
资料下载


×
针对高维稀疏数据的可重叠子空间K-Means聚类算法
消耗积分:0 |
格式:pdf |
大小:1.83 MB |
2021-03-25
分享资料个
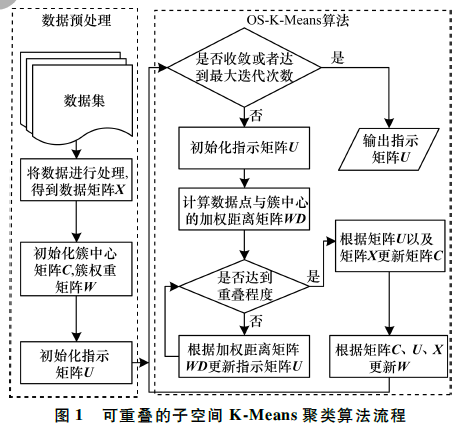
现有聚类算法面向高维稀疏数据时多数未考虑类簇可重叠和离群点的存在,导致聚类效果不理想。为此,提出一种可重叠子空间K- Means聚类算法。设计类簇子空间计算策略,在聚类过程中动态更新每个类簇的属性子空间并定义合理的约東函数指导聚类过程,从而实现类簇的可重叠性与离群点的控制。在此基础上定义合理的目标函数对传统K- Means算法进行修正,利用熵权约東分别计算每个类簇中各维度的权重,使用权重值标识不同类簇中维度的相对重要性,并加入控制重叠程度和离群值数量的参数。在人工数据集和真实数据集上的实验结果表明,该算法在NMI、F指标上均优于 EWKM Neo-k-means、OKM等子空间聚类算法,具有更好的聚类结果。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章



