
资料下载


使用Arduino和TensorFlow进行唤醒词检测
李波
分享资料个
描述
1.团队成员
林振阳(zl89)
益海龙(yl215)
刘正桐 (zl92)
博城湾 (bw31)
2.介绍
我们的团队 MissingPort 由林振阳、刘正彤、龙一海、万博成四人组成。我们的项目是构建一个能够识别一小段语音输入的语音识别设备。我们使用 TensorFlow 训练语音识别模型,然后将简化模型加载到我们的设备 Arduino Nano 33 BLE 中。因此,我们的设备可以接受语音输入并通过闪烁不同的灯来显示预测的识别结果。在我们的项目中,我们使用了Pete Warden 和 Daniel Situnayake在 Arduino 和超低功耗微控制器上使用 TensorFlow Lite 的机器学习作为我们的项目指南。我们的这个项目的过程显示在 Schematics 块中。
3.模型训练
首先,我们需要为我们的设备提供语音模型。因此,我们将使用机器学习从我们的语音样本中生成模型。根据 Warden 书中的说明,我们项目中使用的主要工具是 Python、TensorFlow 和 Google 的 Collaboratory。我们可以将我们的训练分为七个不同的阶段。在第一阶段,我们需要获得一个简单的数据集。在第二阶段,我们训练了深度学习模型。然后在第三阶段,我们评估了模型的性能。在第四阶段,我们转换了模型,使其可以在我们的设备上运行。接下来,在第五阶段,我们创建了代码来执行设备上的推理。在第六阶段,我们将代码构建成二进制。在最后阶段,我们将二进制文件部署到我们的微处理器中。
在模型训练中,我们尝试了很多单词对的组合,比如 cat-dog、stop-go、on-off 和原始的 yes-no。每对的训练过程最多需要两个小时。
