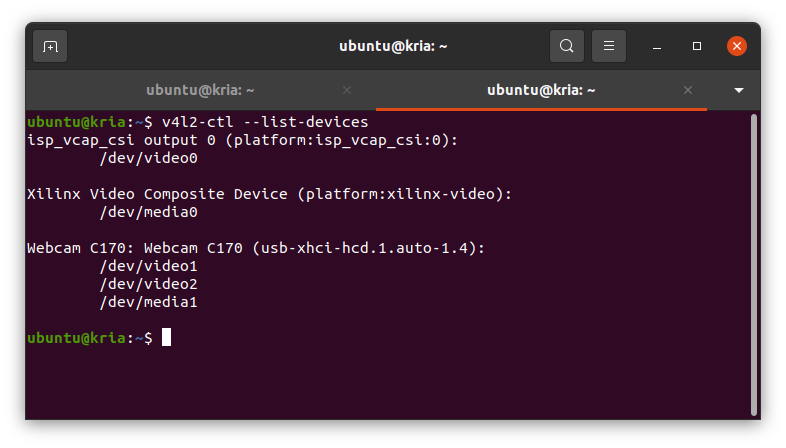
让我们运行其中一个示例。在我们这样做之前,请连接您的 USB 摄像头并确保检测到视频设备。我正在使用 Logitech C170,它在/dev/video1
v4l2-ctl --list-devices
加载智能视觉应用程序并启动它。您可以四处玩耍并了解 Kria 的功能。
sudo xlnx-config --xmutil loadapp nlp-smartvision
xlnx-nlp-smartvision.nlp-smartvision -u
在运行任何加速器应用程序之前,我们总是需要从比特流中加载 DPU。下一次,我们可以简单地调用 smartvision 应用程序,它将为我们加载比特流。或者,您可以创建自己的打包应用程序。
注意:加速器比特流位于/lib/firmware/xilinx/nlp-smartvision/.
由于我的计划是使用 YOLOv4 框架,我们来测试一个来自模型动物园的示例。有“ yolov4_leaky_spp_m”预训练模型。
sudo xlnx-config --xmutil loadapp nlp-smartvision
# the number 1 is because my webcam is on video1
xlnx-vai-lib-samples.test-video yolov4 yolov4_leaky_spp_m 1
上述命令将在您第一次运行时下载模型。模型安装到 ~/snap/xlnx-vai-lib-samples/current/models目录
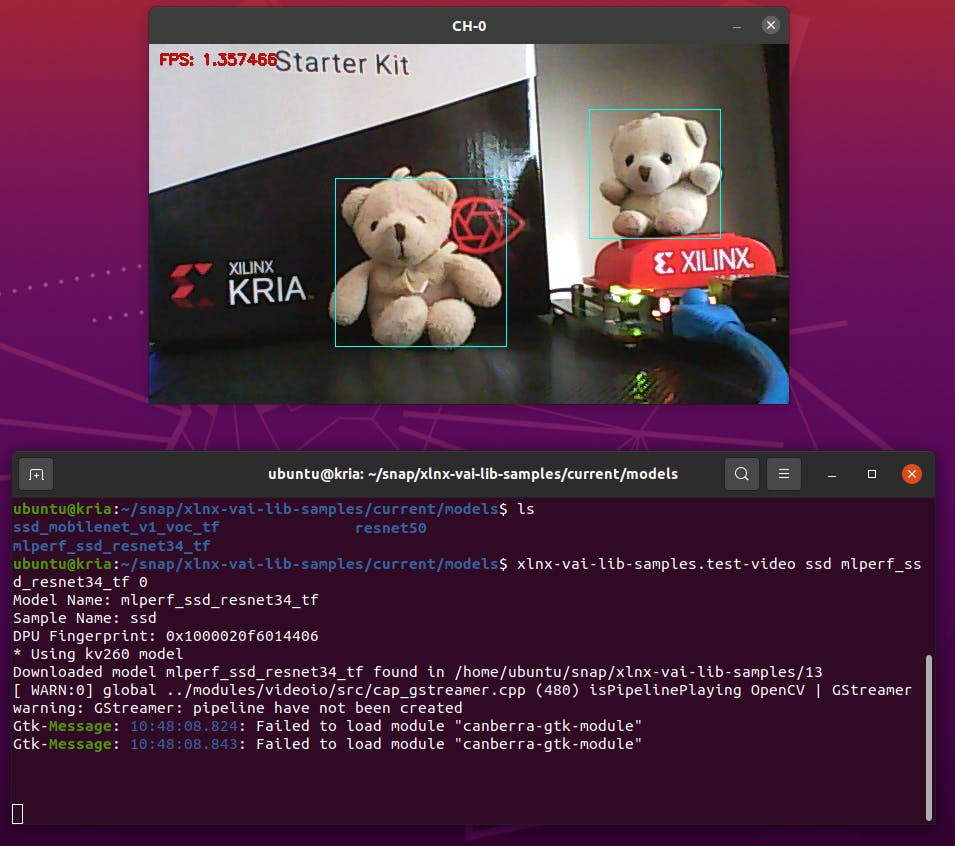
