
资料下载


利用Stencil建模及评估Intel IMCI vgather指令
分享资料个
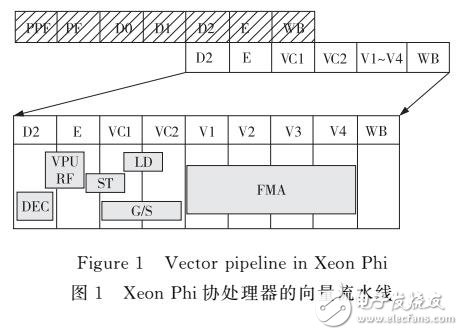
lntel Xeon Phi协处理器的指令集IMCI引入了硬件实现的vgather指令,旨在帮助512位SIMD寄存器访问非连续内存地址上的数据。然而实验结果显示,vgather很有可能成为应用在Xeon Phi协处理器上关键的性能瓶颈之一。基于以上结论,针对vgather的性能建模可以帮助用户深入地掌握和理解Xeon Phi协处理器的性能特性。在实验方法上,本文方法与现存的通过程序段内嵌入汇编代码进行数据统计不同,使用PAPI等性能分析工具直接收集硬件计数器的统计结果,作为模型的实验数据。本文的性能模型基于AGI事件次数和根据VPU DATA—READ次数估算得出的vgather所导致的平均延迟构建而成。该模型能够对Xeon Phi应用代码中由vgather所导致的总延迟进行预测。最终,为了验证模型预测的准确性,将该模型应用在三维7点stencil应用代码上,预测结果显示,vgather耗时占计算总耗时的约40%。再将该结果与利用int rinsics指令去除vgather后的计算耗时进行了对比验证,结果显示模型预测准确。基于上述结论,采用硬件计数器的统计结果在Xeon Phi协处理器上针对vgather枸建了性能模型。同时,通过与其他平台的vgather对比,认为该模型也可以应用在同样具备vgather的Intel CPU处理器平台上。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章





