
资料下载


分形生成FPGA设计练习
张国厚
分享资料个
描述
注意:模糊和伪像是手机摄像头伪像,不存在于生成的电子 VGA 信号中)
分形生成是一种流行的 FPGA 设计练习。例如,斯坦福大学在 2002 年就已将其用作实验室作业。一定是在那个时候,我在某个交易会上看到了类似的演示,并且从那时起就渴望尝试一下。
好吧,我最终解决了它。
花了很长时间。
动机
FPGA 业余项目增加了一个独特的设计挑战:它需要始终充满乐趣。
有时,通往终点线的路变得笔直、明显且乏味。就像徒步旅行与通勤一样,这不仅仅是以最有效的方式从 A 地到达 B 地……所以你提出了一个新的想法,让它再次变得有趣。冲洗并重复。
概述
“乐趣因素驱动的需求管理”最终沿着这些路线发展:
- 实时计算
- 60 Hz 时的全高清分辨率 (1920x1080)
- 明智地使用 FPGA:最终实现接近每个时钟周期每个乘法器一个操作。在 USB 总线功率预算约为 2 瓦的 35 尺寸 Artix 上,这是每秒 180 亿次乘法运算。
- 执行动态资源分配。分形算法有些不寻常,因为所需的迭代次数因点而异。与简单地设置固定的迭代次数相比,复杂度大大增加(一个时钟周期内可能出现随机数量的结果,结果是无序的)但性能也是如此。
- 限制为 18 位乘法,因为它是 Xilinx 6/7 系列 DSP48 块的原生宽度。为更高分辨率增加内部位宽很简单,但资源使用量猛增。
- (合理地)独立于供应商。我决定使用开源“J1B”软核 CPU,而不是 Microblaze MCS,后者会非常简单。
- 我决定使用我自己的简单编译器/汇编器“forthytwo.exe”,而不是用于 J1B 的原始“gforth”工具链,它在整个过程中得到了清理。
-
CPU 上对性能无关紧要的代码的浮点数学运算。
“因为当你凝视兔子洞时,兔子洞也在凝视你”。
我自己的“最小”浮点数实现并没有像 IEEE 754 那样精致或安全,但它很小并且到目前为止做得很好。 - 普通 UART 上的 CPU 引导加载程序(意味着没有专有的 Xilinx JTAG)。包含的引导加载程序实现了强大的同步和高效的二进制文件上传。
- 没有深奥的工具,能够在 Windows 上运行(同样,Linux 会更容易)。在干净的 Windows PC 上,可以通过安装 MinGW(开发人员设置)、Vivado 和 Verilator 来设置构建系统。有关后者,请参阅我的安装说明。将例如 Teraterm 与引导加载程序一起使用。
- 包含电池的项目,旨在通过删除不需要的内容来重用(也许这更多是在微控制器方面,因为分形部分是针对特定问题的)
就绪/有效的设计模式说明
计算引擎在很大程度上依赖于有效/就绪的握手范例,该范例在整个链中一致使用。
在这里,它非常重要,原因很简单:分形发生器的 200 MHz 时钟速率小于 VGA 像素速率的两倍。任何需要空闲时钟周期来恢复的“次优”握手方案都会破坏体系结构。
就绪/有效组合路径问题
在典型的处理块中,数据通过一系列寄存器以锁步方式移动。当通过就绪/有效接口级联任意数量的此类块时,“就绪”信号形成从链的末端到开始的组合路径。这会使时序收敛变得困难或不可能。当考虑处理链末端发出“未准备好”(接受数据)信号时会发生什么时,问题就很明显了:整个管道长度上的数据无处可去,因此整个链必须在一个时钟周期。
