
资料下载


硬件加速人体姿态估计开源分享
杨秀英
分享资料个
描述
抽象的
简介:最新的深度学习模型与最先进的硬件相结合,可以实时执行人体姿态估计 (HPE)。HPE 是指根据图像数据估计人体的运动学模型。瑞士东部应用科学大学 ( OST )的人工智能跨学科中心 ( ICAI ) 与瑞士 VRM合作,采用了著名的OpenPoseHPE 的网络,并使其计算效率更高。让我们将此项目的网络称为 ICAIPose。当前的原型使用具有一流和计算密集型深度学习模型的多摄像头系统,可在多个图形处理单元(GPU)上运行,具有足够的性能。
为了在治疗环境中广泛采用 HPE,需要一个小型且具有成本效益的系统。因此,姿势跟踪系统应该在边缘设备上运行。
目标:在这个项目中,ICAIPose 应该在 AMD-Xilinx 的 FPGA 边缘设备 Kria KV 260 上实现。由于 ICAIPose 是为 GPU 设计的,因此在 FPGA 上运行这样一个给定的网络所需的努力和性能影响是主要关注点。
方法:该应用程序需要一个摄像头接口和一个深度学习处理单元。为了测试这些硬件部件,使用这些部件的给定示例项目首先在 Kria 板上运行。然后,使用 AMD-Xilinx 的 Vitis AI 为 FPGA 上的深度学习处理器单元 (DPU) 编译 ICAIPose 网络,并对网络进行微调。随附的 Vitis AI 运行时引擎及其 Python API 通过 FPGA 微处理器上的嵌入式 Linux 与 DPU 进行通信。
结论:ICAIPose 是一个非常大的神经网络,具有超过 100 个 GOps 来处理一帧。然而,在 KV260 上可以实现每秒 8 帧的吞吐量。基于 GPU 的 NVIDIA Jetson Xavier NX 的成本是 Kria 主板的两倍多,它实现了相似的帧速率。
ICAIPose 在具有良好性能的边缘设备上的成功实施为在治疗环境中的广泛应用开辟了领域。
AMD-Xilinx 的 Vitis AI 框架已经过广泛测试并显示出其优势,但也存在一些初期问题。对于在 FPGA 上运行深度神经网络,Vitis AI 是一个在开发时间和性能之间取得良好平衡的框架。在用 HDL 或 HLS 实现硬件加速算法之前应该考虑这一点。
先决条件
- 安装了 Vitis AI 的 Linux 主机 PC
- 了解 Vitis AI 工作流程
- KV260 上网
基础知识
HPE 网络的通常输出是给定人体姿势关键点的置信度图。对于单个HPE的任务,找到置信度图的最大值并分配相应的关键点。

相机接口

相机接口是设计的重要组成部分。Kria KV260 Basic Accessory Pack 包含一个小型相机。
AMD-Xilinx 为Kria™ KV260 Vision AI Starter Kit Applications提供了一个示例应用程序。
智能相机应用程序的模块设计表明,硬件平台包含了我们这个项目所需的一切,包括相机的硬件接口和 DPU。此示例应用程序可用作基础设计,以使用相机运行自定义 Vitis AI 模型。
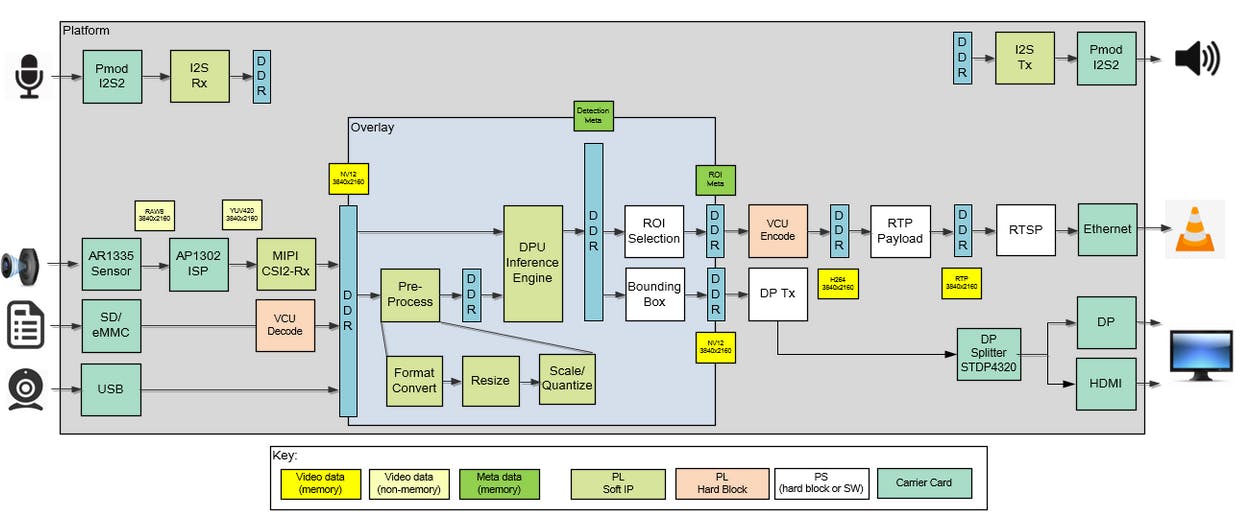
对基础设计的修改
首先,仔细检查所有版本以确保它们匹配:
- 对于 Vitis AI 1.4 和以前的版本,KV260 的板映像为 2020.2
- 这需要使用 Smartcamera 应用程序,该应用程序也使用 2020.2 板映像(不是最新版本)。
- 2020.2智能相机平台的Vitis AI版本为Vitis AI 1.3.0