有了这个,Kria 运行良好,让我们训练我们自己的模型
PC:运行 YOLOv4 模型训练
要训练模型,请遵循 Xilinx 提供的07-yolov4-tutorial文档。它是为 Vitis v1.3 编写的,但当前 Vitis v2.0 的步骤也完全相同。
该应用程序用于检测火灾事件,因此在此处下载火灾图像开源数据集:
fire-smoke(2059 年的图像,包括标签)-GoogleDrive
对于培训,请参考.cfg此处的火灾数据集文件。
我们必须修改此.cfg配置文件以与 Xilinx Zynq Ultrascale+ DPU 兼容:
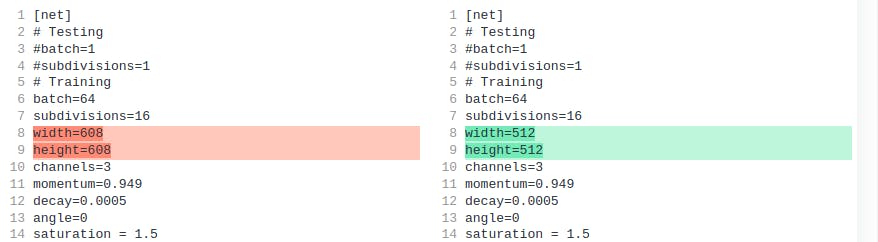
[#1] Xilinx 建议文件输入大小为 512x512(或 416x416 以加快推理速度)
[#2] DPU 不支持 MISH 激活层,因此将它们全部替换为 Leaky 激活层

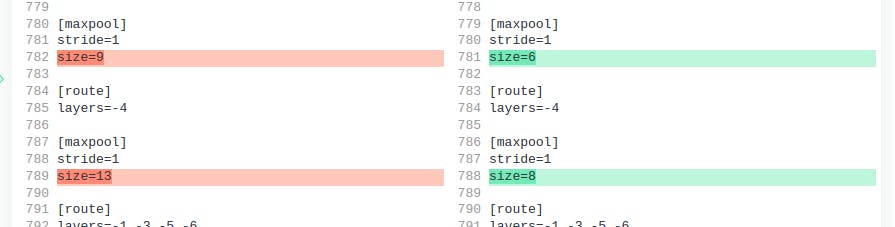
[#3] DPU 仅支持最大 SPP maxpool 内核大小为 8。默认设置为 5、9、13。但我决定将其更改为 5、6、8。
我在 Google Colab 上对其进行了训练。我遵循了 YOLOv4 的标准训练过程,没有做太多修改。
在我的 github 页面中找到包含分步说明的 Jupyter 笔记本。
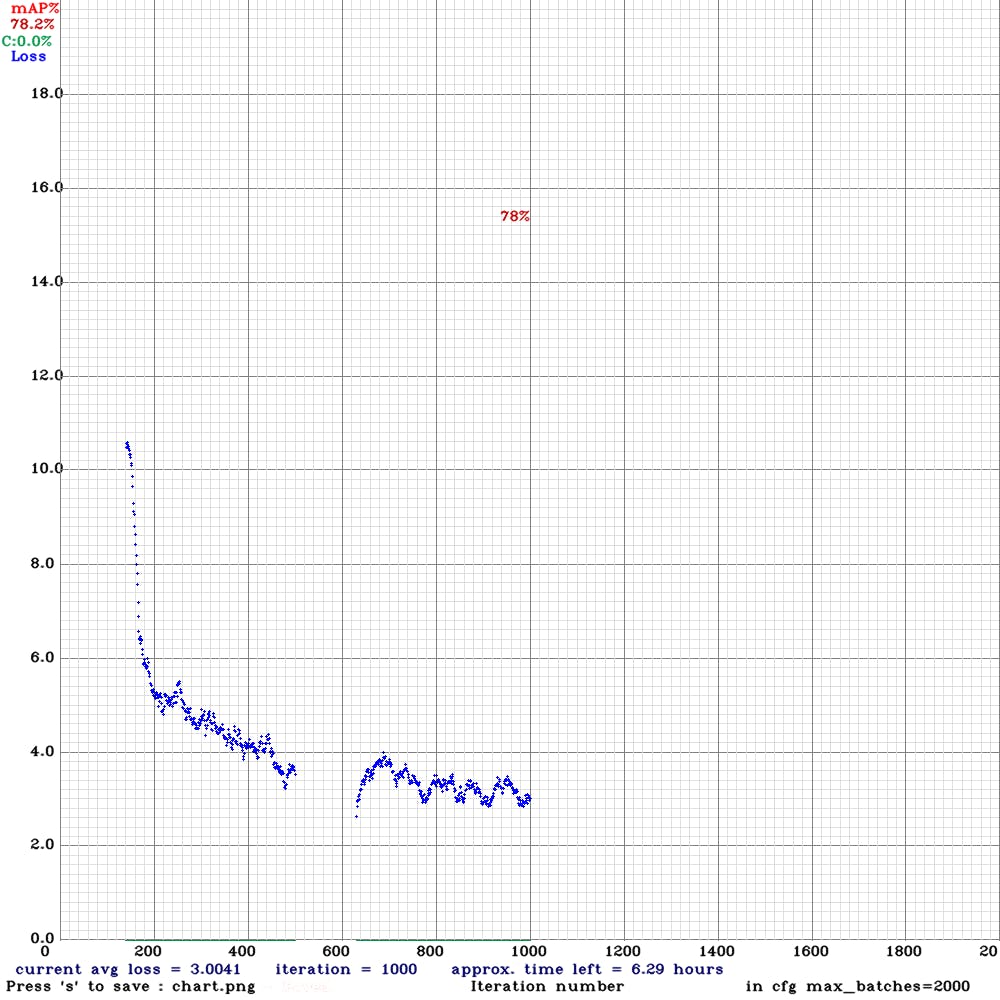
这是损失的进展图。我运行了大约 1000 次迭代,因为我没有太多的带宽资源可以继续。我觉得这个原型的准确性已经足够好了,但如果可以的话,我建议训练到几千次迭代。
