
资料下载


使用Tensorflow的Raspberry Pi Covid口罩检测器
杨平
分享资料个
当我们开始处于封锁状态时,我有很多时间思考我可以做的项目,这些项目将涉及我对机器学习和硬件黑客的兴趣。我认为可以监控出口点(入口和出口)的小型设备可以自动识别符合口罩要求的人。这可能是一种有趣的方式,可以让技术解决在试图保护人们安全的同时发生的一些复杂的人际互动。
我决定创建一个“Covid Mask Detector”,它将使用一个小型便宜的 Raspberry Pi 和一个定制的对象检测模型,该模型在戴口罩和不戴口罩的脸上进行训练。
机器学习模型
为了在 TensorFlow 中创建机器学习模型,我首先需要收集大量有面孔的图像,并对戴口罩和不戴口罩的人进行标注。为此,我需要从收集大量面部图像开始。
收集图像
为了协助收集面部图像,我编写了一个 Nodejs 脚本,该脚本将使用 Google Images 作为其来源并将搜索参数传递给该服务,然后下载最大版本的结果。该代码可在此处获得:
https://github.com/contractorwolf/googleimagedownloader
要使用 Nodejs 脚本,只需转到它所在的文件夹并首先运行npm install (安装 axios 和 fs),然后像这样运行脚本:
> node getimages covid masks
上面的命令将下载与“covid masks”相关的图像。我用几个不同的搜索参数收集图像,以确保我收集的是各种种族/性别/年龄/风格的面孔图像。我在搜索参数上花了很多时间(不仅仅是上面那个)。在识别人脸以及识别医用口罩和女仆/定制口罩时,我想尽可能地消除偏见。
在我收集了各种带有面具和没有面具的图像后,我仔细检查并删除了对模型训练没有帮助的所有图像。然后我移动并调整图像大小以使它们统一(自动执行这些操作的脚本也在回购协议中)。完成这些任务后,我需要对图像进行注释并确定每张图像中人脸的位置,以及确定人脸是否戴着面具。
注释图像
为了注释或“标记”图像,我使用了名为LabelImg(直接下载)的软件,该软件是开源的,已记录在LabelImg 的 Github页面上。该软件为每个图像创建一个 XML 文件,为每个图像定义机器学习“标签”(遮罩或不遮罩)以及面部边界框(面部在图像上的位置)。注释一千张口罩和没有口罩的图像的过程需要一段时间,但我知道准确性与准确收集和标记图像所花费的时间直接相关。
在收集和注释图像后,必须将它们分成训练文件夹和测试文件夹,比例为 80/20。如果您想查看到目前为止的过程输出,可以下载生成的文件夹:
测试图像和注释 XML 文件:
https://github.com/contractorwolf/coronavirus-mask-detection/blob/master/images/test.zip
测试图像和注释 XML 文件:
