
资料下载


×
ARM体系结构之流水线解析
消耗积分:1 |
格式:rar |
大小:0.3 MB |
2017-10-18
分享资料个
2.2 流水线
2.2.1 流水线的概念与原理
处理器按照一系列步骤来执行每一条指令。典型的步骤如下:
① 从存储器读取指令(fetch);
② 译码以鉴别它是属于哪一条指令(dec);
③ 从指令中提取指令的操作数(这些操作数往往存在于寄存器中)(reg);
④ 将操作数进行组合以得到结果或存储器地址(ALU);
⑤ 如果需要,则访问存储器以存储数据(mem);
⑥ 将结果写回到寄存器堆(res)。
并不是所有的指令都需要上述每一个步骤,但是,多数指令需要其中的多个步骤。这些步骤往往使用不同的硬件功能,例如,ALU可能只在第4步中用到。因此,如果一条指令不是在前一条指令结束之前就开始,那么在每一步骤内处理器只有少部分的硬件在使用。
有一种方法可以明显改善硬件资源的使用率和处理器的吞吐量,这就是当前一条指令结束之前就开始执行下一条指令,即通常所说的流水线(Pipeline)技术。流水线是RISC处理器执行指令时采用的机制。使用流水线,可在取下一条指令的同时译码和执行其他指令,从而加快执行的速度。可以把流水线看作是汽车生产线,每个阶段只完成专门的处理器任务。
采用上述操作顺序,处理器可以这样来组织:当一条指令刚刚执行完步骤①并转向步骤②时,下一条指令就开始执行步骤①。图2.1说明了这个过程。从原理上说,这样的流水线应该比没有重叠的指令执行快6倍,但由于硬件结构本身的一些限制,实际情况会比理想状态差一些。
2.2.2 流水线的分类
从Acorn Computer公司在1983~1985年间开发的第一个3µm器件,到ARM公司在1990~1995年间开发的ARM6和ARM7,ARM整数处理器核的组织结构变化很小,这些处理器都是采用3级流水线,而这一时期CMOS工艺的发展,几乎将特征尺寸减少了一个数量级。因此,核的性能提高很快,但基本的操作原理大部分没有变化。
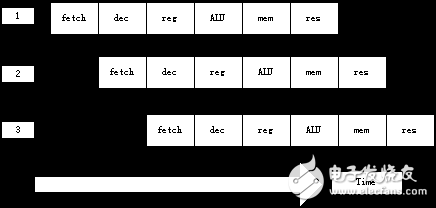
图2.1 流水线的指令执行过程
从1995年以来,ARM公司推出了几个新的ARM核。它们采用5级流水线和哈佛架构,获得了显著的高性能。例如,ARM9增加了存储器访问段和回写段,这使得ARM9的处理能力可达到平均1.1 Dhrystone1 MISP/MHz,与ARM7相比,指令吞吐量提高了约13%。
把主存储器分成两个独立编址的存储器,一个专门存放指令,称为指令存储器,简称指存;另一个专门存放操作数,称为数据存储器,简称数存。两个存储器可以同时访问,这样就解决了取指令和读操作数的冲突。如果在此基础上规定在执行指令阶段产生的运算结果只写到通用寄存器中,不写到主存,那么取指令、分析指令和执行指令就可以同时进行。
ARM10更是把流水线增加到6级。ARM10的平均处理能力达到1.3 Dhrystone MISP/MHz,与ARM7相比,指令吞吐量提高了约34%。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章