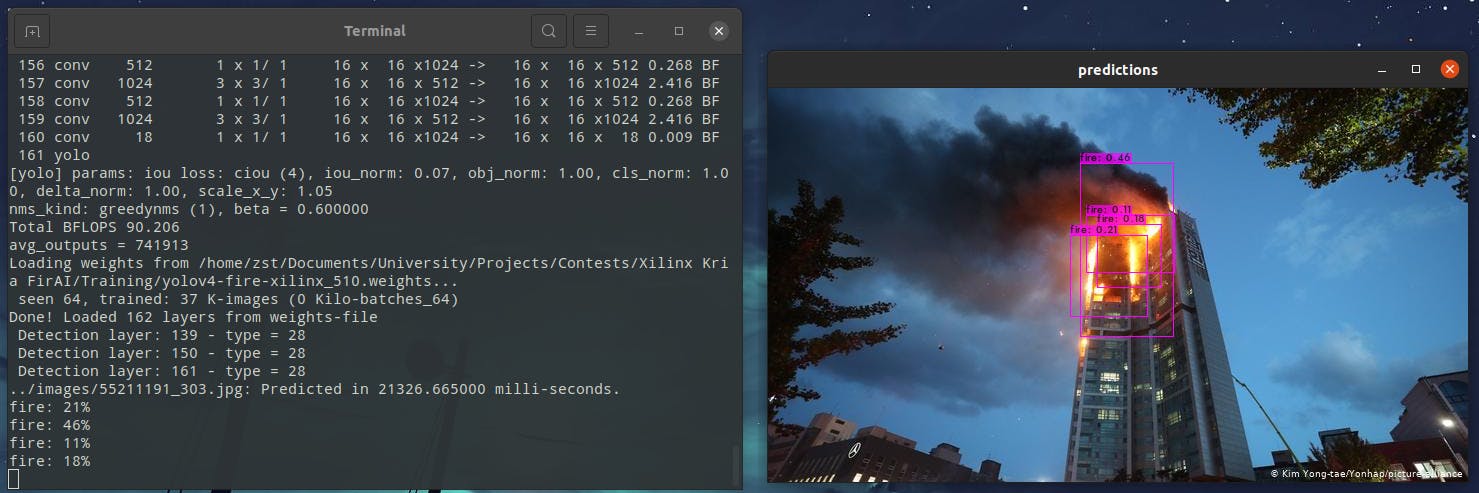
下载最佳权重文件 ( yolov4-fire-xilinx_1000.weights)。我在 CPU 上本地运行 yolov4 推理,一张图像大约需要 20 秒!稍后我们将看到它可以使用 FPGA 加速到接近实时的速度。
./darknet detector test ../cfg/fire.data ../yolov4-fire.cfg ../yolov4-fire_1000.weights image.jpg -thresh 0.1
我们现在拥有经过训练的模型,并准备将其转换为部署在 Kria 上。
PC:转换TF模型
下一步是将暗网模型转换为冻结的张量流图。keras-YOLOv3-model-set 存储库为此提供了一些有用的脚本。我们将在 Vitis AI 存储库中运行一些脚本。
首先安装docker,使用这个命令:
sudo apt install docker.io
sudo service docker start
sudo chmod 666 /var/run/docker.sock # Update your group membership
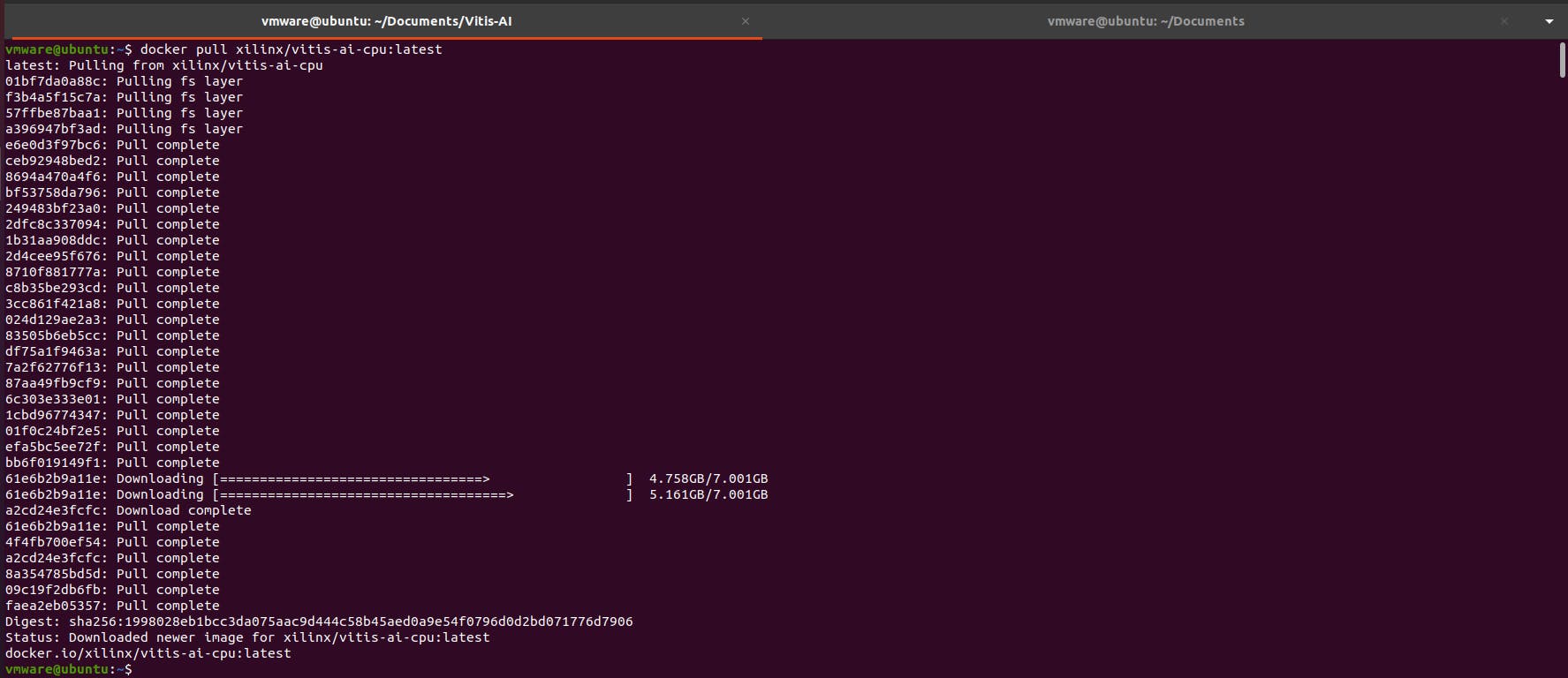
拉取泊坞窗图像。这将使用以下命令下载最新的 Vitis AI Docker。请注意,此容器是 CPU 版本。(确保运行 Docker 的磁盘分区至少有 100GB 的磁盘空间)
$ docker pull xilinx/vitis-ai-cpu:latest
克隆 Vitis-AI 文件夹
