
资料下载


×
K-Means算法改进及优化
消耗积分:2 |
格式:rar |
大小:0.92 MB |
2017-12-05
分享资料个
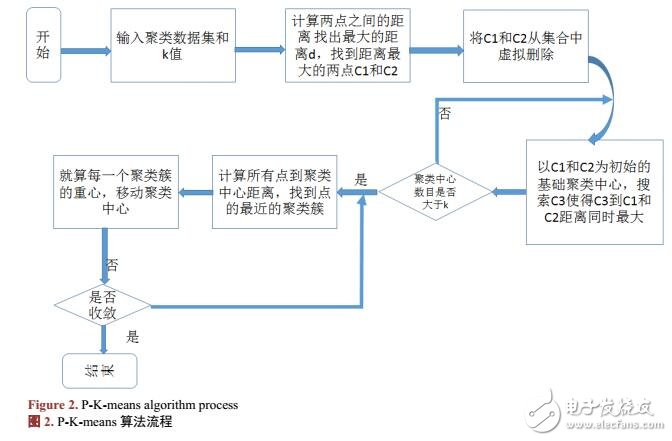
传统的k-means算法采用的是随机数初始化聚类中心的方法,这种方法的主要优点是能够快速的产生初始化的聚类中心,其主要缺点是初始化的聚类中心可能会同时出现在同一个类别中,导致迭代次数过多,甚至陷入局部最优出现错误的聚类结果。针对传统的k-means算法初始聚类中心的缺点,本文提出了p-K-means算法,该算法采用了数学几何距离的方法改进k-means算法中初始聚类中心分布不均匀的现象多个聚类中心出现在同一类簇中的现象,这种方法能避免k-means聚类算法聚类过程中陷入局部最优,另一方面降低了聚类过程中的反复迭代次数。本文通过实验的方式来对两个算法进行分析比较后发现改进的算法在收敛速度上优于传统k-means算法,也不容易陷入局部最优。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章


下载排行榜
- 暂无相关数据

