
资料下载


深度学习在图像超清化的应用
分享资料个
深度学习的出现使得算法对图像的语义级操作成为可能。本文即是介绍深度学习技术在图像超清化问题上的最新研究进展。
深度学习最早兴起于图像,其主要处理图像的技术是卷积神经网络,关于卷积神经网络的起源,业界公认是Alex在2012年的ImageNet比赛中的煌煌表现。虽方五年,却已是老生常谈。因此卷积神经网络的基础细节本文不再赘述。在下文中,使用CNN(Convolutional Neural Network)来指代卷积神经网络。
CNN出现以来,催生了很多研究热点,其中最令人印象深刻的五个热点是:
深广探索:VGG网络的出现标志着CNN在搜索的深度和广度上有了初步的突破。
结构探索:Inception及其变种的出现进一步增加了模型的深度。而ResNet的出现则使得深度学习的深度变得“名副其实”起来,可以达到上百层甚至上千层。
内容损失:图像风格转换是CNN在应用层面的一个小高峰,涌现了一批以Prisma为首的小型创业公司。但图像风格转换在技术上的真正贡献却是通过一个预训练好的模型上的特征图,在语义层面生成图像。
对抗神经网络(GAN):虽然GAN是针对机器学习领域的架构创新,但其最初的应用却是在CNN上。通过对抗训练,使得生成模型能够借用监督学习的东风进行提升,将生成模型的质量提升了一个级别。
Pixel CNN:将依赖关系引入到像素之间,是CNN模型结构方法的一次比较大的创新,用于生成图像,效果最佳,但有失效率。
这五个热点,在图像超清这个问题上都有所体现。下面会一一为大家道来。
CNN的第一次出手
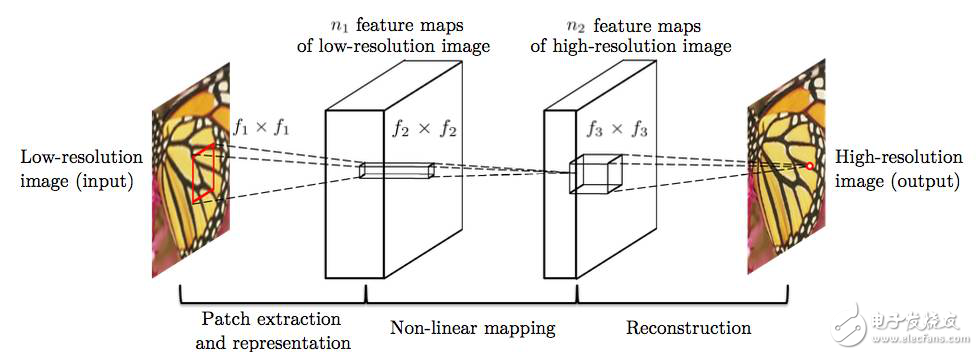
图2 首个应用于图像超清问题的CNN网络结构(输入为低清图像,输出为高清图像。该结构分为三个步骤:低清图像的特征抽取、低清特征到高清特征的映射、高清图像的重建。)
图像超清问题的特点在于,低清图像和高清图像中很大部分的信息是共享的,基于这个前提,在CNN出现之前,业界的解决方案是使用一些特定的方法,如PCA、Sparse Coding等将低分辨率和高分辨率图像变为特征表示,然后将特征表示做映射。
基于传统的方法结构,CNN也将模型划分为三个部分,即特征抽取、非线性映射和特征重建。由于CNN的特性,三个部分的操作均可使用卷积完成。因而,虽然针对模型结构的解释与传统方法类似,但CNN却是可以同时联合训练的统一体,在数学上拥有更加简单的表达。
不仅在模型解释上可以看到传统方法的影子,在具体的操作上也可以看到。在上述模型中,需要对数据进行预处理,抽取出很多patch,这些patch可能互有重叠,将这些Patch取合集便是整张图像。上述的CNN结构是被应用在这些Patch而不是整张图像上,得到所有图像的patch后,将这些patch组合起来得到最后的高清图像,重叠部分取均值。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章


下载排行榜
- 暂无相关数据

