
资料下载


Raspberry Pi 4上带Respeaker的离线语音识别
陈伟
分享资料个
描述
2020 年 6 月更新:DeepSpeech 0.7.* .Screenshots 的更新命令,除了 Raspberry Pi 4 保持不变。直到最近的问题是缺乏用于该任务的简单、快速和准确的引擎。大约一年前,当我研究这个主题时,当你必须在树莓派 3 上运行 ASR(不仅仅是热词检测,还有大词汇量转录)时,有几个选择是:
- CMUS狮身人面像
- 卡尔迪
- 碧玉
链接:
还有其他几个。它们都不容易设置,也不特别适合在资源受限的环境中运行。因此,几周前,我再次开始研究这个领域,并在一些搜索中偶然发现了 Mozilla 的 DeepSpeech 引擎。它已经存在了一段时间,但直到最近(2019 年 12 月)他们才发布了 0.6.0 版本的 ASR 引擎,其中包含 .tflite 模型以及其他重大改进。它已将英文模型的大小从 188 MB 减少到 47 MB。“带有 TensorFlow Lite 的 DeepSpeech v0.6 在 Raspberry Pi 4 的单核上运行速度比实时速度更快。”Mozilla 的 Reuben Morais 在新闻公告中声称. 所以我决定亲自验证这一说法,在不同的硬件上运行一些基准测试,并制作我自己的带有热词检测的音频转录应用程序。让我们看看结果如何。
提示:我没有失望。

。
curl -LO https://github.com/mozilla/STT/releases/download/v0.7.1/deepspeech-0.7.1-models.tflite
curl -LO https://github.com/mozilla/STT/releases/download/v0.7.1/deepspeech-0.7.1-models.pbmm
curl -LO https://github.com/mozilla/STT/releases/download/v0.7.1/deepspeech-0.7.1-models.scorer
下载示例音频文件
curl -LO https://github.com/mozilla/STT/releases/download/v0.7.1/audio-0.7.1.tar.gz