git clone --recurse-submodules https://github.com/Xilinx/Vitis-AI
cd Vitis-AI

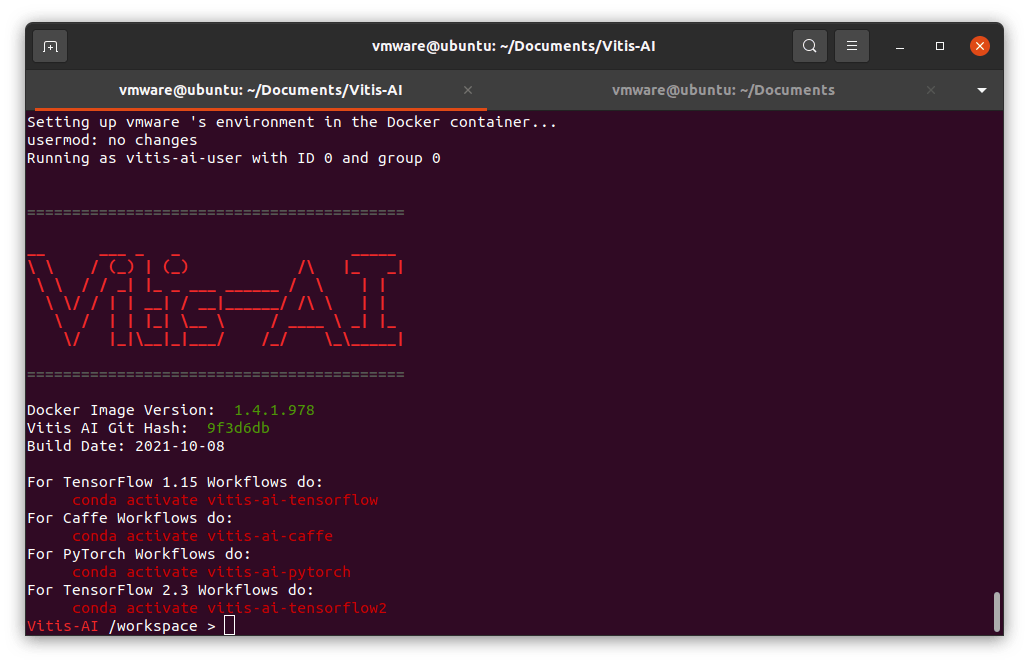
启动 Docker 实例
bash -x ./docker_run.sh xilinx/vitis-ai-cpu:latest
进入 docker shell 后,克隆教程文件。在撰写本文时,Vitis v1.4/v2.0 的教程文件已被删除,我认为它正在升级过程中。无论如何,该教程在较新的版本中都可以正常工作,因此请恢复到最新的 v1.3 提交。
> git clone https://github.com/Xilinx/Vitis-AI-Tutorials.git
> cd ./Vitis-AI-Tutorials/
> git reset --hard e53cd4e6565cb56fdce2f88ed38942a569849fbd # Tutorial v1.3
现在我们可以从这些目录访问 YOLOv4 教程:
-
从主机目录:
~/Documents/Vitis-AI/Vitis-AI-Tutorials/Design_Tutorials/07-yolov4-tutorial -
从 docker 实例中:
/workspace/Vitis-AI-Tutorials/07-yolov4-tutorial
进入教程文件夹,创建一个名为“ my_models ”的新文件夹并复制这些文件:
- 训练后的模型权重:yolov4-fire-xilinx_last.weights
- 训练配置文件:yolov4-fire-xilinx.cfg