按照此说明在 KV260 上安装 smartcamera 应用程序(直到第 5 节)。
使用以太网端口将 KV260 板连接到本地网络。
通过 UART/JTAG 连接时,检查以太网 (eth0) 端口的分配 IP 地址。
ifconfig
该命令的输出类似于:
eth0 Link encap:Ethernet HWaddr 00:0a:35:00:22:01
inet addr:152.96.212.163 Bcast:152.96.212.255 Mask:255.255.255
inet6 addr: fe80::20a:35ff:fe00:2201/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:67 errors:0 dropped:0 overruns:0 frame:0
TX packets:51 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:9478 (9.2 KiB) TX bytes:5806 (5.6 KiB)
Interrupt:44
在这种情况下,IP 地址是152.96.212.163.
使用此地址从主机 PC(连接到与 KV260 相同的网络)通过网络连接ssh到 KV260。
ssh petalinux@
要运行所有 Vitis AI 示例,必须在 KV260 上进行一些进一步的安装。确保设备已连接到互联网。
X11-转发
sudo dnf install packagegroup-petalinux-x11
设置显示环境
export DISPLAY=:0.0
葡萄籽油
sudo dnf install packagegroup-petalinux-vitisai
开放式CV
sudo dnf install packagegroup-petalinux-opencv
柏油
sudo dnf install xz
Vitis AI 运行时
sudo wget https://www.xilinx.com/bin/public/openDownload?filename=vitis-ai-runtime-1.3.0.tar.gz
sudo tar -xzvf openDownload\?filename\=vitis-ai-runtime-1.3.0.tar.gz
cd vitis-ai-runtime-1.3.0/aarch64/centos/
sudo bash setup.sh
Vitis AI 运行时 (VART) 需要DPU.xclbin文件中vart.conf文件的位置。但相应的xclbin文件是来自 smartcam 应用程序的文件。
使用以下命令更改和 xclbin 文件。vart.conf
echo "firmware: /lib/firmware/xilinx/kv260-smartcam/kv260-smartcam.xclbin" | sudo tee /etc/vart.conf
sudo cp /lib/firmware/xilinx/kv260-smartcam/kv260-smartcam.xclbin /usr/lib/
sudo mv /usr/lib/kv260-smartcam.xclbin /usr/lib/dpu.xclbin
在运行 Vitis AI 示例之前,必须加载相应的 smartcam 应用程序(每次启动后)。
sudo xmutil unloadapp
sudo xmutil loadapp kv260-smartcam
