
资料下载


×
结合BERT模型的中文文本分类算法
消耗积分:0 |
格式:pdf |
大小:2.58 MB |
2021-03-11
分享资料个
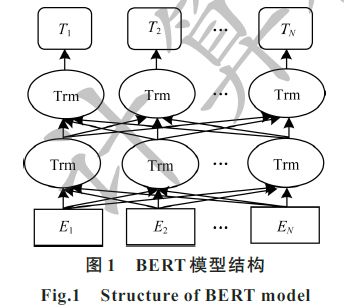
针对现有中文短文夲分类算法通常存在特征稀疏、用词不规范和数据海量等问题,提出一种基于Transformer的双向编码器表示(BERT)的中文短文本分类算法,使用BERT预训练语言模型对短文本进行句子层面的特征向量表示,并将获得的特征冋量输λ Softmax回归模型进行训练与分类。实验结果表明,随着搜狐新闻文本数据量的增加,该算法在测试集上的整体F1值最高达到93%,相比基于 Textcnn模型的短文本分类算法提升6个百分点,说明其能有效表示句子层面的语义信息,具有更好的中文短文本分类效果。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章