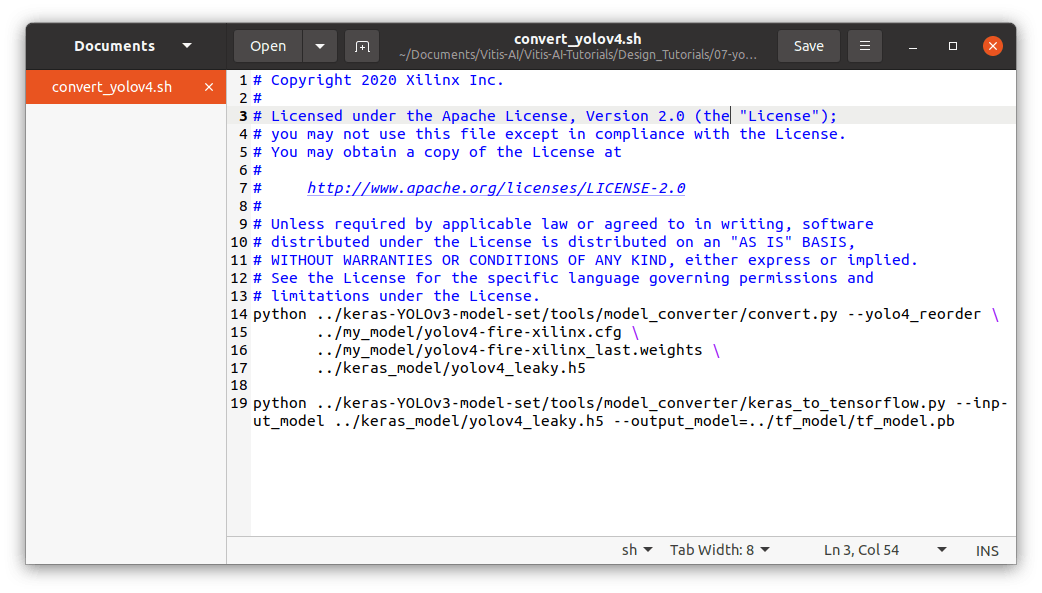
在 scripts 文件夹下,您将找到convert_yolov4脚本。编辑文件以指向我们自己的模型(cfg 和 weights 文件):
-
../my_models/yolov4-fire-xilinx.cfg \ -
../my_models/yolov4-fire-xilinx_last.weights \
现在回到终端并输入 docker 实例。激活 tensorflow 环境。我们将开始转换 yolo 模型的过程
> conda activate vitis-ai-tensorflow
> cd /workspace/Vitis-AI-Tutorials/Design_Tutorials/07-yolov4-tutorial/scripts/
> bash convert_yolov4.sh
转换后,您现在可以在“keras_model”文件夹中看到 Keras 模型 (.h5)。以及“tf_model”文件夹下的冻结模型(.pb)。
PC:量化模型
我们需要将部分训练图像复制到文件夹“ yolov4_images ”。这些图像将用于量化期间的校准。
创建一个名为“ my_calibration_images ”的文件夹,并在其中粘贴一些训练图像的随机文件。然后我们可以将所有图像的名称列出到 txt 文件中。
> ls ./my_calibration_images/ > tf_calib.txt
然后编辑yolov4_graph_input_keras_fn.py ,指向这些文件位置。
运行./quantize_yolov4.sh。这将在yolov4_quantized目录中生成一个量化图。

