
资料下载


唤醒词检测开源分享
王璐
分享资料个
描述
团队成员
孙国明 (gs45)
天月宇文(ty26)
欧阳刘昊(lo12)
徐瑞涛(rx9)
介绍
唤醒词是诸如“Hi Siri”和“OK Google”之类的词。我们用这些词来唤醒我们的智能助手,并要求他们提供有用的信息。为了保护用户隐私并保持较低的能耗,可以将唤醒词检测功能转移到低功耗芯片上。当它检测到唤醒词时,它将其余的工作留给其他部分。
在这个项目中,我们将“是”和“否”定义为唤醒功能,并尝试使用我们的开发板 Arduino Nano 33 BLE Sense 对“是”、“否”和其他词进行分类。我们使用其 LED 灯的颜色:红色、绿色和蓝色来代表不同的类别。我们使用 TinyML 通过板上经过训练的模型实现了唤醒词检测。当人们在 Arduino 板上说话时,它会自动检测到他们。
过程
首先,我们需要获取输入。我们使用 Arduino Nano 33 BLE sense 上的内置麦克风获取输入的原始音频,然后我们使用相关接口将其提取到我们的程序中。
我们预处理输入以提取适合模型的特征。得到音频训练示例后,我们首先需要对原始音频进行特征提取。它使用 FFT 将原始音频转换为频谱图。然后我们从频谱图中提取特征。之后,我们对处理过的输入进行推理。我们使用此输入来训练我们的模型。我们的模型将输出一组我们所说的已知单词的概率。如果概率超过阈值,我们可以说我们说的词就是超过概率的那个词。
我们使用的模型经过训练可以识别单词“是”、“否”、未知单词以及静音或背景噪音。它每次输入一秒钟的数据。它输出四个概率分数,一个对应于这四个类中的每一个。它可以预测数据的类别。该模型不接收原始音频样本数据。相反,它适用于频谱图。
一秒钟的数据是一个频谱图,表示为具有 43 列和 49 行的二维数组。对于每一行,我们通过快速傅里叶变换算法 (FFT) 运行一段 30 毫秒的音频输入,该算法分析并创建一个包含 256 个频率桶的数组。然后我们平均分成 6 组。为了构建整个 2D 阵列,我们将 49 个连续的 30 毫秒音频切片的结果组合在一起,每个切片与最后一个切片重叠 10 毫秒。
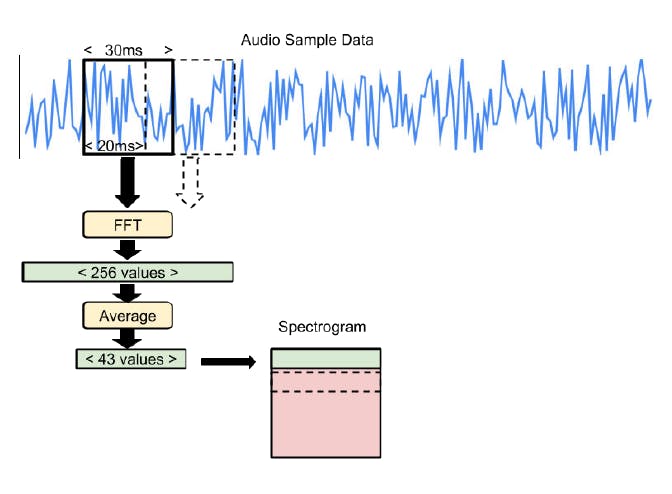
由于频谱图是二维数组,我们将其作为二维张量输入到模型中。我们使用可与任何多维向量输入一起使用的卷积网络。事实证明,它们非常适合处理频谱图数据。
在计算机上运行程序后,我们使用 Arduino 将其部署到 Arduino Nano 33 BLE Sense 板上。并通过查看电路板上的指示灯和 Arduino 的工具串行监视器来跟踪结果。
结果
我们在 Arduino Nano 33 BLE Sense 板子上运行程序,它可以区分是、否和其他未知词。
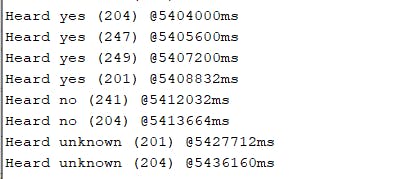
结论
在这个项目中,我们使用 TinyML 将经过训练的音频分类模型部署到 Arduino Nano 33 BLE Sense。通过这种方式,我们成功地在低功耗芯片上实现了唤醒词检测功能,从而使隐私安全和节能的数字辅助成为可能。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章






