
资料下载


将现有的Jetson Nano项目移植到TI SK-TDA4VM
尚文清
分享资料个
描述
边缘机器学习应用
功能强大但低功耗的单板计算机的出现意味着每个步骤都可以在设备本身上完成,而不是像在典型的机器学习工作流程中那样在本地收集数据并将其发送到云端进行处理和推理。这意味着工业监控、健康跟踪和自动化农业等应用都可以变得更加高效和准确。
SK-TDA4VM 和 Jetson Nano
NVIDIA 的 Jetson Nano 开发套件于 2019 年发布,配备 128 核 Maxwell GPU 以及主频为 1.43GHz 的四核 ARM A57 CPU。此外,该套件还具有 4GB LPDDR4 内存、HDMI/显示端口连接器、千兆以太网和四个 USB 3.0 端口以及一个 40 针 GPIO 接头和双 CSI 摄像头连接器。

相反,德州仪器 (TI) 的 SK-TDA4VM 套件包含双核 Arm Cortex-A72 CPU、DSP、深度学习、视觉和多媒体加速器、4GB LPDDR4 内存、四个 USB 端口、千兆以太网和 HDMI/Display Port 显示输出. 要添加更多摄像头,沿边缘有两个 CSI 摄像头连接器,在板的底部还有一个 40 针 Semtec 连接器。与 Jetson Nano 不同,SK-TDA4VM 包含一个用于 WiFi/蓝牙卡的 M.2 E-key 插槽和一个用于 SSD 或其他 PCIe x 4 设备的 M.2 M-key 插槽。查看之前的入门指南,了解有关如何设置套件和运行简单演示的更多信息。