现在您将在“yolov4_quantized”文件夹中看到量化的冻结模型。
PC:编译xmodel和prototxt
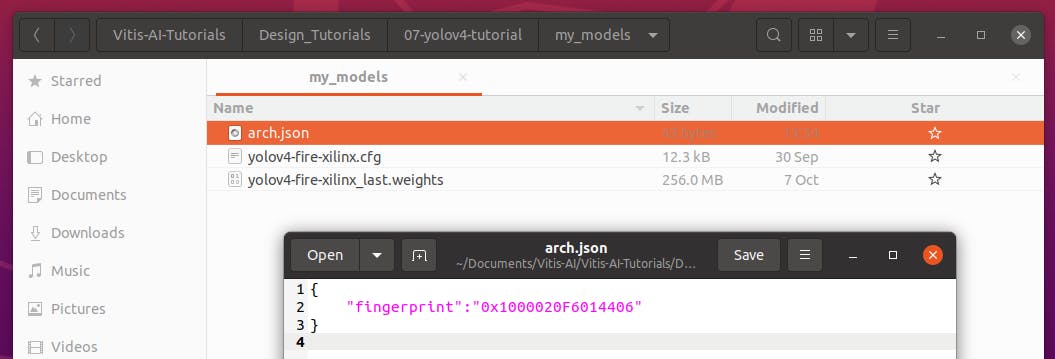
创建用于编译 xmodel 的 arch.json,并将其保存到相同的“ my_models ”文件夹中。
请注意使用我们之前在 Kria 上看到的相同 DPU 指纹。在这种情况下,以下内容适用于 Kria B3136 配置 (Vitis AI 1.3/1.4/2.0)
{
"fingerprint":"0x1000020F6014406"
}
修改compile_yolov4.sh指向我们自己的文件
NET_NAME=dpu_yolov4
ARCH=/workspace/Vitis-AI-Tutorials/Design_Tutorials/07-yolov4-tutorial/my_models/arch.json
vai_c_tensorflow --frozen_pb ../yolov4_quantized/quantize_eval_model.pb \
--arch ${ARCH} \
--output_dir ../yolov4_compiled/ \
--net_name ${NET_NAME} \
--options "{'mode':'normal','save_kernel':'', 'input_shape':'1,512,512,3'}"
运行编译
> bash -x compile_yolov4.sh
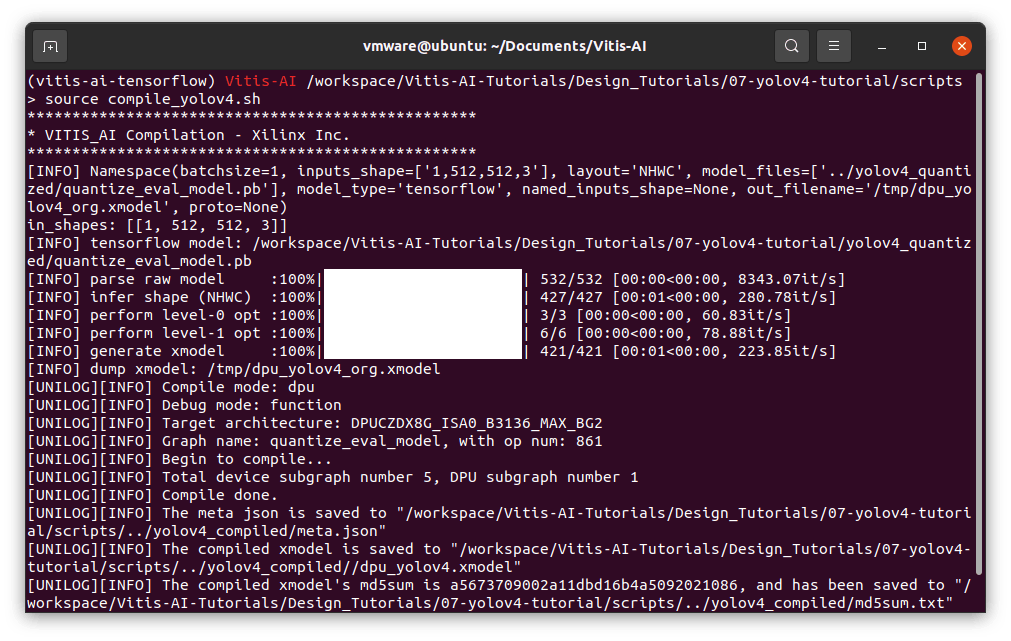
