
资料下载


×
一种创新的无监督文本规范化系统
消耗积分:1 |
格式:rar |
大小:0.92 MB |
2017-12-15
分享资料个
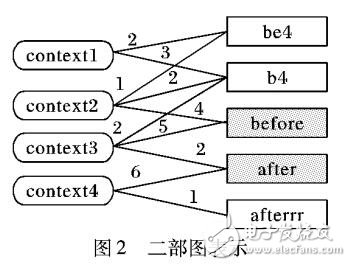
推特文本中包含着大量的非标准词,这些非标准词是由人们有意或无意而创造的。对很多自然语言处理的任务而言,预先对推特文本进行规范化处理是很有必要的。针对已有的规范化系统性能较差的问题,提出一种创新的无监督文本规范化系统。首先,使用构造的标准词典来判断当前的推特是否需要标准化。然后,对推特中的非标准词会根据其特征来考虑进行一对一还是一对多规范化;对于需要一对多的非标准词,通过前向和后向搜索算法,计算出所有可能的多词组合。其次,对于多词组合中的非规范化词,基于二部图随机游走和误拼检查,来产生合适的候选。最后,使用基于上下文的语言模型来得到最合适的标准词。所提算法在数据集上获得86. 4qo的F值,超过当前最好的基于图的随机游走算法10个百分点。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章