加载 KV260-smartcam 应用程序后,可以使用以下 GStreamer 命令使用 X11-forwarding 测试相机:
gst-launch-1.0 mediasrcbin media-device=/dev/media0 v4l2src0::io-mode=dmabuf v4l2src0::stride-align=256 ! video/x-raw, width=256, height=256, format=NV12, framerate=30/1 ! videoconvert! ximagesink
如果通过 HDMI(本例中为 1920x1200)连接显示器,则也可以测试相机。请根据您连接的显示器更改宽度和高度参数
gst-launch-1.0 mediasrcbin media-device=/dev/media0 v4l2src0::io-mode=dmabuf v4l2src0::stride-align=256 ! video/x-raw, width=1920, height=1200, format=NV12, framerate=30/1 ! kmssink driver-name=xlnx plane-id=39 sync=false fullscreen-overlay=true
Vitis AI 模型动物园
在下一个项目步骤中,将结合 Vitis AI 对摄像头系统进行测试。借助来自Vitis AI Model Zoo的大量预训练神经网络,可以选择一个示例。
Hourglass 是一个 HPE 网络,具有以下属性:
cf_hourglass_mpii_256_256_10.2G_2.0
- 描述:带有沙漏的姿势估计模型
- 输入尺寸:256x256
- 浮动操作:10.2G
- 任务:姿态估计
- 框架:咖啡
- 修剪:'不'
- 最新版本:Vitis AI 2.0
KV260 模型的预编译版本已使用 Vitis AI 2.0 和 DPU 配置进行编译B4096。
我们使用 DPU 配置B3136。caffe因此,必须使用相应 DPU 和正确的 Vitis AI 版本 1.3.0(Docker 映像:)的工作流重新编译沙漏模型xilinx/vitis-ai-cpu:1.3.411。
DPU 指纹和相应的arch.json文件可以在smartcam 文档中找到。
{
"fingerprint":"0x1000020F6014406"
}
新编译的文件模型可以保存在 KV260 上。
Vitis AI 库提供的测试应用程序 ( test_video_hourglass) 用于运行模型。为此,请使用此项目中提供的预构建文件或使用 KV260 主机 PC 上的交叉编译系统环境编译测试应用程序(遵循 Vitis AI说明)。
下载并解压 KV260 上的预构建文件。
wget https://github.com/Nunigan/HardwareAcceleratedPoseTracking/raw/main/prebuilt.tar.xz
tar -xf prebuilt.tar.xz
转到沙漏文件夹
cd prebuilt/hourglass/
来自相机接口的 GStreamer 字符串用作输入设备。使用以下命令,程序以两个线程运行。
./test_video_hourglass hourglass_kv.xmodel "mediasrcbin media-device=/dev/media0 v4l2src0::io-mode=dmabuf v4l2src0::stride-align=256 ! video/x-raw, width=256, height=256, format=NV12, framerate=30/1 ! videoconvert ! appsink" -t 2