在“yolov4_compiled”文件夹中,您将看到 meta.json 和 dpu_yolov4.xmodel。这构成了可部署模型。您可以将这些文件复制到 Kria,因为我们接下来将使用它。
请注意,如果您遵循旧指南,您可能会看到正在使用的 *.elf 文件。这被 *.xmodel 文件替换
从 Vitis-AI v1.3 开始,该工具不再生成 *.elf 文件。而不是 *.xmodel 将用于在边缘设备上部署模型。
对于某些应用程序,需要*.prototxt文件和*.xmodel文件。要创建 prototxt,首先我们可以复制示例并进行修改。
请注意根据您的 YOLO 配置要遵循的事项:
- “biases”:必须与 yolo.cfg 文件中的“anchors”相同
- “num_classes”:必须与 yolo.cfg 文件中的“classes”相同
- “layer_name”:必须与 xmodel 文件中的输出相同
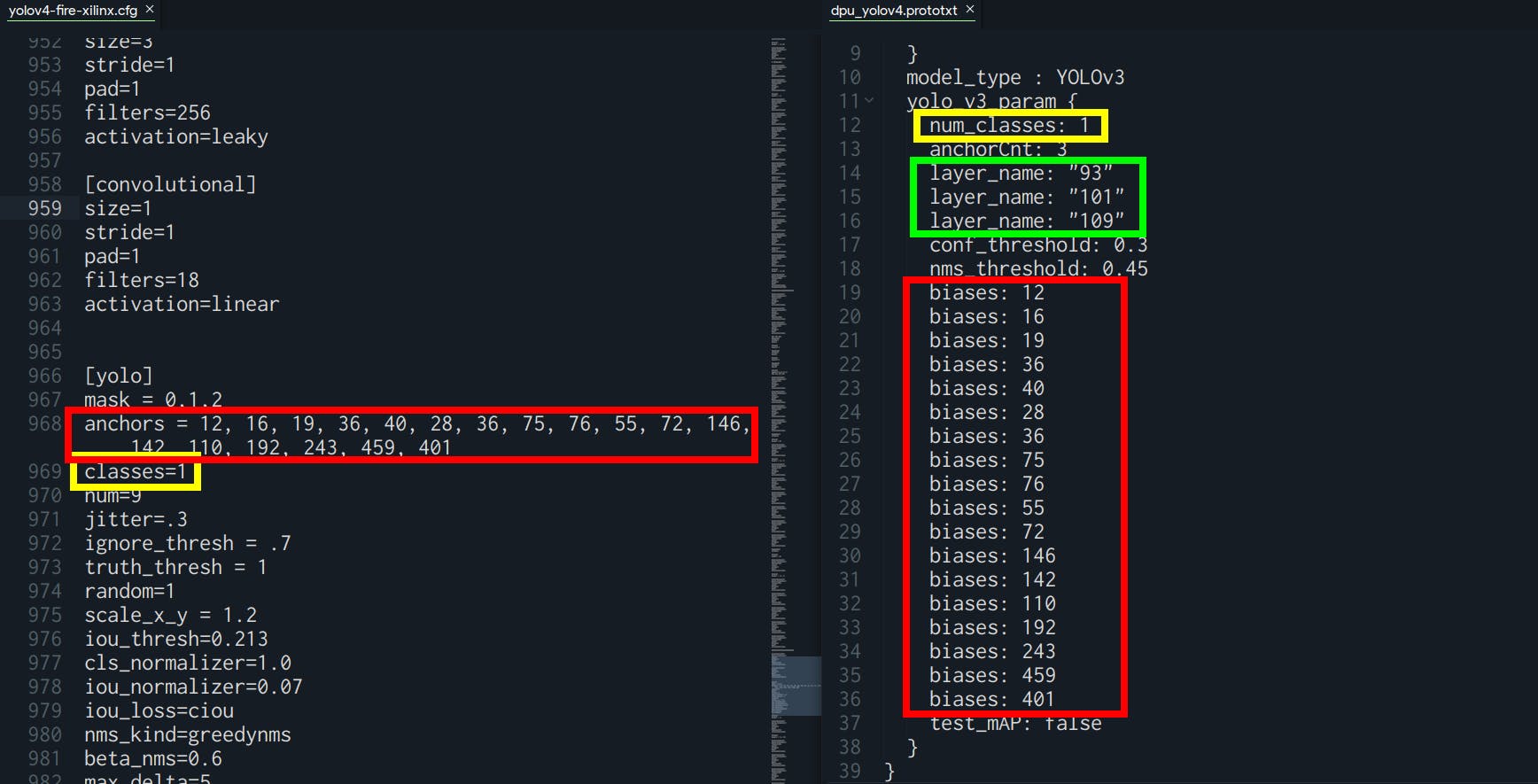
对于 layer_name,您可以转到 Netron ( https://netron.app/ ) 并打开 your.xmodel 文件。由于 YOLO 模型有 3 个输出,您还会看到 3 个结束节点。
对于每个节点 (fix2float),您可以从名称中找到编号。
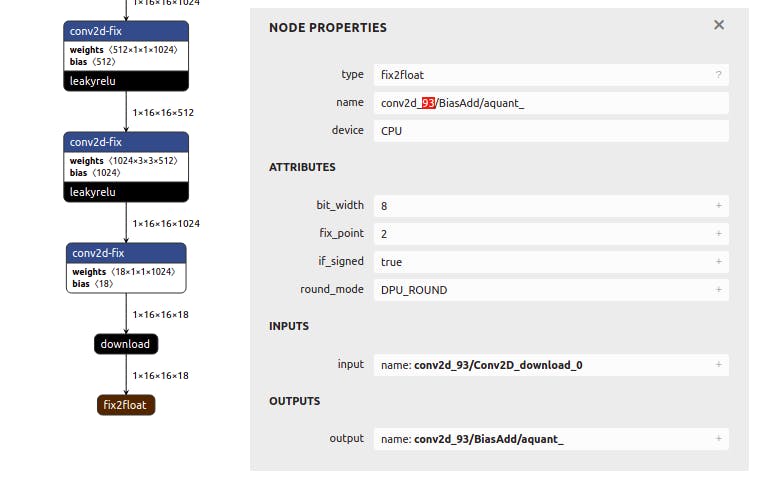
如果您在运行模型时可能遇到分段错误,很可能是由于.prototxt文件配置错误。如果是这样,请返回此处并验证一切是否正确。
Kria:在 Kria Ubuntu 上测试部署
这些是您应该复制到 Kria 的必要文件。