解决方案是使用 FIFO 将链分成多个段(2 个插槽就足够了)。有一个问题:我可以设计一个“优化的”FIFO,即使数据已满,只要在同一时钟周期内从输出中取出一个元素,它也会接受数据。这种“优化”将准确地引入 FIFO 应该打破的组合路径,因此它对于解耦组合链是无用的。换句话说,FIFO的输入端不能组合使用输出端的“就绪”信号。
就绪/有效流控
也许这是显而易见的,但就绪/有效链中的数据流可以在任何时候停止,只需插入一个将有效和就绪信号都强制为零(未断言)的块即可。该块可以是组合的并且可以取决于观察到的数据值。该模式用于阻止计算引擎运行在监视器电子束之前太远。
RTL实现
时钟域
共有三个时钟域:
- 200 MHz 的计算引擎(大部分设计)。这可以推得更高,但会使设计更难处理。现在,没有理由这样做,芯片已经很热了。
- 像素频率为 148.5 MHz 的 VGA 监视器信号
- J1B CPU 在 100 MHz,因为它的关键路径对于 200 MHz 操作来说太慢了。
数据流
注:图中名称对应Verilog实现
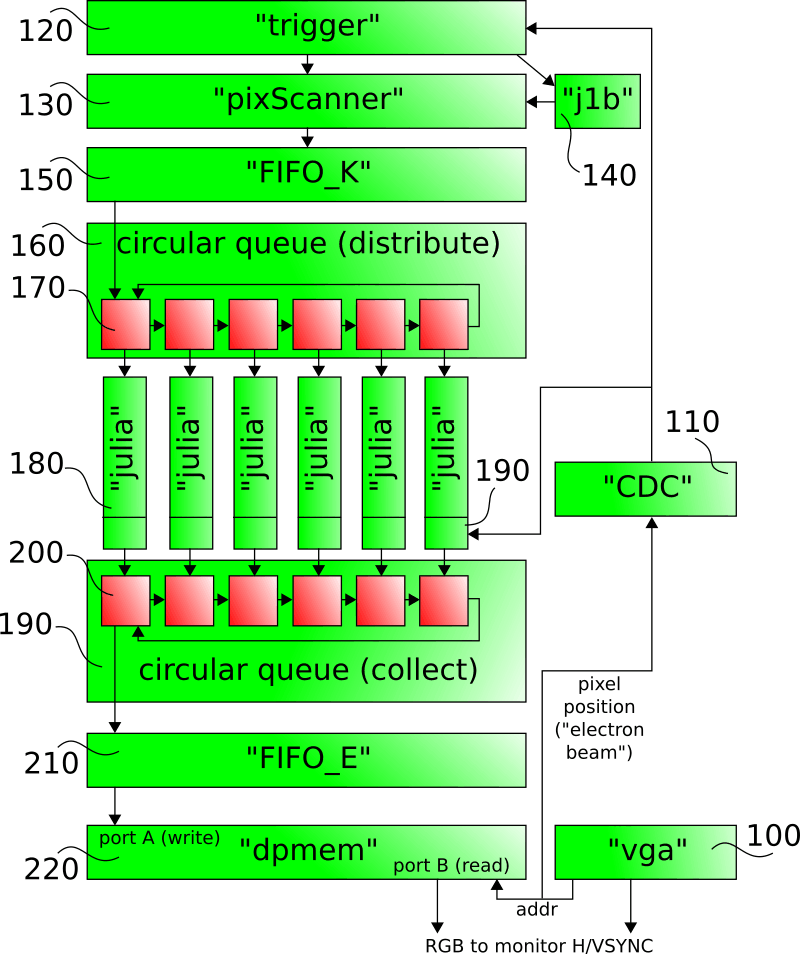
块“vga” 100创建 VGA 监视器时序。它的输出之一是当前在电子束下的像素数。
像素位置经由格雷编码通过时钟域交叉点110进入“触发”块120 。这里,当像素位置返回到零时,检测到新帧的开始。这在最后一个可见像素已被发送到显示器之后立即发生,因此前沿/VSYNC/后沿时间间隔可用于预先计算图像数据,直到缓冲器RAM 220的容量。
新帧开始的检测触发以下“pixScanner” 130 。该块已经从 CPU 140接收到分形坐标并使用两对增量逐行扫描它们:第一对增量 X/Y 用于电子束向右移动(列),第二对用于向下移动(行)。使用适当的增量,图片可以旋转任何角度。
该块保留一个帧计数器,CPU 140会对其进行轮询,以在先前的帧坐标已存储后立即开始计算下一帧坐标。
生成的像素坐标向前移动到FIFO 150 。这只是为了解耦组合接受/就绪路径。它不会提高吞吐量,因为像素扫描仪已经能够在每个时钟周期生成一个输出。
“像素坐标”由分形空间中的 X 和 Y 位置以及线性像素位置形成,相当于它在 vga 块100中的对应位置。后者是必需的,因为结果需要重新排序。
像素坐标现在移动到循环分配队列160中。其目的是为并行“julia”(分形)计算引擎180提供像素坐标。如果一个计算引擎准备好接受一项新工作,该值将从队列中删除,否则它将右移通过插槽170并最终循环回到队列的头部。
当没有数据循环时,队列160将只接受来自 FIFO_K 150的新输入。ready/valid 协议的使用使得此功能的实现相对简单。
计算引擎180将迭代 Mandelbrot 集算法(“转义时间”算法,参见维基百科:https://en.wikipedia.org/wiki/Mandelbrot_set)。
使用默认设置(很容易更改),实现使用 30 个“julia”引擎180 。它们中的每一个都由 12 个管道级别组成。换句话说,每个引擎一次处理多达 12 个独立的计算。每个“julia”引擎执行三个并行乘法(xx、yy、xy),总共使用 90 个乘法器,每个周期在满负载下执行一次运算。
由于下游 RAM 220中的缓冲空间相当有限——远小于全帧——必须防止计算引擎180在电子束位置之前运行太远。因此,流量控制机制190内置于计算引擎中。它根据电子束检查每个条目的像素编号,如果它会导致 RAM 220中的循环溢出,则阻止它离开计算引擎180 。如果拒绝退出,该值将继续通过计算引擎进行虚拟迭代。时钟域穿越110相对于实际图像生成将像素位置延迟几个时钟周期,因此流量控制将始终(保守地)滞后于几个像素。