沙漏以 30 fps 运行。请注意,限制因素是相机而不是神经网络。
葡萄籽油
该项目的主要部分是使用为传统 GPU 实现和 Tensorflow 设计的神经网络,并尝试在 FPGA 上运行它。
ICAIPose 是一个相当大的网络,具有大约 1100 万个可学习参数并103 GOps用于处理图像。
原始网络由以下层组成:
-
Conv2D -
PReLU activation function -
Concatenate -
UpSampling2D -
DepthwiseConv2D -
MaxPooling2D
对于 Vitis AI 的使用,必须检查 Vitis AI 是否支持神经网络的所有层(请参阅相应的用户指南)。
PReLU支持除激活函数之外的所有层。“Parametric ReLU”与函数非常相似Leaky ReLU(见下图),只是泄漏项是一个可学习的参数。Vitis AI 支持Leaky ReLU0.1 的固定泄漏项。
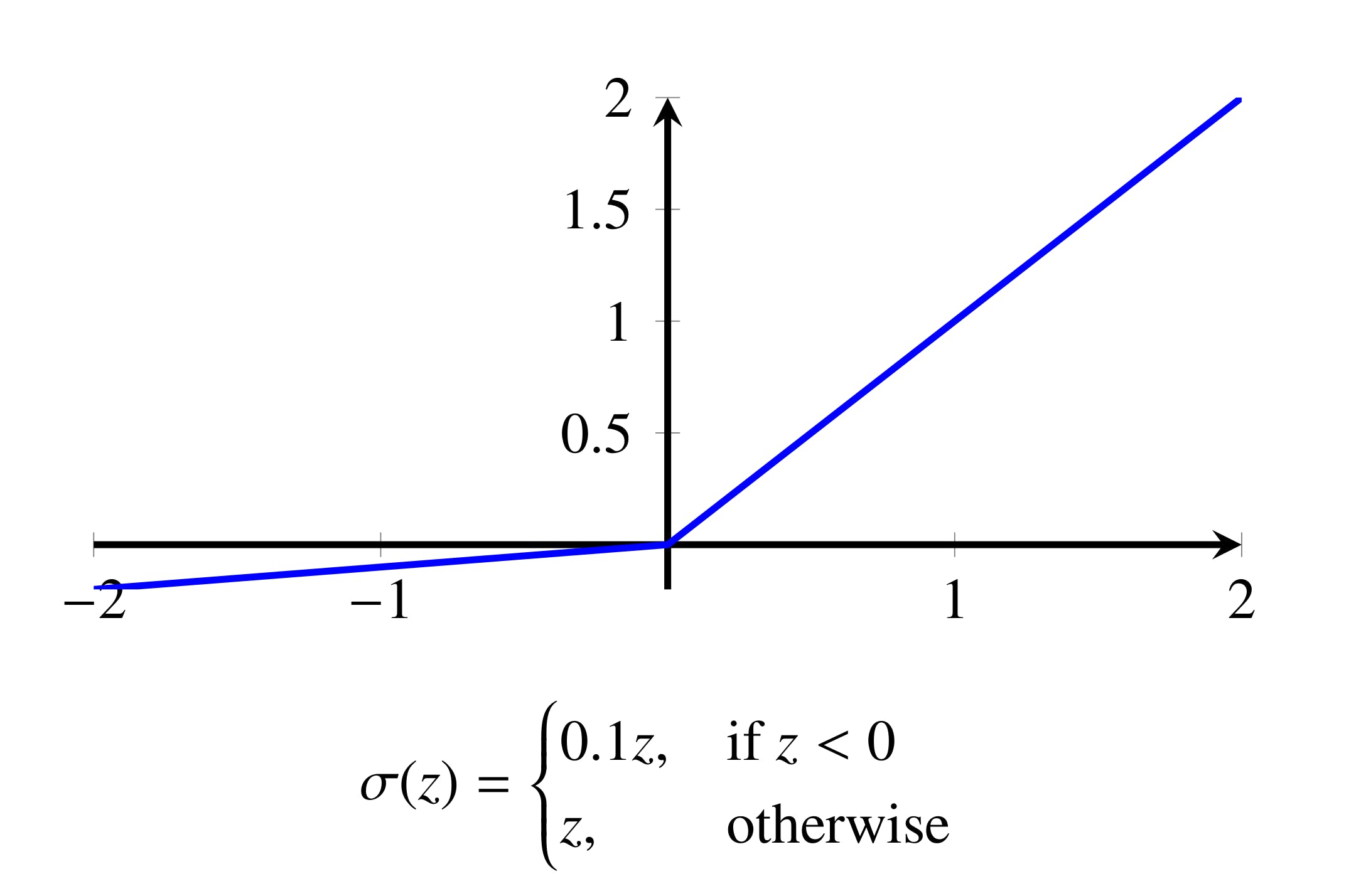
引入Leaky ReLU激活功能带来了一些挑战。
结果
了解网络在 FPGA 上运行的速度很有趣,但重要的是了解是否由于量化而损失了一些 HPE 性能。
吞吐量性能
-
ICAIPose (256x256, 103 GOps): 8 fps
在B3136DPU 和时钟频率为 的情况下300 MHz,给出了理论吞吐量940 GOps/s。
因此,结果在预期范围内(回想一下:103 GOps对于一张图像)。
作为比较,NVIDIA Jetson Xavier NX 比 KV260 更昂贵,并且具有显着更高的理论吞吐量(21 TOps),达到了 8 fps 的相同吞吐量。
人体姿势估计性能
该数据集提供了 2000 多张图像和相应的理想置信度图,用于测试 HPE 性能。
归一化置信度图的均方误差 (MSE) 是通过对每个像素之间的差异求平方和求和来计算的。下图显示了一个示例。左侧图像的均值是给定输入的 MSE。

我们现在可以比较量化网络和浮点网络之间的 MSE。作为附加信息,显示了具有PReLU激活功能的原始网络的 MSE。
所有图像的 MSE:
-
Float: 0.8109 -
Quantized INT8: 0.9332 -
PReLU: 0.9348
从PRelu到Leaky ReLU激活函数的变化甚至提高了网络性能。量化对 有影响MSE,但影响很小。量化的网络执行以及未量化的PReLU网络
结论
AMD-Xilinx 的 Vitis AI 框架经过广泛测试,显示出其优势和一些初期问题。即使 FPGA 板更便宜,也可以将目标设备从 GPU 更改为 FPGA,而不会损失显着的性能。Vitis AI 允许在没有 HDL 或 HLS 知识的情况下为 FPGA 设计高效的深度神经网络。
Kria KV260 Vision AI Starter Kit 是从 Vitis AI 开始的绝佳选择。提供的摄像头可以在 petalinux 环境中轻松使用。
参考
致谢
特别感谢ICAI和瑞士 VRM提供了经过培训的 ICAIpose 版本。
感谢微电子和嵌入式系统研究所作为学生项目的一部分支持这一挑战。
修订记录
- 2022 年 3 月 14 日 - 初始版本
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章