创建一个名为“dpu_yolov4”的文件夹并复制所有模型文件。我选择在我的 Documents 文件夹中创建它。该应用程序需要以下 3 个文件:
- 元.json
- dpu_yolov4.xmodel
- dpu_yolov4.prototxt
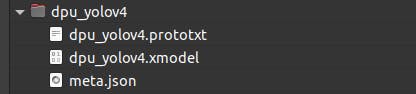
我们可以通过直接从 snap bin 文件夹中调用test_video_yolov4可执行文件来测试模型。
> sudo xlnx-config --xmutil loadapp nlp-smartvision # Load the DPU bitstream
> cd ~/Documents/
> /snap/xlnx-vai-lib-samples/current/bin/test_video_yolov4 dpu_yolov4 0
你会看到它检测到所有的火。在这种情况下,有多个重叠的框。我们在创建 python 应用程序时会考虑到这一点。

Kria:Python 应用程序实现
在我的 Github 页面中,您将找到我的完整应用程序实现。它考虑了重叠框并执行非最大抑制 (NMS) 边界框算法。它还打印边界框的置信度。此外,坐标记录在框架中。在现实生活中的系统中,这些信息将被发送到转发器并提醒负责人员。

视频
结论
使用赛灵思工具进行加速,我们可以看到推理如何从我的 PC CPU 上的 20 秒 1 帧提高到赛灵思 DPU 加速器上的至少 5 帧/秒。这相当于将推理速度提高了 100 倍!由于 Kria 还是一款小巧轻便的设备,它具有高性能、易于部署和低功耗的特点。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章