类似于循环分发队列160 ,结果被收集到循环收集队列190中。如果槽200为空,它将接受来自计算引擎180的结果,否则计算引擎将继续对结果进行虚拟迭代。
来自收集队列190的退出数据项移动到FIFO_E 210 ,然后移动到双端口存储器220 。这个 FIFO 不再是绝对必要的:因为双端口 ram 220总是准备好接受数据,它可以用更便宜的寄存器代替。
双端口存储器220在其第二端口上由来自“vga”块100的电子束位置索引。dp-memory 实现数据到 VGA 像素时钟域的交叉。RAM 的输出连同 HSYNC 和 VSYNC 信号一起最终转发到监视器输出。
虽然图中未显示,但可通过连接到 CPU 的 IO 端口的寄存器访问按钮和 LED。
“julia”计算引擎
文档待续……请暂时参考代码(“julia”模块)。
运行演示
- 获取 CMOD A7-35 板(或修改项目)。该设计对于 15 尺寸的变体来说太大了。
- 上传预构建的“最终”比特流
- CPU 运行时,这两个按钮将分别切换红色和绿色 LED。
- 使用跨接电缆将显示器连接到 DIL48 插座
默认引出线
- 引脚 1:红色(照片中的红线)
- 引脚 2:绿色(照片中的绿线)
- 引脚 3:蓝色(照片中的蓝线)
- 引脚 4:HSYNC(照片中的黄线)
- 引脚 5:VSYNC(照片中的橙色线)
- pin 25 or PMOD header: common GND (照片中的黑线)
请注意:3.3 V 不符合 VGA 模拟信号的规格。我从来没有遇到过在相当多的显示器/投影仪上直接接线的问题,但请务必使用常识。



。
构建项目
请使用 Vivado 2019.2。免费的“网络版”就足够了。
要重建比特流,请从顶级目录运行
- make forthytwo:构建编译器
然后...
...对于“引导加载程序”版本(如果您想编辑微控制器代码)
- 制作分形(仍然来自顶级目录)。这将创建包含 J1B rom 内容的 main.v 文件
- 在 fractalsProject/CMODA7_fractalDemo 中打开 Vivado 工程
- 生成比特流
- 上传比特流
- 将 teraterm 连接到串行端口。测试按键是否回显“x”=> 引导加载程序正常运行
- 通过 Teraterm 的“发送文件”功能以二进制模式发送“fractalsProject/out/main.bootBin”(!!)。请注意,“main.bootBin”是在启用或禁用引导加载程序的情况下编译的并不重要。
- 正确上传打印一个字母“1”,按钮将点亮 LED。只有现在 VGA 信号存在
...对于“发布”版本(在 FPGA 比特流中带有微控制器代码)
- 根据第一行中的说明编辑 bootloader/bootloader.txt(注释掉第一个 BRA: 并取消注释第二个 BRA:)
- 从顶层:制作分形
- 从 Vivado 构建比特流
- 程序比特流(或写入闪存)。一旦黄色“prog ready”LED 亮起,红色/绿色 LED 应响应按钮按下并且 VGA 信号存在。
Git 仓库
- 在这里(用于在线阅读。请克隆顶级“forthytwo”repo 并从顶级使用“make”。
执照
请注意,J1B CPU 仍保留其原始 BSD 3-clause 许可,而我自己的文件是根据 MIT 许可发布的。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章






