
资料下载


×
改进的DBSCAN聚类算法在Spark平台上的应用
消耗积分:0 |
格式:rar |
大小:1.92 MB |
2021-04-26
分享资料个
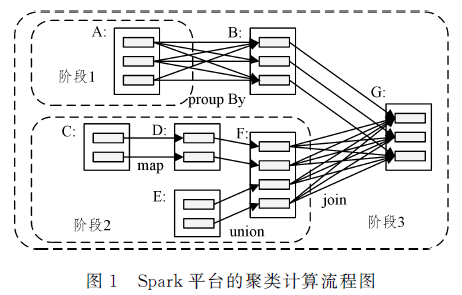
针对 DBSCAN( Density- Based Spatial Clustering of Applications with Noise)聚类算法内存占用率较高的问题,文中将改进的 DBSCAN聚类算法与 Spark平台并行聚类计算理论相结合,对海量数据采用分而治之的办法进行聚类处理,大幅减小了算法对内存的占用率。实验仿真结果表明,所提出的并行计算方法能够有效缓解内存不足的问题,并且该方法也能够用来评价 DBSCAN聚类算法在Hadoφ平台下的聚类分析效果,还能对两种聚类方法进行对比分析,从而获得较好的计算性能;且比在Hado平台上的计算加速度提高了24%左右,因此可以用以评价 DBSCAN聚类算法在聚类处理方面的优劣。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章