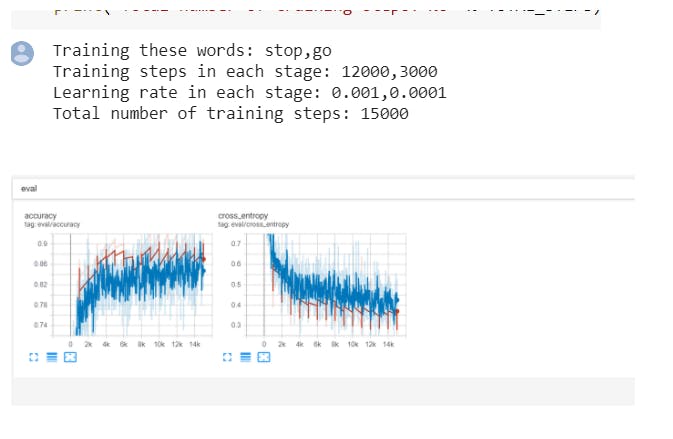

从测试结果可以看出,准确率接近90%,每对单词的准确率接近90%。如果准确率不在 90% 左右,我们将增加训练步骤以提高准确率。
4.模型部署
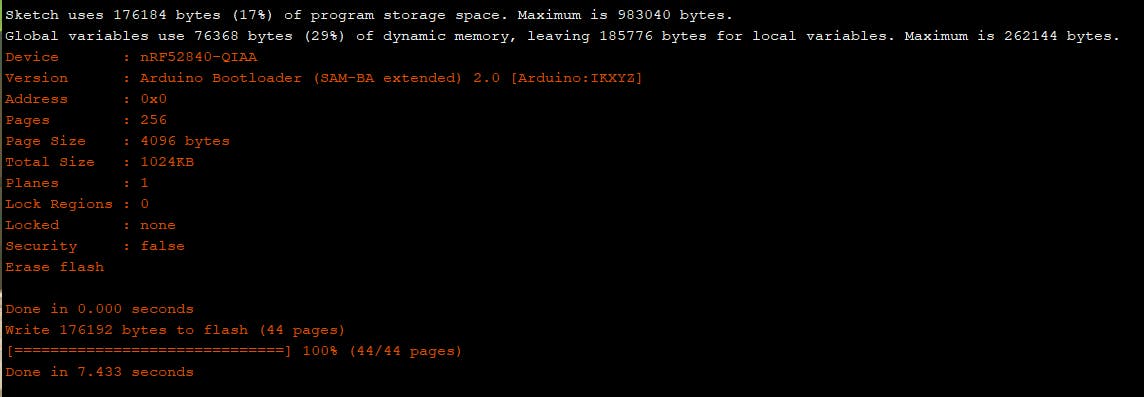
我们使用的设备是 Arduino Nano 33 BLE Sense。当我们部署模型时,需要修改原始文件夹中的三个文件,“Micro_features_model.cpp”、“arduino_command_responder.cpp”和“micro_features_micro_model_settings.cpp”。修改后,我们上传了程序,做了几次测试。
5.遇到的问题
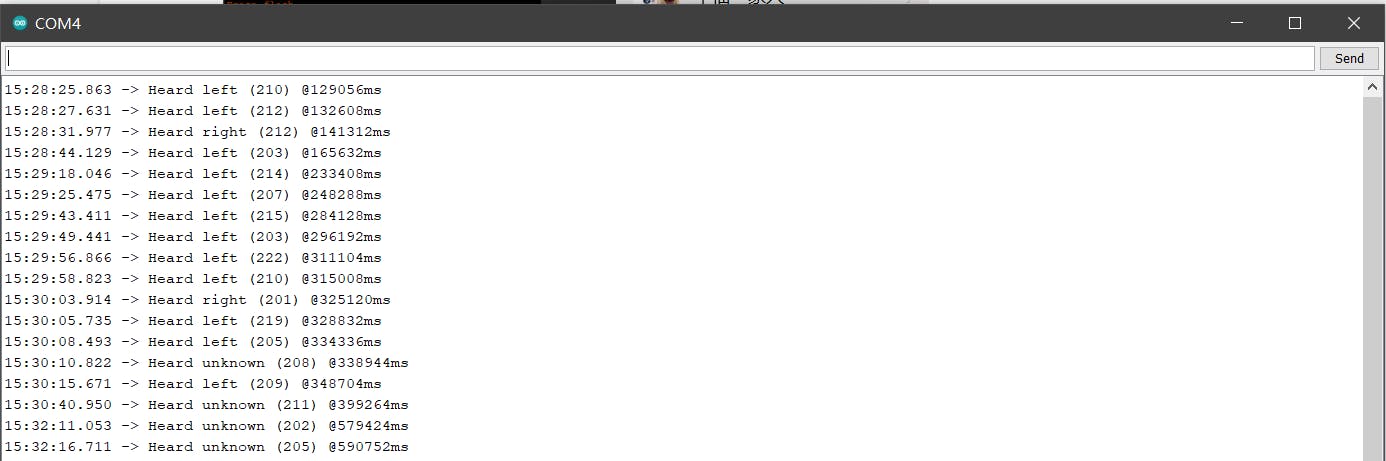
在尝试将我们的模型部署到设备时,我们遇到了一个非常奇怪的问题。除了“是,否”对之外的训练模型表现不佳。例如,左右对模型无法很好地区分背景噪音和语音。虽然增加了训练步数,但问题依然存在。对于其他模型,模型很容易预测第一个词,但很难预测第二个词。但是,对于“是-否”配对模型,一切都按预期进行。我们调查了原始语音数据源,发现有几个数据点被错误地标记。例如,在猫和狗数据文件夹中,几个“是”或“否”数据点被标记为“猫”或“狗”。我们确实相信这些错误标记的数据点会导致我们训练的模型不准确。我们为我们训练的其他几对附加了我们的模型。为了解决这个问题,必须彻底检查原始数据集,以确保所有数据点都有正确的标签。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章





