
资料下载


×
面向压缩生物基因数据的查询方法
消耗积分:3 |
格式:rar |
大小:1.64 MB |
2018-01-12
分享资料个
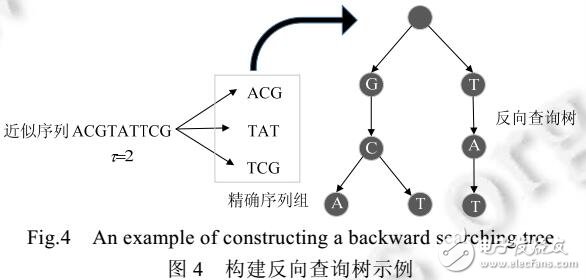
随着下一代、第三代等测序技术的快速发展,DNA等生物序列数据快速增长.如何高效地处理这些大数据是目前所面临的一个挑战.研究发现,这些生物序列数据尽管很大,但是不同数据之间具有很高的相似性.因此可以通过保存这些基因串同一个基准序列之间的差异来减少存储的代价.最新的研究发现,可以在这些压缩的数据上直接进行查询,而不需要解压缩.研究的目标是进一步提高索引和查询的可伸缩性,从而满足日益增长的大数据需要.首先在现有方法的基础上,对基准序列进行了压缩存储,基于该压缩数据,提出了一系列优化查询方法以高效地支持任意长度序列的精确和近似查询.在此基础上,进一步对原有方法进行改进,利用并行计算来提高对大数据的查询效率.最后,实验研究展示了所提方法的高效性.
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章



下载排行榜
- 暂无相关数据