tar xvf audio-0.7.1.tar.gz
树莓派 4 运行:
deepspeech --model deepspeech-0.7.*-models.tflite --scorer deepspeech-0.7.*-models.scorer --audio audio/2830-3980-0043.wav
如果成功,您应该看到以下输出
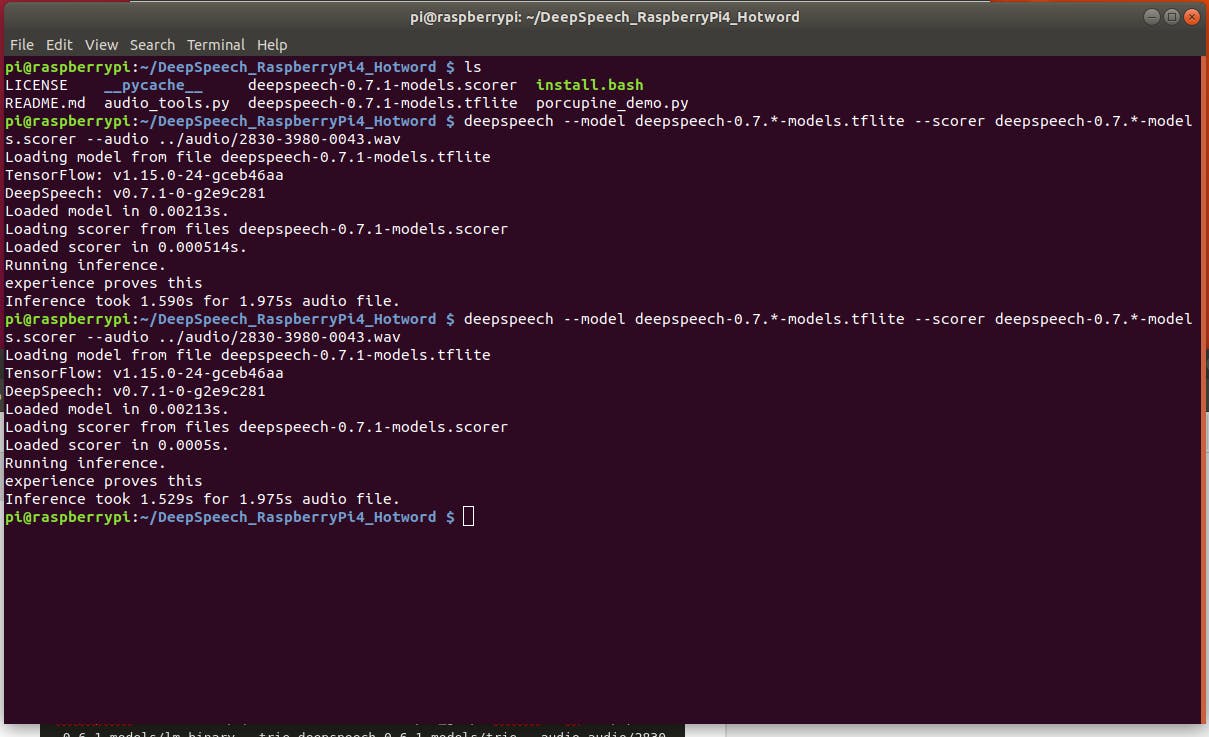
不错!1.975 秒的声音文件为 1.529 秒。它比实时更快。
Nvidia Jetson Nano 运行:
deepspeech --model deepspeech-0.7.*-models.tflite --scorer deepspeech-0.7.*-models.scorer --audio audio/2830-3980-0043.wav
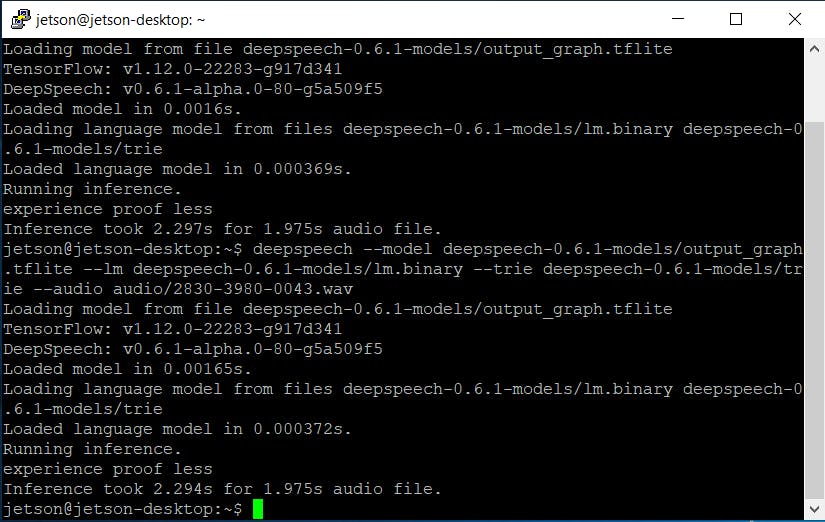
嗯..比树莓派慢一点。这是意料之中的,因为 Nvidia Jetson CPU 不如 Raspberry Pi 4 强大。到目前为止,还没有用于 arm64 架构的预构建二进制文件支持 GPU,因此我们无法利用 Nvidia Jetson Nano 的 GPU 进行推理加速。我认为这个任务不在 DeepSpeech 团队的路线图上,所以在不久的将来我会在这里自己做一些研究,并尝试编译该二进制文件,看看使用 GPU 可以实现哪些速度提升。但几秒钟的速度仍然相当不错,根据您的项目,您可能希望选择在 CPU 上运行 DeepSpeech 并让 GPU 用于其他深度学习任务。
视窗 10/Linux
deepspeech --model deepspeech-0.7.*-models.tflite --scorer deepspeech-0.7.*-models.scorer --audio audio/2830-3980-0043.wav
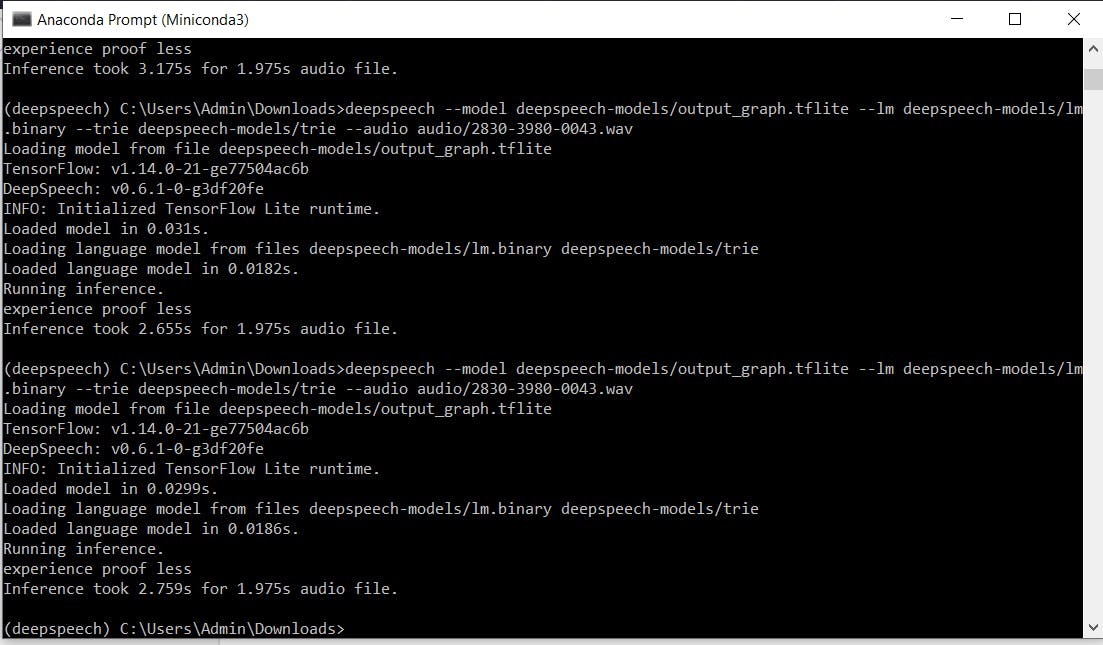
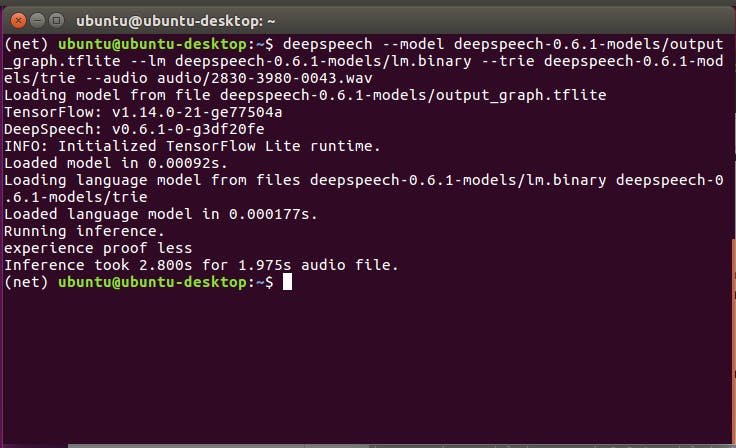
或者如果使用启用 GPU 的版本:
