
资料下载


如何使用Apache Spark 2.0
分享资料个
Spark 2.0中使用DataFrames和SQL的第一步
Spark 2.0开发的一个动机是让它可以触及更广泛的受众,特别是缺乏编程技能但可能非常熟悉SQL的数据分析师或业务分析师。因此,Spark 2.0现在比以往更易使用。在这部分,我将介绍如何使用Apache Spark 2.0。并将重点关注DataFrames作为新Dataset API的无类型版本。
到Spark 1.3,弹性分布式数据集(Resilient Distributed Dataset,RDD)一直是Spark中的主要抽象。RDD API是在Scala集合框架之后建模的,因此间接提供了Hadoop Map / Reduce熟悉的编程原语以及函数式编程(Map、Filter、Reduce)的常用编程原语。虽然RDD API比Map / Reduce范例更具表达性,但表达复杂查询仍然很繁琐,特别是对于来自典型数据分析背景的用户,他们可能熟悉SQL,或来自R/Python编程语言的数据框架。
Spark 1.3引入了DataFrames作为RDD顶部的一个新抽象。DataFrame是具有命名列的行集合,在R和Python相应包之后建模。
Spark 1.6看到了Dataset类作为DataFrame的类型化版本而引入。在Spark 2.0中,DataFrames实际上是Datasets的特殊版本,我们有type DataFrame = Dataset [Row],因此DataFrame和Dataset API是统一的。
表面上,DataFrame就像SQL表。Spark 2.0将这种关系提升到一个新水平:我们可以使用SQL来修改和查询DataSets和DataFrames。通过限制表达数量,有助于更好地优化。数据集也与Catalyst优化器良好集成,大大提高了Spark代码的执行速度。因此,新的开发应该利用DataFrames。
在本文中,我将重点介绍Spark 2.0中DataFrames的基本用法。我将尝试强调Dataset API和SQL间的相似性,以及如何使用SQL和Dataset API互换地查询数据。借由整个代码生成和Catalyst优化器,两个版本将编译相同高效的代码。
代码示例以Scala编程语言给出。我认为这样的代码最清晰,因为Spark本身就是用Scala编写的。
➤SparkSession
SparkSession类替换了Apache Spark 2.0中的SparkContext和SQLContext,并为Spark集群提供了唯一的入口点。
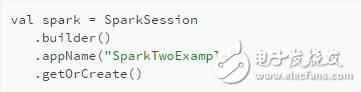
为了向后兼容,SparkSession对象包含SparkContext和SQLContext对象,见下文。当我们使用交互式Spark shell时,为我们创建一个名为spark的SparkSession对象。
➤创建DataFrames
DataFrame是具有命名列的表。最简单的DataFrame是使用SparkSession的range方法来创建:
使用show给我们一个DataFrame的表格表示,可以使用describe来获得数值属性概述。describe返回一个DataFrame:

声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章






下载排行榜
- 暂无相关数据