https://github.com/contractorwolf/coronavirus-mask-detection/blob/master/images/train.zip
使用 Google Colab 训练模型
在我获得生成机器学习模型所需的图像后,该模型可以识别戴/不戴口罩之间的区别,我必须编写代码来生成模型。我决定修改我发现的一些用Tensorflow编写的其他示例。我最初尝试使用我的显卡在我的个人台式机上执行此操作,但遇到了问题,所以我决定尝试使用 Google 的 Colab,这是一个 Web 界面,用于编写可以在 Google 的 GPU(或 TPU!)上免费运行的机器学习笔记本。
我写了笔记本来使用上面定义的图像,并试图记录每一步发生的事情:
https://colab.research.google.com/drive/1uEkP5j7KM9eSkCUtUyauy7-Dyd5XAY6e?usp=sharing
Colab使用预训练的MobileNet Coco模型,然后使用上面创建的图像重新训练最后一步,使图像模型专门识别戴面具和不戴面具的人脸。以下是 Colab 中记录的主要步骤:
- 安装所需的 Tensorflow 版本
- 设置对象检测项目
- 下载 Coco 模型
- 下载需要的图片
- 火车模型
- 测试模型
- 为树莓派创建文件
- 在 Raspberry Pi 上为 TPU 创建文件
该过程需要一些时间,您需要确保阅读并运行每个块并查看输出。如果您对 Colab 或代码或该项目中的任何内容有任何疑问,请随时将它们留在下面,我会尽力回答。
硬件
硬件基本上是带有Google Coral TPU 的Raspberry Pi (用于更快的推理)。我添加了 Armor Casing(用于外观和设备保护)和 Adafruit Mini PiTFT 作为用户界面,以便设备无需插入显示器即可提供基本反馈。
谷歌珊瑚 TPU
Google Coral TPU通过 USB 连接,能够处理进行机器学习推理(预测)时所需的大量矩阵数学运算。使用 TPU(模型设置为使用 TPU 和代码集以利用 TPU)允许模型能够以每秒 15 帧的速度进行预测。如果没有 TPU,Raspberry Pi 只能以大约每秒 3 帧的速度处理 USB 摄像头图像的预测。我的 Github Repo 中的默认代码设置为使用 TPU,但您会看到注释掉的部分,这些部分将允许它在没有 TPU 的情况下仅在 Raspberry Pi 上运行(尽管速度较慢)。
TFT基本接口
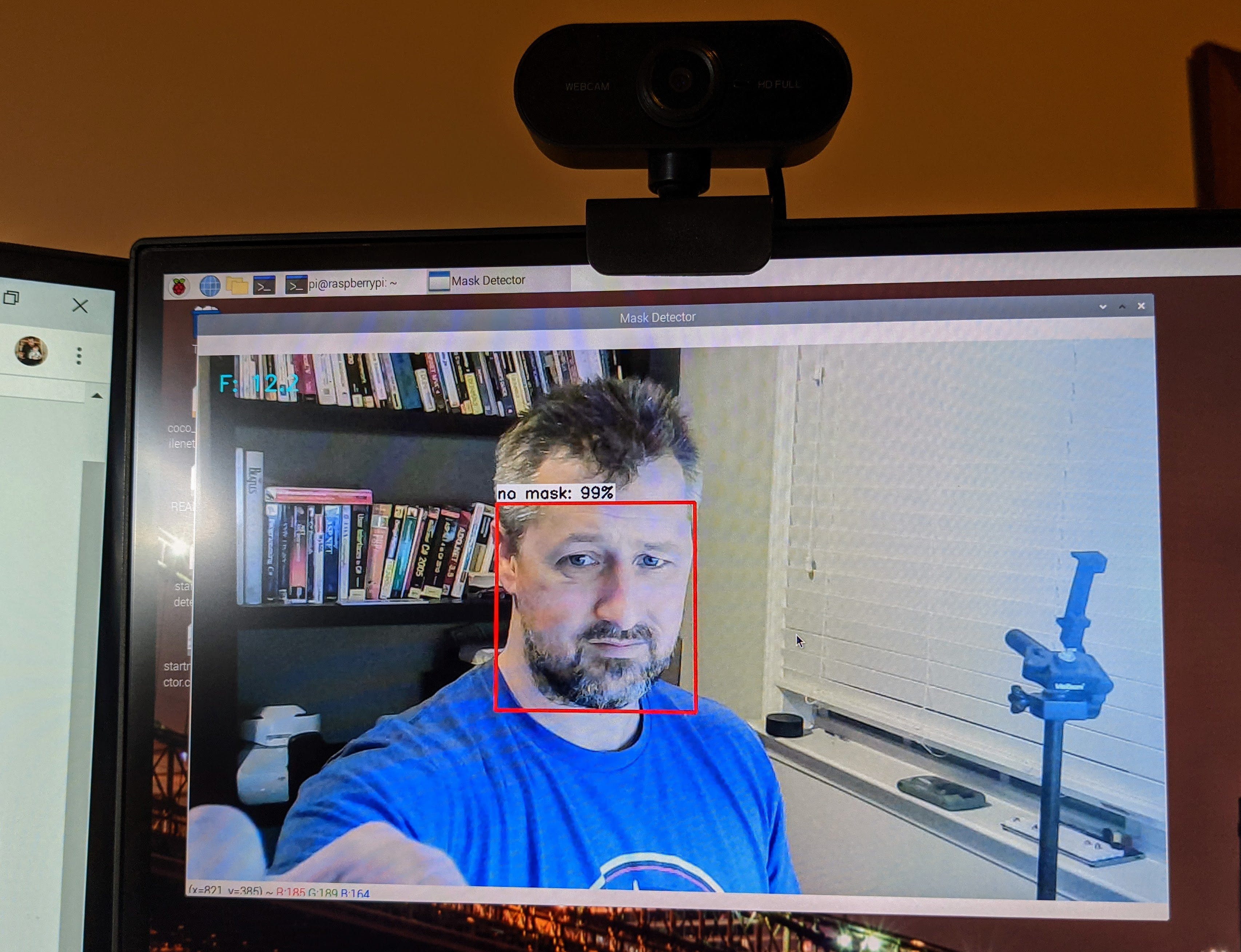
我使用 Adafruit MiniPiTFT 作为该项目的主要外部接口。目标是提供机器学习模型完成的评估以及一些其他基本参数的外部通知。右图中显示的框表示USB摄像头看到的图像是否是“戴着COVID口罩”(下图绿色框)

