
资料下载


如何使用PU学习进行建议语句分类的方法说明
分享资料个
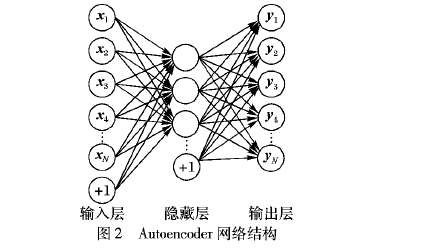
建议挖掘作为一项新兴研究任务,具有重要的应用价值。针对传统建议语句分类方法所存在的规则复杂、标注工作量大、特征维度高、数据稀疏等问题,提出一种基于PU学习的建议语句分类方法。首先,使用简单规则从无标注评论集合中选择建议语句的正例集合;然后,为了降低特征维度,缓解数据稀疏性,在自编码神经网络( Autoencoder)特征空间中使用Spy技术划分可靠反例集合;最后,利用正例集合和可靠反例集合来训练多层感知机(MLP)对剩余的无标注样例进行分类。该方法在中文数据集上的F1值和准确率值分别达到81. 98%和82. 67% ,实验结果表明,该方法能够有效地对建议语句进行分类,且不需要对数据进行人工标注。
随着互联网的快速发展,网络上出现了海量的用户评论,人们不仅会在评论中传达积极或消极的情绪,有时也会对产品、服务等提出相应的建议。例如,在“希望三星手机能支持谷歌应用商店”这条评论中虽然并未包含情感极性,但明确提出了对产品功能的改进建议。这类建议信息可以帮助厂家有效地提升产品质量,也有助于商家有针对性地制定销售策略,具有重要的应用价值,建议挖掘”研究因此应运而生。
进行建议挖掘,首先需要对建议语句进行分类,即将评论语句分为建议语句或非建议语句。但由于人们对建议的判定存在比较大的主观性,导致建议语句的定义难以取得-致,这给语料标注和问题定义带来了很多困难“。本文采用和文献[1]类似的方案,将明确表达了期望或提出改进意见的语句定义为建议语句。目前,建议挖掘研究l2-71虽然已经取得了一定的进展,但还存在以下问题:- -方面,已有研究大多是在英文语料上开展的,在中文语料上的相关研究很少,而中文环境和英语环境中的网络文化和建议语句的表达方式存在较大差异,因此需要深入研究中文环境下的建议语句分类方法。另- -方面,在已有研究中,用于建议语句分类的方法主要有规则方法[-31和有监督机器学习方法[4-7]。规则方法通过手工制定的规则来进行建议挖掘,需要提前建立复杂的规则模板,人工干预较多。而有监督机器学习方法虽然模型的精度较高,但模型训练过程中需要大量人工标注语料,标注工作量大,代价昂贵,并面临特征维度高、数据稀疏等问题。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章





