
资料下载


×
基于Spark的矩阵分解并行化算法
消耗积分:3 |
格式:rar |
大小:0.56 MB |
2018-01-02
分享资料个
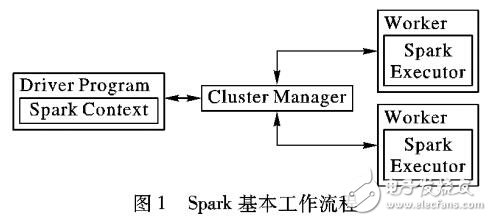
针对传统矩阵分解算法在处理海量数据信息时所面临的处理速度和计算资源的瓶颈问题,利用Spark在内存计算和迭代计算上的优势,提出了Spark框架下的矩阵分解并行化算法。首先,依据历史数据矩阵初始化用户因子矩阵和项目因子矩阵;其次,迭代更新因子矩阵,将迭代结果置于内存中作为下次迭代的输入;最后,迭代结束时得到矩阵推荐模型。通过在GroupLens网站上提供的MovieLens数据集上的实验结果表明,加速(Speedup)值达到了线性的结果,该算法可以提高协同过滤推荐算法在大数据规模下的执行效率。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章


下载排行榜
- 暂无相关数据