当设备在范围内看到一个人时,它会放置一个彩色框来勾勒出他们的脸。彩色框表示他们是否戴着口罩。如果它看到如下图所示的面具,它将在他们的脸上用绿色框表示,并在 MiniPiTFT 上闪烁一个绿色框,如上图所示。
。

如果正在使用显示器,还会在脸部周围显示一个红色框,如下图所示。
基本的想法是,该设备可以独立于插入显示器或屏幕而工作,只需依靠。其他显示参数如下:
- N :(无掩码,红色)具有估计的确定性
- 或M :(看到面具,绿色)估计确定性
- S :屏幕中图像的大小百分比F :估计正在进行的每秒帧数
- T : CPU 温度
定制电缆
我最初只是买了我能找到的最短的双直角 USB 数据线,然后将它绑在外壳上,但我认为我可以做得更好,所以我一直在改进。

最后我只是从上面剪下电缆并重新连接两端,所以它看起来像这样:

USB 实际上只有 4 根线,它们采用颜色编码,因此过程很简单。我实际上也有一个小的拉链领带,以承受大部分的弯曲压力并防止它们断裂。最后看起来像这样安装:

软件
Raspberry Pi 可以启动到 python 程序,该程序将监控 USB 网络摄像头并运行一个
https://github.com/contractorwolf/rpi-tensorflow-mask-detector/blob/master/maskclassifier.py
从基本 tensorflow 对象检测示例修改而来,但使用经过重新训练的模型的修改版本以仅识别“面具”或“无面具”面孔。还修改为使用 TPU 进行快速推理并将数据输出到迷你 PiTFT 屏幕。
代码启动并开始处理来自它可以识别的第一个 USB 网络摄像头的图像。图像被加载,机器学习模型尝试对其是否看到面具进行分类。它还会在图像中看到的每张可识别面孔周围绘制一个边界框,并对最大的一张是否戴着口罩进行分类。 PiTFT 还用于显示有关图像的计算。如果您没有 TFT 或不需要任何额外的显示器,可以简单地注释掉该代码。如果您的模型不是为 TPU 处理构建的,也可以删除 TPU 代码,但它会以低得多的帧速率进行处理。当我使用非 TPU 模型在 RPi 4 上运行它时,我看到帧率为 ~2-3FPS,而 TPU 允许我以~15FPS 的速度处理。
如果您有任何其他问题,只需将它们放在评论中,我会尽可能提供帮助。感谢您的观看!
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章