现有项目
该项目的起点是使用 JetPack4.5 用 Python 3.6编写的一个简单示例,它从 COCO17 数据集中获取 20 张调整大小的图像,并将它们传递到从 TensorFlow 网站获取的SSD MobileNet V1 TensorFlow Lite 模型。一旦设置了输入数据,Jetson Nano 就会在 CPU 上运行 TFLite 解释器,并计算输出结果所需的时间。在以 5W 的最大功耗运行总共 20 次迭代后,平均运行时间为223milliseconds每次推理。应该注意的是,由于 Jetson Nano 上的 TFLite 模型的功耗有限且缺乏 GPU 计算,这个数字高于优化运行时的数字。
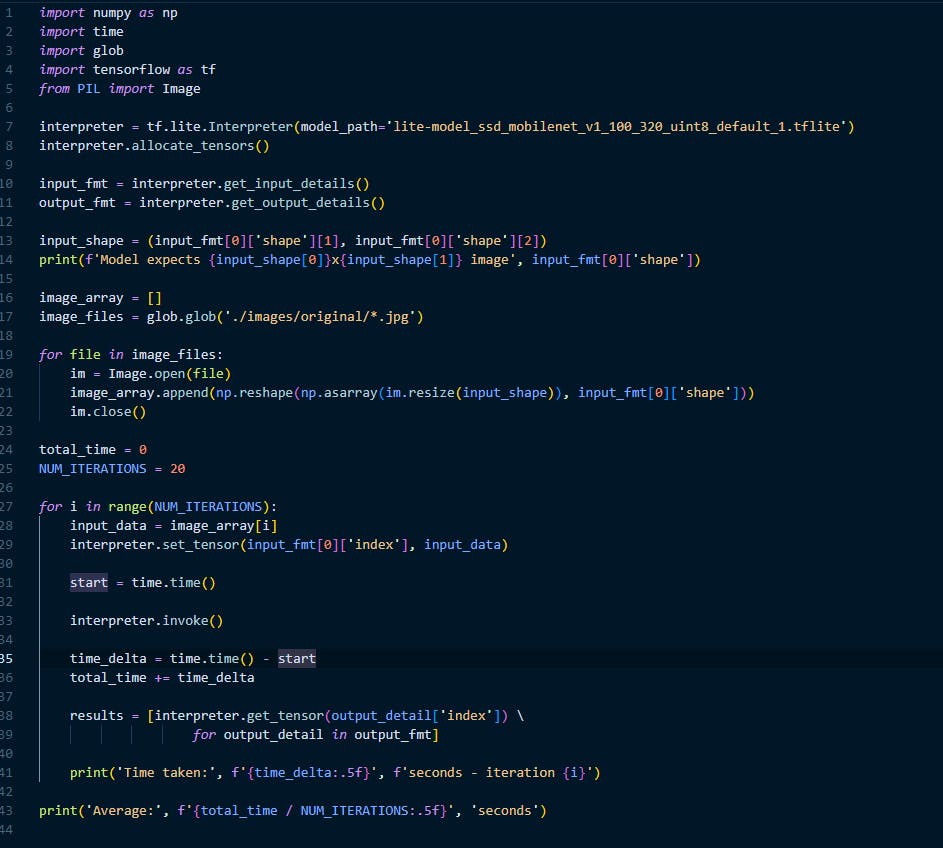
编译优化的 TensorFlow 模型
TDA4VM 的架构要求现有的预训练机器学习模型(例如.tflite文件)必须先经过编译才能在硬件上运行,以利用硬件加速器。正如我在入门指南中看到的那样,TI 提供了一个模型动物园,可以从中以正确的格式下载预训练模型。它们不仅包括.tflite文件,还param.yaml包括包含有关模型和各种其他工件的信息的文件。
为了导入自定义的 TensorFlow Lite 模型,必须首先设置编译环境。该工具集已针对在 x86 或 aarch64 架构上运行的 Ubuntu 18.04 进行了验证。我能够在 Windows 10 上的WSL 2下安装 Linux 环境,以简化设置过程。从这里,我运行了以下命令来克隆存储库并配置文件夹:
$ git clone https://github.com/TexasInstruments/edgeai-tidl-tools.git
$ cd edgeai-tidl-tools
在执行下面的脚本之前,我编辑了 requirements_pc.txt 文件以将行更改onnx为onnx==1.4.1,因为安装最新版本时出现问题。
$ source ./setup.sh --skip_cpp_deps
如果出现提示,请选择J721E作为目标设备。跑步
$ ./scripts/run_python_examples.sh
以确保编译成功。此外,查看./model-artifacts和./models目录以查看生成的工件。
为了编译模型,首先导航到examples/osrt_python目录并打开model_configs.py文件。要添加新条目,只需在字典中附加模型参数,同时更改model_path以反映模型的存储位置。例如,这是我的 SSD_MobileNet_V1 TensorFlow Lite 模型的条目:
'od-tfl-ssd_mobilenet_v1_1' : {
'model_path' : os.path.join(models_base_path,'ssd_mobilenet_v1_1_metadata_1.tflite'),
'mean': [127.5, 127.5, 127.5],
'scale' : [1/127.5, 1/127.5, 1/127.5],
'num_images' : numImages,
'num_classes': 91,
'model_type': 'od',
'session_name' : 'tflitert',
'od_type' : 'HasDetectionPostProcLayer'
}
如果您的模型属于不同类型,还可以检查列出的许多其他条目。编辑第 231 行tfl/tflrt_delegate.py以用新添加的条目替换现有的条目数组,然后运行
$ cd tfl
$ python3 tflrt_delegate.py -c
在不运行推理的情况下编译模型。需要注意的是,TIDL 提供了多种部署选项,涵盖 TFLite、ONNX 和 TVM/Neo-AI 运行时。有关详细信息,请参阅此处存储库中的 README 文件。
整合模型
现在模型已经编译,来自相应文件夹/文件的工件model-artifacts可以models通过 SFTP 复制到 TDA4VM 套件。就像 Jetson Nano 程序一样,为 SK-TDA4VM 编写的 Python 代码会创建多个随机图像,并将它们作为输入传递给 tflite 模型,同时计算推理所需的时间。对于其他项目,/opt/edge_ai_apps/apps_python默认 SK-TDA4VM 操作系统映像附带的 Python 演示应用程序是一个很好的起点。
性能比较
平均而言,TDA4VM 能够使用相同的 320x320 UINT8 图像执行推理9 milliseconds,由于其板载加速器硬件,与 Jetson Nano 相比,速度提高了 24 倍。如需更详细的推理数据,包括结果和性能指标,您可以将以下目录复制到 TDA4VM 初学者工具包的本地安装的 repo中:
./model-artifacts
./models
./dockers/J721E/PSDKRA/setup.sh
然后运行脚本:
$ cd examples/osrt_python/tfl
$ python3 tflrt_delegate.py
可以按照 edgeai-benchmark 存储库中的说明对准确性进行基准测试。有关 TIDL 工具和 SDK 的更多信息,请务必查看存储库和SK-TDA4VM 套件的文档。
更进一步
Edge Impulse不是获取预训练的 TensorFlow 模型,将其转换为 TensorFlow Lite,然后使用 TIDL 实用程序生成工件,而是使其变得极其简单,因为项目只需单击一个按钮即可部署模型。此存储库包含有关创建新项目、下载训练数据、构建自定义学习块以及运行 Docker 容器以输出训练tflite和onnx模型的说明。edge -impulse-linux-runner 命令会将优化模型下载到设备并开始分类,并在网络浏览器中提供输出。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章