deepspeech --model deepspeech-0.7.*-models.pbmm --scorer deepspeech-0.7.*-models.scorer --audio audio/2830-3980-0043.wav
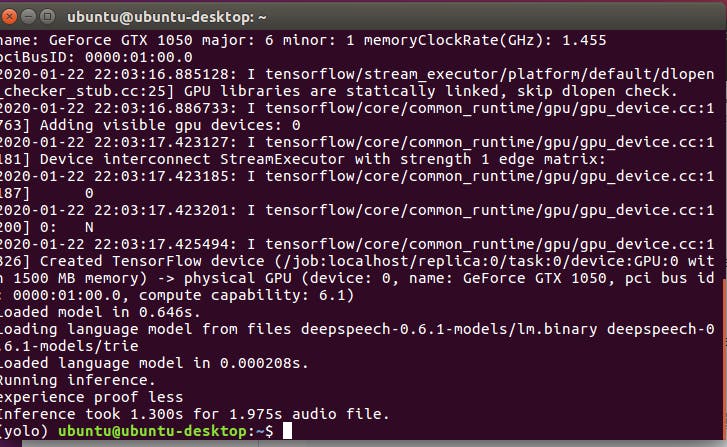
如您所见,.tflite 模型在现代 CPU 系统上实现了亚实时,这对于创建离线 ASR 应用程序的人们来说是个好消息。
以下是对比结果表:
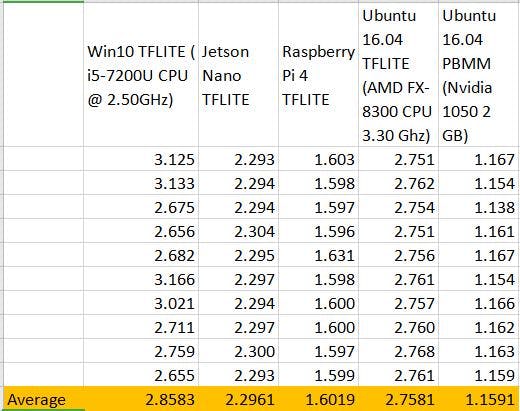
好吧,我们对预先录制的声音样本进行了基准测试,但我们真的想做一些实时转录。让我们这样做吧!
从https://github.com/mozilla/DeepSpeech-examples下载 DeepSpeech 示例
导航到 mic_vad_streaming 并安装依赖项
pip3 install -r requirements.txt
sudo apt install portaudio19-dev
将麦克风连接到您的系统(我使用的是 Raspberry Pi 4 1 GB)。对于麦克风,尽管您可以使用任何麦克风,包括笔记本电脑的内置麦克风,但声音的质量确实对结果有很大影响。对于这个演示,我使用的是 Seeed Studio 的ReSpeaker USB 麦克风阵列。它支持 5m 远场拾音和 360° 拾音模式,并实现以下声学算法:DOA(到达方向)、AEC(自动回声消除)、AGC(自动增益控制)、NS (噪音抑制)。

python3 ../DeepSpeech-examples/mic_vad_streaming/mic_vad_streaming.py --model deepspeech-0.7.*-models.tflite --scorer deepspeech-0.7.*-models.scorer
从包含模型的文件夹中执行此命令。-v 参数允许您调整 VAD(语音活动检测)的阈值。这是演示的结果。
好,太棒了!我们可以改进吗?是的。我们真的不希望我们的设备一直在转录对话。谈论隐私噩梦和浪费电力。

。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章





