
资料下载


×
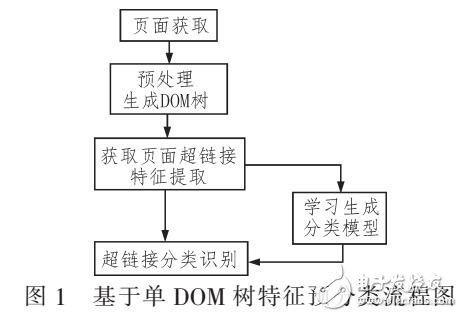
基于单DOM的自适应WEB信息抽取方法
消耗积分:0 |
格式:rar |
大小:0.73 MB |
2017-11-06
分享资料个
在传统的舆情中多为基于模板采集模式,基于减少人工维护的目的,文中提出一种基于单DOM树特征预分类的自适应Web信息抽取方法,分为链接预分类与信息抽取两个部分。链接预分类采用SVM分类算法,提取信息超链接在页面中的特征进行分类学习,再对分类结果进行同源的Web信息提取。实验表明,此方法预分类结果准确率可达94.48%.召回率为94.77%。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章




