
资料下载


如何使用DiffNodeset结构进行最大频繁项集挖掘算法概述
分享资料个
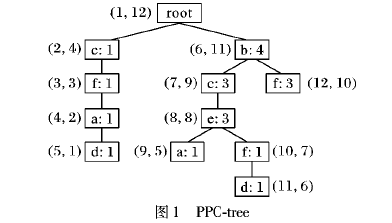
在数据挖掘中,通过挖掘最大频繁项集来代替挖掘频繁项集可以大大地提升系统的运行效率。针对现有的最大频繁项集挖掘算法的运行时间消耗仍然很大的问题,提出了一种基于DiffNodeset结构的最大频繁项集挖掘( DNMFIM)算法。首先,采用了一种新的数据结构DiffNodeset来实现求交集以及支持度的快速计算;其次,引入一种新的线性复杂度的连接方法来降低两个DiffNodeset在连接过程中的复杂度,避免了多次的无效计算;然后,将集合枚举树作为搜索空间,同时采用多种优化剪枝策略来缩小搜索空间;最后,再结合最大频繁项集挖掘算法( MAFIA)中所使用的超集检测技术来有效地提高算法的准确性。实验结果表明,DNMFIM算法在时间效率方面性能优于MAFIA与基于N-list的MAFIA( NB-MAFIA),该算法在不同类型数据集中进行最大频繁项集挖掘时均有良好的效果。
数据挖掘指的是挖掘大量数据之间的隐藏关系,数据挖掘的分析方法包括分类、估计预测、频繁项集挖掘和聚类等。其中频繁模式和关联规则是数据挖掘的主要研究领域,Agrawal等。于1994年提出频繁模式挖掘算法-Apriori算法,Han等于2004年提出了频繁模式增长(Frequent Pattemgrowth,FP-growth)算法等。但如果数据库比较庞大并且支持度阈值设置较低时,频繁项集的数量就会非常庞大,这是频繁项集挖掘所面临的一个问题。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章




